 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSAIC: Modular Orchestration for Structured Agentic Intelligence and Composition
May 30, 2026Automated data science is a structured model-selection problem. A solution must choose data transformations, feature representations, architecture, training procedure, evaluation protocol, and refinement strategy for a task. AutoML systems automate parts of this process, but typically search within predefined pipeline, model, and hyperparameter spaces. LLM-based agents offer greater flexibility through retrieval, code generation, and execution feedback, yet their modelling decisions are often unstructured, difficult to verify, and hard to reuse. We introduce \textsc{MOSAIC} (Modular Orchestration for Structured Agentic Intelligence and Composition), a structured agentic framework for memory-grounded model selection and workflow construction. Given a task and dataset, \textsc{MOSAIC} builds a semantic task profile, retrieves prior cases and source-code modules, and constructs a blueprint: an intermediate representation specifying selected modelling components, composition, interface constraints, and execution requirements. This blueprint turns model selection into a staged, context-grounded search and grounds LLM-based code generation in retrieved evidence rather than unconstrained synthesis. Candidate models are validated by execution and refined using diagnostic feedback, training traces, task metrics, and a failure-aware reinforcement learning policy. We instantiate \textsc{MOSAIC} on financial time-series forecasting and generation, where models must satisfy predictive accuracy, distributional fidelity, execution reliability, and downstream financial criteria such as risk and tail behaviour. Experiments against AutoML and agentic baselines show that \textsc{MOSAIC} improves task performance, execution success, and decision traceability, demonstrating the value of treating automated data science as structured, reusable, and execution-grounded model selection.
Debating the Unspoken: Role-Anchored Multi-Agent Reasoning for Half-Truth Detection
Apr 21, 2026Half-truths, claims that are factually correct yet misleading due to omitted context, remain a blind spot for fact verification systems focused on explicit falsehoods. Addressing such omission-based manipulation requires reasoning not only about what is said, but also about what is left unsaid. We propose RADAR, a role-anchored multi-agent debate framework for omission-aware fact verification under realistic, noisy retrieval. RADAR assigns complementary roles to a Politician and a Scientist, who reason adversarially over shared retrieved evidence, moderated by a neutral Judge. A dual-threshold early termination controller adaptively decides when sufficient reasoning has been reached to issue a verdict. Experiments show that RADAR consistently outperforms strong single- and multi-agent baselines across datasets and backbones, improving omission detection accuracy while reducing reasoning cost. These results demonstrate that role-anchored, retrieval-grounded debate with adaptive control is an effective and scalable framework for uncovering missing context in fact verification. The code is available at https://github.com/tangyixuan/RADAR.
Weight-Informed Self-Explaining Clustering for Mixed-Type Tabular Data
Apr 07, 2026Clustering mixed-type tabular data is fundamental for exploratory analysis, yet remains challenging due to misaligned numerical-categorical representations, uneven and context-dependent feature relevance, and disconnected and post-hoc explanation from the clustering process. We propose WISE, a Weight-Informed Self-Explaining framework that unifies representation, feature weighting, clustering, and interpretation in a fully unsupervised and transparent pipeline. WISE introduces Binary Encoding with Padding (BEP) to align heterogeneous features in a unified sparse space, a Leave-One-Feature-Out (LOFO) strategy to sense multiple high-quality and diverse feature-weighting views, and a two-stage weight-aware clustering procedure to aggregate alternative semantic partitions. To ensure intrinsic interpretability, we further develop Discriminative FreqItems (DFI), which yields feature-level explanations that are consistent from instances to clusters with an additive decomposition guarantee. Extensive experiments on six real-world datasets demonstrate that WISE consistently outperforms classical and neural baselines in clustering quality while remaining efficient, and produces faithful, human-interpretable explanations grounded in the same primitives that drive clustering.
