 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Frequency Enhancement Network for Blind Image Deblurring
Nov 11, 2024Image deblurring is an essential image preprocessing technique, aiming to recover clear and detailed images form blurry ones. However, existing algorithms often fail to effectively integrate multi-scale feature extraction with frequency enhancement, limiting their ability to reconstruct fine textures. Additionally, non-uniform blur in images also restricts the effectiveness of image restoration. To address these issues, we propose a multi-scale frequency enhancement network (MFENet) for blind image deblurring. To capture the multi-scale spatial and channel information of blurred images, we introduce a multi-scale feature extraction module (MS-FE) based on depthwise separable convolutions, which provides rich target features for deblurring. We propose a frequency enhanced blur perception module (FEBP) that employs wavelet transforms to extract high-frequency details and utilizes multi-strip pooling to perceive non-uniform blur, combining multi-scale information with frequency enhancement to improve the restoration of image texture details. Experimental results on the GoPro and HIDE datasets demonstrate that the proposed method achieves superior deblurring performance in both visual quality and objective evaluation metrics. Furthermore, in downstream object detection tasks, the proposed blind image deblurring algorithm significantly improves detection accuracy, further validating its effectiveness androbustness in the field of image deblurring.
Application of Deep Learning in Blind Motion Deblurring: Current Status and Future Prospects
Jan 10, 2024Motion deblurring is one of the fundamental problems of computer vision and has received continuous attention. The variability in blur, both within and across images, imposes limitations on non-blind deblurring techniques that rely on estimating the blur kernel. As a response, blind motion deblurring has emerged, aiming to restore clear and detailed images without prior knowledge of the blur type, fueled by the advancements in deep learning methodologies. Despite strides in this field, a comprehensive synthesis of recent progress in deep learning-based blind motion deblurring is notably absent. This paper fills that gap by providing an exhaustive overview of the role of deep learning in blind motion deblurring, encompassing datasets, evaluation metrics, and methods developed over the last six years. Specifically, we first introduce the types of motion blur and the fundamental principles of deblurring. Next, we outline the shortcomings of traditional non-blind deblurring algorithms, emphasizing the advantages of employing deep learning techniques for deblurring tasks. Following this, we categorize and summarize existing blind motion deblurring methods based on different backbone networks, including convolutional neural networks, generative adversarial networks, recurrent neural networks, and Transformer networks. Subsequently, we elaborate not only on the fundamental principles of these different categories but also provide a comprehensive summary and comparison of their advantages and limitations. Qualitative and quantitative experimental results conducted on four widely used datasets further compare the performance of SOTA methods. Finally, an analysis of present challenges and future pathways. All collected models, benchmark datasets, source code links, and codes for evaluation have been made publicly available at https://github.com/VisionVerse/Blind-Motion-Deblurring-Survey
You Do Not Need Additional Priors in Camouflage Object Detection
Oct 01, 2023Camouflage object detection (COD) poses a significant challenge due to the high resemblance between camouflaged objects and their surroundings. Although current deep learning methods have made significant progress in detecting camouflaged objects, many of them heavily rely on additional prior information. However, acquiring such additional prior information is both expensive and impractical in real-world scenarios. Therefore, there is a need to develop a network for camouflage object detection that does not depend on additional priors. In this paper, we propose a novel adaptive feature aggregation method that effectively combines multi-layer feature information to generate guidance information. In contrast to previous approaches that rely on edge or ranking priors, our method directly leverages information extracted from image features to guide model training. Through extensive experimental results, we demonstrate that our proposed method achieves comparable or superior performance when compared to state-of-the-art approaches.
Position-Aware Relation Learning for RGB-Thermal Salient Object Detection
Sep 21, 2022
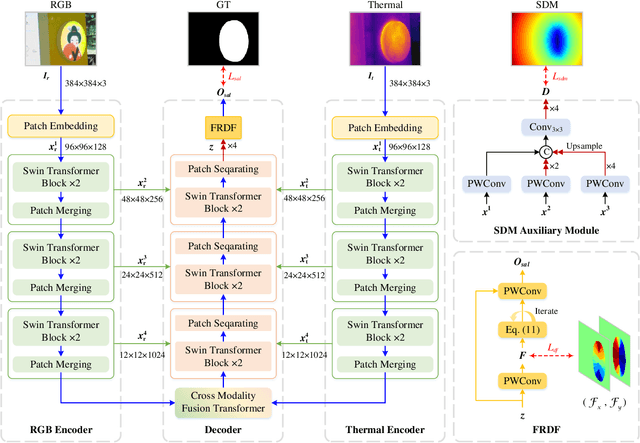
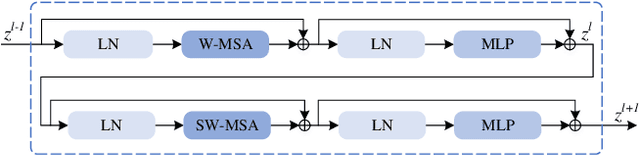

RGB-Thermal salient object detection (SOD) combines two spectra to segment visually conspicuous regions in images. Most existing methods use boundary maps to learn the sharp boundary. These methods ignore the interactions between isolated boundary pixels and other confident pixels, leading to sub-optimal performance. To address this problem,we propose a position-aware relation learning network (PRLNet) for RGB-T SOD based on swin transformer. PRLNet explores the distance and direction relationships between pixels to strengthen intra-class compactness and inter-class separation, generating salient object masks with clear boundaries and homogeneous regions. Specifically, we develop a novel signed distance map auxiliary module (SDMAM) to improve encoder feature representation, which takes into account the distance relation of different pixels in boundary neighborhoods. Then, we design a feature refinement approach with directional field (FRDF), which rectifies features of boundary neighborhood by exploiting the features inside salient objects. FRDF utilizes the directional information between object pixels to effectively enhance the intra-class compactness of salient regions. In addition, we constitute a pure transformer encoder-decoder network to enhance multispectral feature representation for RGB-T SOD. Finally, we conduct quantitative and qualitative experiments on three public benchmark datasets.The results demonstrate that our proposed method outperforms the state-of-the-art methods.
PixelGame: Infrared small target segmentation as a Nash equilibrium
May 26, 2022



A key challenge of infrared small target segmentation (ISTS) is to balance false negative pixels (FNs) and false positive pixels (FPs). Traditional methods combine FNs and FPs into a single objective by weighted sum, and the optimization process is decided by one actor. Minimizing FNs and FPs with the same strategy leads to antagonistic decisions. To address this problem, we propose a competitive game framework (pixelGame) from a novel perspective for ISTS. In pixelGame, FNs and FPs are controlled by different player whose goal is to minimize their own utility function. FNs-player and FPs-player are designed with different strategies: One is to minimize FNs and the other is to minimize FPs. The utility function drives the evolution of the two participants in competition. We consider the Nash equilibrium of pixelGame as the optimal solution. In addition, we propose maximum information modulation (MIM) to highlight the tar-get information. MIM effectively focuses on the salient region including small targets. Extensive experiments on two standard public datasets prove the effectiveness of our method. Compared with other state-of-the-art methods, our method achieves better performance in terms of F1-measure (F1) and the intersection of union (IoU).