 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interdisciplinary Perspective on Evaluation and Experimental Design for Visual Text Analytics: Position Paper
Sep 23, 2022
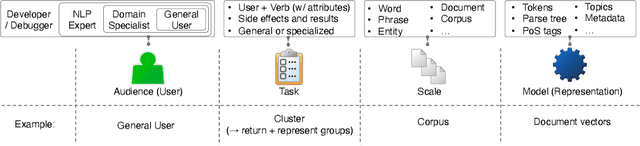
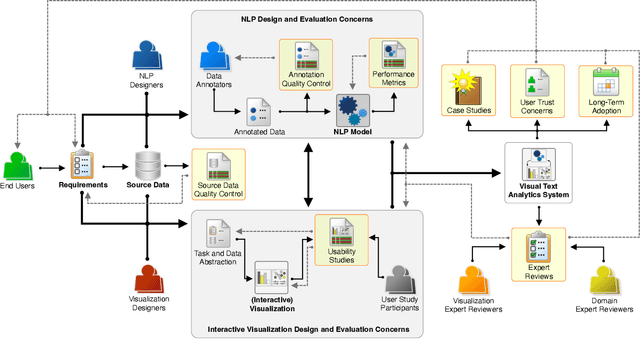
Appropriate evaluation and experimental design are fundamental for empirical sciences, particularly in data-driven fields. Due to the successes in computational modeling of languages, for instance, research outcomes are having an increasingly immediate impact on end users. As the gap in adoption by end users decreases, the need increases to ensure that tools and models developed by the research communities and practitioners are reliable, trustworthy, and supportive of the users in their goals. In this position paper, we focus on the issues of evaluating visual text analytics approaches. We take an interdisciplinary perspective from the visualization and natural language processing communities, as we argue that the design and validation of visual text analytics include concerns beyond computational or visual/interactive methods on their own. We identify four key groups of challenges for evaluating visual text analytics approaches (data ambiguity, experimental design, user trust, and "big picture'' concerns) and provide suggestions for research opportunities from an interdisciplinary perspective.
Characterizing Uncertainty in the Visual Text Analysis Pipeline
Sep 22, 2022Current visual text analysis approaches rely on sophisticated processing pipelines. Each step of such a pipeline potentially amplifies any uncertainties from the previous step. To ensure the comprehensibility and interoperability of the results, it is of paramount importance to clearly communicate the uncertainty not only of the output but also within the pipeline. In this paper, we characterize the sources of uncertainty along the visual text analysis pipeline. Within its three phases of labeling, modeling, and analysis, we identify six sources, discuss the type of uncertainty they create, and how they propagate.
Progressive Data Science: Potential and Challenges
Dec 19, 2018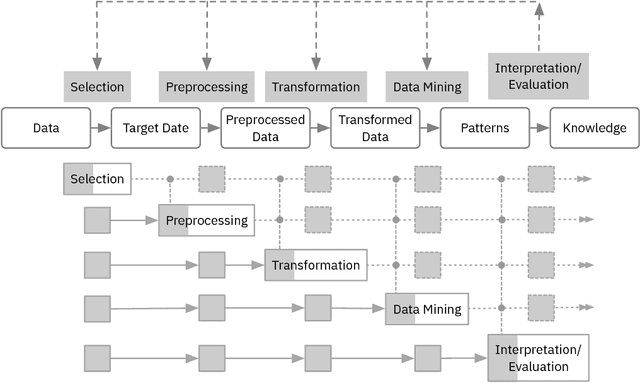
Data science requires time-consuming iterative manual activities. In particular, activities such as data selection, preprocessing, transformation, and mining, highly depend on iterative trial-and-error processes that could be sped up significantly by providing quick feedback on the impact of changes. The idea of progressive data science is to compute the results of changes in a progressive manner, returning a first approximation of results quickly and allow iterative refinements until converging to a final result. Enabling the user to interact with the intermediate results allows an early detection of erroneous or suboptimal choices, the guided definition of modifications to the pipeline and their quick assessment. In this paper, we discuss the progressiveness challenges arising in different steps of the data science pipeline. We describe how changes in each step of the pipeline impact the subsequent steps and outline why progressive data science will help to make the process more effective. Computing progressive approximations of outcomes resulting from changes creates numerous research challenges, especially if the changes are made in the early steps of the pipeline. We discuss these challenges and outline first steps towards progressiveness, which, we argue, will ultimately help to significantly speed-up the overall data science process.