QIME: Constructing Interpretable Medical Text Embeddings via Ontology-Grounded Questions
Mar 03, 2026While dense biomedical embeddings achieve strong performance, their black-box nature limits their utility in clinical decision-making. Recent question-based interpretable embeddings represent text as binary answers to natural-language questions, but these approaches often rely on heuristic or surface-level contrastive signals and overlook specialized domain knowledge. We propose QIME, an ontology-grounded framework for constructing interpretable medical text embeddings in which each dimension corresponds to a clinically meaningful yes/no question. By conditioning on cluster-specific medical concept signatures, QIME generates semantically atomic questions that capture fine-grained distinctions in biomedical text. Furthermore, QIME supports a training-free embedding construction strategy that eliminates per-question classifier training while further improving performance. Experiments across biomedical semantic similarity, clustering, and retrieval benchmarks show that QIME consistently outperforms prior interpretable embedding methods and substantially narrows the gap to strong black-box biomedical encoders, while providing concise and clinically informative explanations.
IDRBench: Interactive Deep Research Benchmark
Jan 10, 2026Deep research agents powered by Large Language Models (LLMs) can perform multi-step reasoning, web exploration, and long-form report generation. However, most existing systems operate in an autonomous manner, assuming fully specified user intent and evaluating only final outputs. In practice, research goals are often underspecified and evolve during exploration, making sustained interaction essential for robust alignment. Despite its importance, interaction remains largely invisible to existing deep research benchmarks, which neither model dynamic user feedback nor quantify its costs. We introduce IDRBench, the first benchmark for systematically evaluating interactive deep research. IDRBench combines a modular multi-agent research framework with on-demand interaction, a scalable reference-grounded user simulator, and an interaction-aware evaluation suite that jointly measures interaction benefits (quality and alignment) and costs (turns and tokens). Experiments across seven state-of-the-art LLMs show that interaction consistently improves research quality and robustness, often outweighing differences in model capacity, while revealing substantial trade-offs in interaction efficiency.
Text Embeddings Should Capture Implicit Semantics, Not Just Surface Meaning
Jun 10, 2025This position paper argues that the text embedding research community should move beyond surface meaning and embrace implicit semantics as a central modeling goal. Text embedding models have become foundational in modern NLP, powering a wide range of applications and drawing increasing research attention. Yet, much of this progress remains narrowly focused on surface-level semantics. In contrast, linguistic theory emphasizes that meaning is often implicit, shaped by pragmatics, speaker intent, and sociocultural context. Current embedding models are typically trained on data that lacks such depth and evaluated on benchmarks that reward the capture of surface meaning. As a result, they struggle with tasks requiring interpretive reasoning, speaker stance, or social meaning. Our pilot study highlights this gap, showing that even state-of-the-art models perform only marginally better than simplistic baselines on implicit semantics tasks. To address this, we call for a paradigm shift: embedding research should prioritize more diverse and linguistically grounded training data, design benchmarks that evaluate deeper semantic understanding, and explicitly frame implicit meaning as a core modeling objective, better aligning embeddings with real-world language complexity.
PRISM: A Framework for Producing Interpretable Political Bias Embeddings with Political-Aware Cross-Encoder
May 30, 2025Semantic Text Embedding is a fundamental NLP task that encodes textual content into vector representations, where proximity in the embedding space reflects semantic similarity. While existing embedding models excel at capturing general meaning, they often overlook ideological nuances, limiting their effectiveness in tasks that require an understanding of political bias. To address this gap, we introduce PRISM, the first framework designed to Produce inteRpretable polItical biaS eMbeddings. PRISM operates in two key stages: (1) Controversial Topic Bias Indicator Mining, which systematically extracts fine-grained political topics and their corresponding bias indicators from weakly labeled news data, and (2) Cross-Encoder Political Bias Embedding, which assigns structured bias scores to news articles based on their alignment with these indicators. This approach ensures that embeddings are explicitly tied to bias-revealing dimensions, enhancing both interpretability and predictive power. Through extensive experiments on two large-scale datasets, we demonstrate that PRISM outperforms state-of-the-art text embedding models in political bias classification while offering highly interpretable representations that facilitate diversified retrieval and ideological analysis. The source code is available at https://github.com/dukesun99/ACL-PRISM.
