 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIA-FaceS: A Bidirectional Method for Semantic Face Editing
Paper and Code
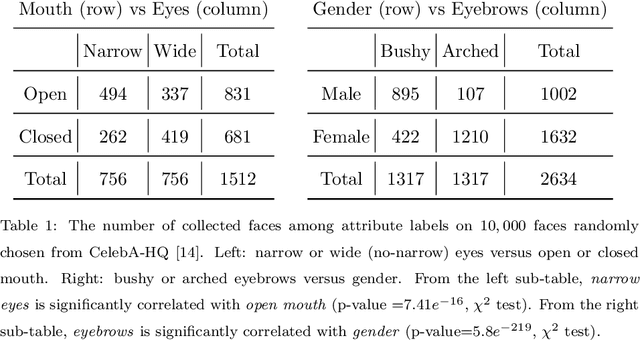
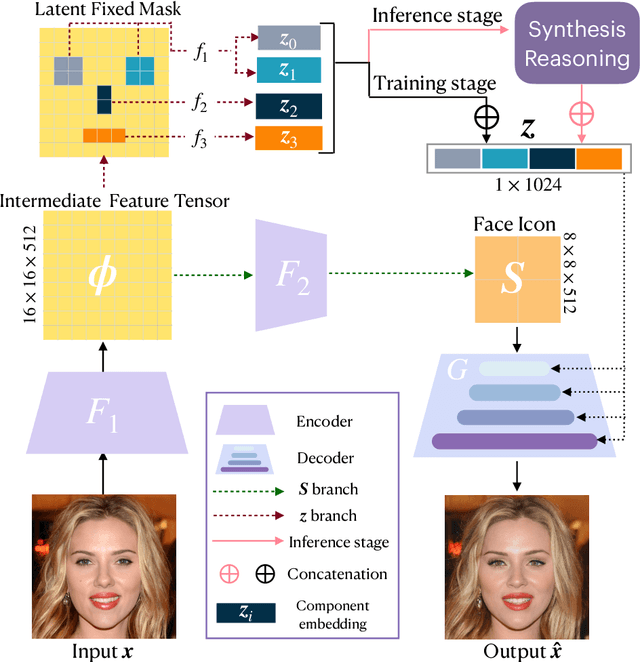


Semantic face editing has achieved substantial progress in recent years. Known as a growingly popular method, latent space manipulation performs face editing by changing the latent code of an input face to liberate users from painting skills. However, previous latent space manipulation methods usually encode an entire face into a single low-dimensional embedding, which constrains the reconstruction capacity and the control flexibility of facial components, such as eyes and nose. This paper proposes IA-FaceS as a bidirectional method for disentangled face attribute manipulation as well as flexible, controllable component editing without the need for segmentation masks or sketches in the original image. To strike a balance between the reconstruction capacity and the control flexibility, the encoder is designed as a multi-head structure to yield embeddings for reconstruction and control, respectively: a high-dimensional tensor with spatial properties for consistent reconstruction and four low-dimensional facial component embeddings for semantic face editing. Manipulating the separate component embeddings can help achieve disentangled attribute manipulation and flexible control of facial components. To further disentangle the highly-correlated components, a component adaptive modulation (CAM) module is proposed for the decoder. The semantic single-eye editing is developed for the first time without any input visual guidance, such as segmentation masks or sketches. According to the experimental results, IA-FaceS establishes a good balance between maintaining image details and performing flexible face manipulation. Both quantitative and qualitative results indicate that the proposed method outperforms the other techniques in reconstruction, face attribute manipulation, and component transfer.