 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Fine-Grained Negotiation Tactics of Humans and LLMs in Diplomacy
Dec 20, 2025The study of negotiation styles dates back to Aristotle's ethos-pathos-logos rhetoric. Prior efforts primarily studied the success of negotiation agents. Here, we shift the focus towards the styles of negotiation strategies. Our focus is the strategic dialogue board game Diplomacy, which affords rich natural language negotiation and measures of game success. We used LLM-as-a-judge to annotate a large human-human set of Diplomacy games for fine-grained negotiation tactics from a sociologically-grounded taxonomy. Using a combination of the It Takes Two and WebDiplomacy datasets, we demonstrate the reliability of our LLM-as-a-Judge framework and show strong correlations between negotiation features and success in the Diplomacy setting. Lastly, we investigate the differences between LLM and human negotiation strategies and show that fine-tuning can steer LLM agents toward more human-like negotiation behaviors.
Evaluating LLM Agent Collusion in Double Auctions
Jul 02, 2025Large language models (LLMs) have demonstrated impressive capabilities as autonomous agents with rapidly expanding applications in various domains. As these agents increasingly engage in socioeconomic interactions, identifying their potential for undesirable behavior becomes essential. In this work, we examine scenarios where they can choose to collude, defined as secretive cooperation that harms another party. To systematically study this, we investigate the behavior of LLM agents acting as sellers in simulated continuous double auction markets. Through a series of controlled experiments, we analyze how parameters such as the ability to communicate, choice of model, and presence of environmental pressures affect the stability and emergence of seller collusion. We find that direct seller communication increases collusive tendencies, the propensity to collude varies across models, and environmental pressures, such as oversight and urgency from authority figures, influence collusive behavior. Our findings highlight important economic and ethical considerations for the deployment of LLM-based market agents.
Dynamic Coalition Structure Detection in Natural Language-based Interactions
Feb 22, 2025In strategic multi-agent sequential interactions, detecting dynamic coalition structures is crucial for understanding how self-interested agents coordinate to influence outcomes. However, natural-language-based interactions introduce unique challenges to coalition detection due to ambiguity over intents and difficulty in modeling players' subjective perspectives. We propose a new method that leverages recent advancements in large language models and game theory to predict dynamic multilateral coalition formation in Diplomacy, a strategic multi-agent game where agents negotiate coalitions using natural language. The method consists of two stages. The first stage extracts the set of agreements discussed by two agents in their private dialogue, by combining a parsing-based filtering function with a fine-tuned language model trained to predict player intents. In the second stage, we define a new metric using the concept of subjective rationalizability from hypergame theory to evaluate the expected value of an agreement for each player. We then compute this metric for each agreement identified in the first stage by assessing the strategic value of the agreement for both players and taking into account the subjective belief of one player that the second player would honor the agreement. We demonstrate that our method effectively detects potential coalition structures in online Diplomacy gameplay by assigning high values to agreements likely to be honored and low values to those likely to be violated. The proposed method provides foundational insights into coalition formation in multi-agent environments with language-based negotiation and offers key directions for future research on the analysis of complex natural language-based interactions between agents.
BIG5-CHAT: Shaping LLM Personalities Through Training on Human-Grounded Data
Oct 21, 2024

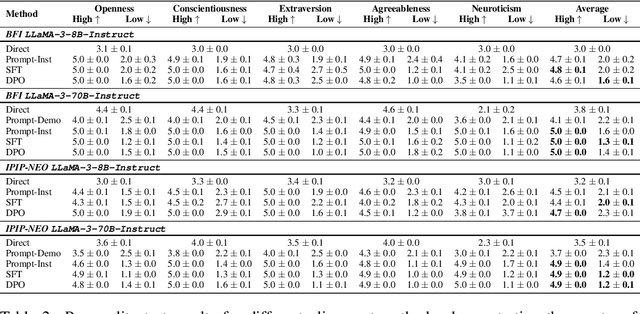

In this work, we tackle the challenge of embedding realistic human personality traits into LLMs. Previous approaches have primarily focused on prompt-based methods that describe the behavior associated with the desired personality traits, suffering from realism and validity issues. To address these limitations, we introduce BIG5-CHAT, a large-scale dataset containing 100,000 dialogues designed to ground models in how humans express their personality in text. Leveraging this dataset, we explore Supervised Fine-Tuning and Direct Preference Optimization as training-based methods to align LLMs more naturally with human personality patterns. Our methods outperform prompting on personality assessments such as BFI and IPIP-NEO, with trait correlations more closely matching human data. Furthermore, our experiments reveal that models trained to exhibit higher conscientiousness, higher agreeableness, lower extraversion, and lower neuroticism display better performance on reasoning tasks, aligning with psychological findings on how these traits impact human cognitive performance. To our knowledge, this work is the first comprehensive study to demonstrate how training-based methods can shape LLM personalities through learning from real human behaviors.
Evaluating Large Language Model Biases in Persona-Steered Generation
May 30, 2024