Don't Reinvent the Wheel: Efficient Instruction-Following Text Embedding based on Guided Space Transformation
May 30, 2025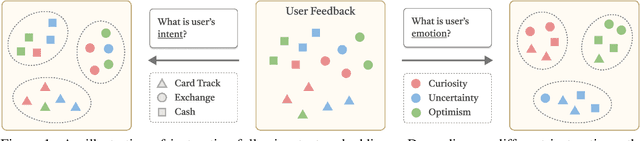
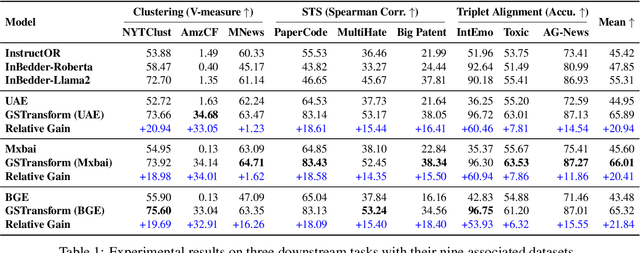

In this work, we investigate an important task named instruction-following text embedding, which generates dynamic text embeddings that adapt to user instructions, highlighting specific attributes of text. Despite recent advancements, existing approaches suffer from significant computational overhead, as they require re-encoding the entire corpus for each new instruction. To address this challenge, we propose GSTransform, a novel instruction-following text embedding framework based on Guided Space Transformation. Our key observation is that instruction-relevant information is inherently encoded in generic embeddings but remains underutilized. Instead of repeatedly encoding the corpus for each instruction, GSTransform is a lightweight transformation mechanism that adapts pre-computed embeddings in real time to align with user instructions, guided by a small amount of text data with instruction-focused label annotation. We conduct extensive experiments on three instruction-awareness downstream tasks across nine real-world datasets, demonstrating that GSTransform improves instruction-following text embedding quality over state-of-the-art methods while achieving dramatic speedups of 6~300x in real-time processing on large-scale datasets. The source code is available at https://github.com/YingchaojieFeng/GSTransform.
A General Framework for Producing Interpretable Semantic Text Embeddings
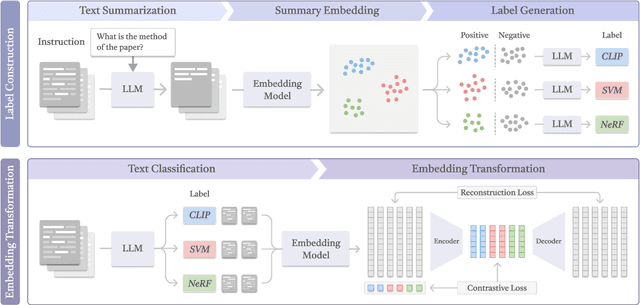
Oct 04, 2024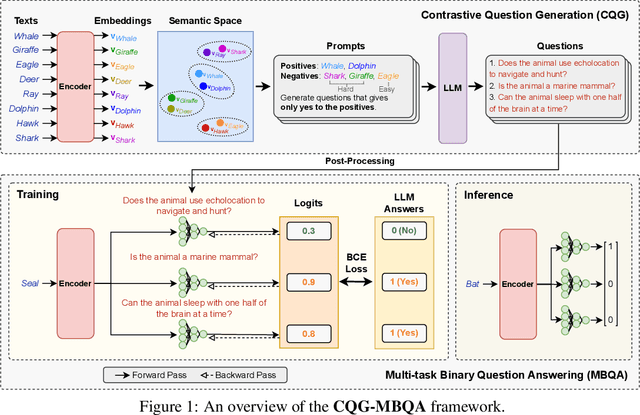
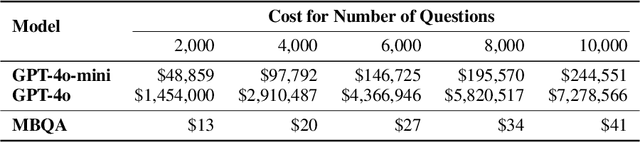
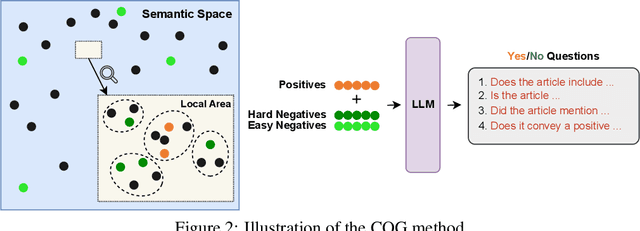
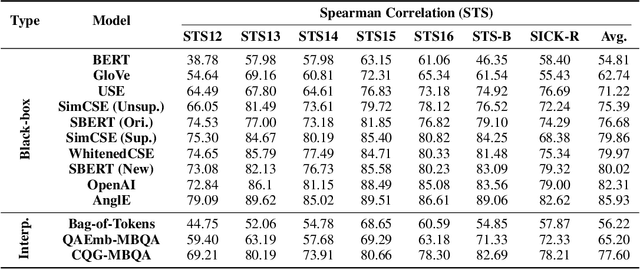
Semantic text embedding is essential to many tasks in Natural Language Processing (NLP). While black-box models are capable of generating high-quality embeddings, their lack of interpretability limits their use in tasks that demand transparency. Recent approaches have improved interpretability by leveraging domain-expert-crafted or LLM-generated questions, but these methods rely heavily on expert input or well-prompt design, which restricts their generalizability and ability to generate discriminative questions across a wide range of tasks. To address these