 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataTales: Investigating the use of Large Language Models for Authoring Data-Driven Articles
Aug 08, 2023Authoring data-driven articles is a complex process requiring authors to not only analyze data for insights but also craft a cohesive narrative that effectively communicates the insights. Text generation capabilities of contemporary large language models (LLMs) present an opportunity to assist the authoring of data-driven articles and expedite the writing process. In this work, we investigate the feasibility and perceived value of leveraging LLMs to support authors of data-driven articles. We designed a prototype system, DataTales, that leverages a LLM to generate textual narratives accompanying a given chart. Using DataTales as a design probe, we conducted a qualitative study with 11 professionals to evaluate the concept, from which we distilled affordances and opportunities to further integrate LLMs as valuable data-driven article authoring assistants.
An Interdisciplinary Perspective on Evaluation and Experimental Design for Visual Text Analytics: Position Paper
Sep 23, 2022
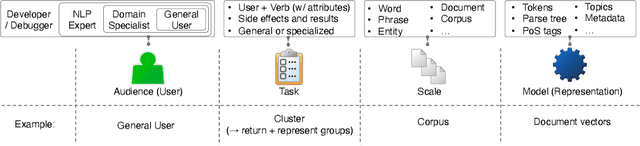
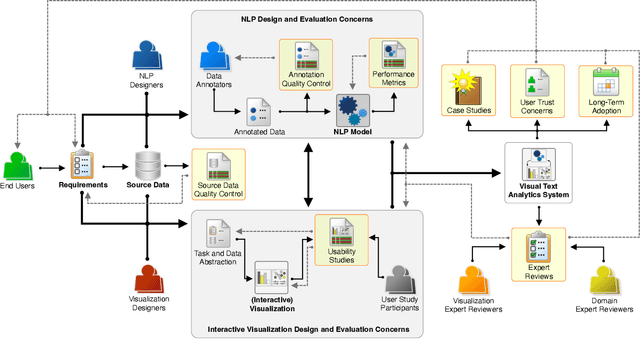
Appropriate evaluation and experimental design are fundamental for empirical sciences, particularly in data-driven fields. Due to the successes in computational modeling of languages, for instance, research outcomes are having an increasingly immediate impact on end users. As the gap in adoption by end users decreases, the need increases to ensure that tools and models developed by the research communities and practitioners are reliable, trustworthy, and supportive of the users in their goals. In this position paper, we focus on the issues of evaluating visual text analytics approaches. We take an interdisciplinary perspective from the visualization and natural language processing communities, as we argue that the design and validation of visual text analytics include concerns beyond computational or visual/interactive methods on their own. We identify four key groups of challenges for evaluating visual text analytics approaches (data ambiguity, experimental design, user trust, and "big picture'' concerns) and provide suggestions for research opportunities from an interdisciplinary perspective.