The task of persona-steered text generation requires large language models (LLMs) to generate text that reflects the distribution of views that an individual fitting a persona could have. People have multifaceted personas, but prior work on bias in LLM-generated opinions has only explored multiple-choice settings or one-dimensional personas. We define an incongruous persona as a persona with multiple traits where one trait makes its other traits less likely in human survey data, e.g. political liberals who support increased military spending. We find that LLMs are 9.7% less steerable towards incongruous personas than congruous ones, sometimes generating the stereotypical stance associated with its demographic rather than the target stance. Models that we evaluate that are fine-tuned with Reinforcement Learning from Human Feedback (RLHF) are more steerable, especially towards stances associated with political liberals and women, but present significantly less diverse views of personas. We also find variance in LLM steerability that cannot be predicted from multiple-choice opinion evaluation. Our results show the importance of evaluating models in open-ended text generation, as it can surface new LLM opinion biases. Moreover, such a setup can shed light on our ability to steer models toward a richer and more diverse range of viewpoints.
Combating Adversarial Attacks with Multi-Agent Debate
Jan 11, 2024While state-of-the-art language models have achieved impressive results, they remain susceptible to inference-time adversarial attacks, such as adversarial prompts generated by red teams arXiv:2209.07858. One approach proposed to improve the general quality of language model generations is multi-agent debate, where language models self-evaluate through discussion and feedback arXiv:2305.14325. We implement multi-agent debate between current state-of-the-art language models and evaluate models' susceptibility to red team attacks in both single- and multi-agent settings. We find that multi-agent debate can reduce model toxicity when jailbroken or less capable models are forced to debate with non-jailbroken or more capable models. We also find marginal improvements through the general usage of multi-agent interactions. We further perform adversarial prompt content classification via embedding clustering, and analyze the susceptibility of different models to different types of attack topics.
Computational Language Acquisition with Theory of Mind
Mar 02, 2023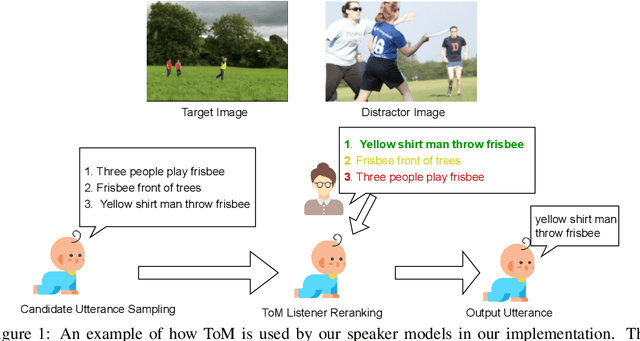


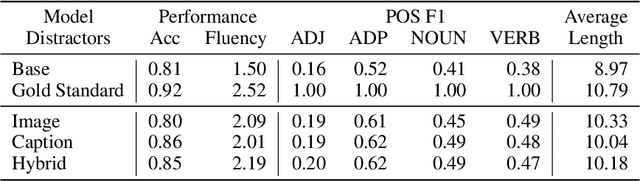
Unlike current state-of-the-art language models, young children actively acquire language through interactions with their surrounding environment and caretakers. One mechanism that has been argued to be critical to language learning is the ability to infer the mental states of other agents in social environments, coined Theory of Mind (ToM) by Premack & Woodruff (1978). Drawing inspiration from the modern operationalized versions of ToM implemented in Rabinowitz et al. (2018) and Zhu et al. (2021), we build language-learning agents equipped with ToM, and measure its effects on the learning process. We model ToM by giving the speaker agent an internal listener model that is trained alongside the speaker and used to rerank potential utterances. We experiment with varying task difficulty, hypothesizing that models will acquire more complex language to adapt to stronger environmental pressures. We find that training speakers with a highly weighted ToM listener component leads to performance gains in our image referential game setting. We also find some evidence that increasing task difficulty in the training process results in more fluent and precise utterances in evaluation. This suggests the potential utility of further incorporating ToM, as well as other insights from child language acquisition, into computational models of language acquisition.