challenges, we introduce \algo{CQG-MBQA} (Contrastive Question Generation - Multi-task Binary Question Answering), a general framework for producing interpretable semantic text embeddings across diverse tasks. Our framework systematically generates highly discriminative, low cognitive load yes/no questions through the \algo{CQG} method and answers them efficiently with the \algo{MBQA} model, resulting in interpretable embeddings in a cost-effective manner. We validate the effectiveness and interpretability of \algo{CQG-MBQA} through extensive experiments and ablation studies, demonstrating that it delivers embedding quality comparable to many advanced black-box models while maintaining inherently interpretability. Additionally, \algo{CQG-MBQA} outperforms other interpretable text embedding methods across various downstream tasks.
Towards Controllable Time Series Generation
Mar 06, 2024Time Series Generation (TSG) has emerged as a pivotal technique in synthesizing data that accurately mirrors real-world time series, becoming indispensable in numerous applications. Despite significant advancements in TSG, its efficacy frequently hinges on having large training datasets. This dependency presents a substantial challenge in data-scarce scenarios, especially when dealing with rare or unique conditions. To confront these challenges, we explore a new problem of Controllable Time Series Generation (CTSG), aiming to produce synthetic time series that can adapt to various external conditions, thereby tackling the data scarcity issue. In this paper, we propose \textbf{C}ontrollable \textbf{T}ime \textbf{S}eries (\textsf{CTS}), an innovative VAE-agnostic framework tailored for CTSG. A key feature of \textsf{CTS} is that it decouples the mapping process from standard VAE training, enabling precise learning of a complex interplay between latent features and external conditions. Moreover, we develop a comprehensive evaluation scheme for CTSG. Extensive experiments across three real-world time series datasets showcase \textsf{CTS}'s exceptional capabilities in generating high-quality, controllable outputs. This underscores its adeptness in seamlessly integrating latent features with external conditions. Extending \textsf{CTS} to the image domain highlights its remarkable potential for explainability and further reinforces its versatility across different modalities.