 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Enabled Conversational Journaling for Advancing Parkinson's Disease Symptom Tracking
Mar 05, 2025Journaling plays a crucial role in managing chronic conditions by allowing patients to document symptoms and medication intake, providing essential data for long-term care. While valuable, traditional journaling methods often rely on static, self-directed entries, lacking interactive feedback and real-time guidance. This gap can result in incomplete or imprecise information, limiting its usefulness for effective treatment. To address this gap, we introduce PATRIKA, an AI-enabled prototype designed specifically for people with Parkinson's disease (PwPD). The system incorporates cooperative conversation principles, clinical interview simulations, and personalization to create a more effective and user-friendly journaling experience. Through two user studies with PwPD and iterative refinement of PATRIKA, we demonstrate conversational journaling's significant potential in patient engagement and collecting clinically valuable information. Our results showed that generating probing questions PATRIKA turned journaling into a bi-directional interaction. Additionally, we offer insights for designing journaling systems for healthcare and future directions for promoting sustained journaling.
How Data Scientists Review the Scholarly Literature
Jan 10, 2023

Keeping up with the research literature plays an important role in the workflow of scientists - allowing them to understand a field, formulate the problems they focus on, and develop the solutions that they contribute, which in turn shape the nature of the discipline. In this paper, we examine the literature review practices of data scientists. Data science represents a field seeing an exponential rise in papers, and increasingly drawing on and being applied in numerous diverse disciplines. Recent efforts have seen the development of several tools intended to help data scientists cope with a deluge of research and coordinated efforts to develop AI tools intended to uncover the research frontier. Despite these trends indicative of the information overload faced by data scientists, no prior work has examined the specific practices and challenges faced by these scientists in an interdisciplinary field with evolving scholarly norms. In this paper, we close this gap through a set of semi-structured interviews and think-aloud protocols of industry and academic data scientists (N = 20). Our results while corroborating other knowledge workers' practices uncover several novel findings: individuals (1) are challenged in seeking and sensemaking of papers beyond their disciplinary bubbles, (2) struggle to understand papers in the face of missing details and mathematical content, (3) grapple with the deluge by leveraging the knowledge context in code, blogs, and talks, and (4) lean on their peers online and in-person. Furthermore, we outline future directions likely to help data scientists cope with the burgeoning research literature.
An Interdisciplinary Perspective on Evaluation and Experimental Design for Visual Text Analytics: Position Paper
Sep 23, 2022
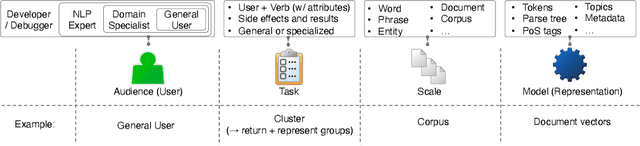
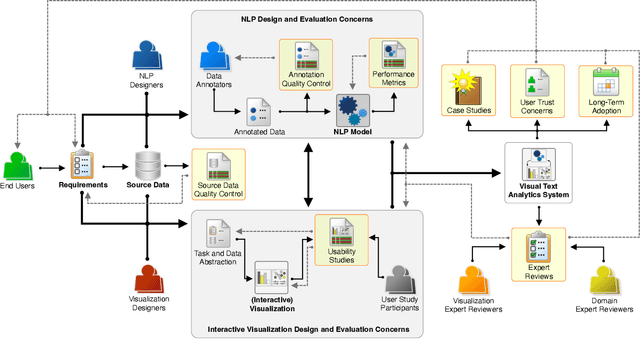
Appropriate evaluation and experimental design are fundamental for empirical sciences, particularly in data-driven fields. Due to the successes in computational modeling of languages, for instance, research outcomes are having an increasingly immediate impact on end users. As the gap in adoption by end users decreases, the need increases to ensure that tools and models developed by the research communities and practitioners are reliable, trustworthy, and supportive of the users in their goals. In this position paper, we focus on the issues of evaluating visual text analytics approaches. We take an interdisciplinary perspective from the visualization and natural language processing communities, as we argue that the design and validation of visual text analytics include concerns beyond computational or visual/interactive methods on their own. We identify four key groups of challenges for evaluating visual text analytics approaches (data ambiguity, experimental design, user trust, and "big picture'' concerns) and provide suggestions for research opportunities from an interdisciplinary perspective.
Characterizing Uncertainty in the Visual Text Analysis Pipeline
Sep 22, 2022Current visual text analysis approaches rely on sophisticated processing pipelines. Each step of such a pipeline potentially amplifies any uncertainties from the previous step. To ensure the comprehensibility and interoperability of the results, it is of paramount importance to clearly communicate the uncertainty not only of the output but also within the pipeline. In this paper, we characterize the sources of uncertainty along the visual text analysis pipeline. Within its three phases of labeling, modeling, and analysis, we identify six sources, discuss the type of uncertainty they create, and how they propagate.