 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Agent Behavior Learning in Autonomous Driving Using Deep Reinforcement Learning
Aug 21, 2025Existing approaches in reinforcement learning train an agent to learn desired optimal behavior in an environment with rule based surrounding agents. In safety critical applications such as autonomous driving it is crucial that the rule based agents are modelled properly. Several behavior modelling strategies and IDM models are used currently to model the surrounding agents. We present a learning based method to derive the adversarial behavior for the rule based agents to cause failure scenarios. We evaluate our adversarial agent against all the rule based agents and show the decrease in cumulative reward.
AI-Guided Feature Segmentation Techniques to Model Features from Single Crystal Diamond Growth
Apr 10, 2024Process refinement to consistently produce high-quality material over a large area of the grown crystal, enabling various applications from optics crystals to quantum detectors, has long been a goal for diamond growth. Machine learning offers a promising path toward this goal, but faces challenges such as the complexity of features within datasets, their time-dependency, and the volume of data produced per growth run. Accurate spatial feature extraction from image to image for real-time monitoring of diamond growth is crucial yet complicated due to the low-volume and high feature complexity nature of the datasets. This paper compares various traditional and machine learning-driven approaches for feature extraction in the diamond growth domain, proposing a novel deep learning-driven semantic segmentation approach to isolate and classify accurate pixel masks of geometric features like diamond, pocket holder, and background, along with their derivative features based on shape and size. Using an annotation-focused human-in-the-loop software architecture for training datasets, with modules for selective data labeling using active learning, data augmentations, and model-assisted labeling, our approach achieves effective annotation accuracy and drastically reduces labeling time and cost. Deep learning algorithms prove highly efficient in accurately learning complex representations from datasets with many features. Our top-performing model, based on the DeeplabV3plus architecture, achieves outstanding accuracy in classifying features of interest, with accuracies of 96.31% for pocket holder, 98.60% for diamond top, and 91.64% for diamond side features.
AI-Guided Defect Detection Techniques to Model Single Crystal Diamond Growth
Apr 10, 2024



From a process development perspective, diamond growth via chemical vapor deposition has made significant strides. However, challenges persist in achieving high quality and large-area material production. These difficulties include controlling conditions to maintain uniform growth rates for the entire growth surface. As growth progresses, various factors or defect states emerge, altering the uniform conditions. These changes affect the growth rate and result in the formation of crystalline defects at the microscale. However, there is a distinct lack of methods to identify these defect states and their geometry using images taken during the growth process. This paper details seminal work on defect segmentation pipeline using in-situ optical images to identify features that indicate defective states that are visible at the macroscale. Using a semantic segmentation approach as applied in our previous work, these defect states and corresponding derivative features are isolated and classified by their pixel masks. Using an annotation focused human-in-the-loop software architecture to produce training datasets, with modules for selective data labeling using active learning, data augmentations, and model-assisted labeling, our approach achieves effective annotation accuracy and drastically reduces the time and cost of labeling by orders of magnitude. On the model development front, we found that deep learning-based algorithms are the most efficient. They can accurately learn complex representations from feature-rich datasets. Our best-performing model, based on the YOLOV3 and DeeplabV3plus architectures, achieved excellent accuracy for specific features of interest. Specifically, it reached 93.35% accuracy for center defects, 92.83% for polycrystalline defects, and 91.98% for edge defects.
DataTales: Investigating the use of Large Language Models for Authoring Data-Driven Articles
Aug 08, 2023

Authoring data-driven articles is a complex process requiring authors to not only analyze data for insights but also craft a cohesive narrative that effectively communicates the insights. Text generation capabilities of contemporary large language models (LLMs) present an opportunity to assist the authoring of data-driven articles and expedite the writing process. In this work, we investigate the feasibility and perceived value of leveraging LLMs to support authors of data-driven articles. We designed a prototype system, DataTales, that leverages a LLM to generate textual narratives accompanying a given chart. Using DataTales as a design probe, we conducted a qualitative study with 11 professionals to evaluate the concept, from which we distilled affordances and opportunities to further integrate LLMs as valuable data-driven article authoring assistants.
Can a Robot Trust You? A DRL-Based Approach to Trust-Driven Human-Guided Navigation
Nov 01, 2020
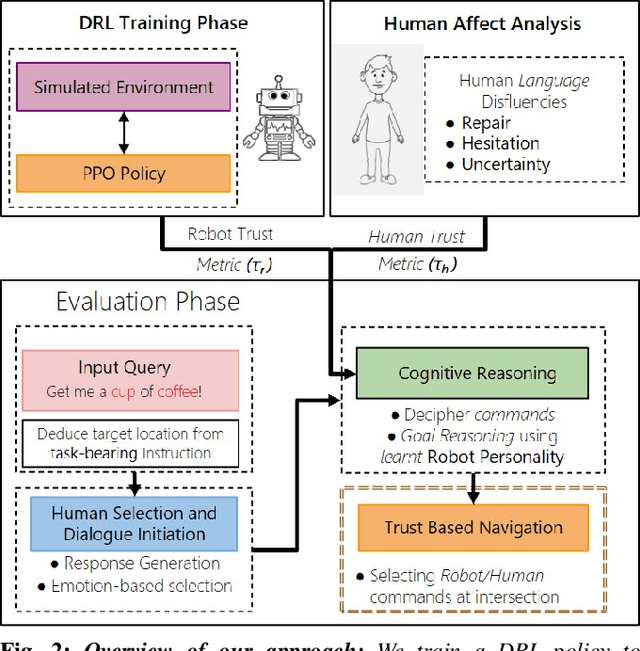
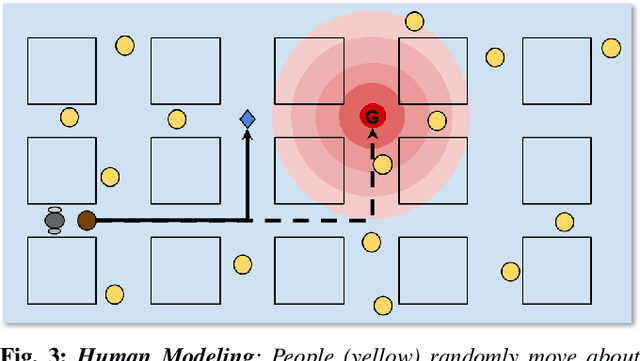
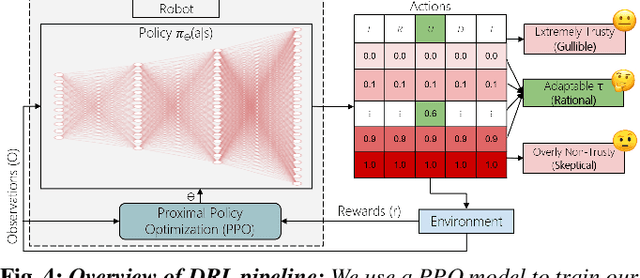
Humans are known to construct cognitive maps of their everyday surroundings using a variety of perceptual inputs. As such, when a human is asked for directions to a particular location, their wayfinding capability in converting this cognitive map into directional instructions is challenged. Owing to spatial anxiety, the language used in the spoken instructions can be vague and often unclear. To account for this unreliability in navigational guidance, we propose a novel Deep Reinforcement Learning (DRL) based trust-driven robot navigation algorithm that learns humans' trustworthiness to perform a language guided navigation task. Our approach seeks to answer the question as to whether a robot can trust a human's navigational guidance or not. To this end, we look at training a policy that learns to navigate towards a goal location using only trustworthy human guidance, driven by its own robot trust metric. We look at quantifying various affective features from language-based instructions and incorporate them into our policy's observation space in the form of a human trust metric. We utilize both these trust metrics into an optimal cognitive reasoning scheme that decides when and when not to trust the given guidance. Our results show that the learned policy can navigate the environment in an optimal, time-efficient manner as opposed to an explorative approach that performs the same task. We showcase the efficacy of our results both in simulation and a real-world environment.