 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrchMAS: Orchestrated Reasoning with Multi Collaborative Heterogeneous Scientific Expert Structured Agents
Mar 03, 2026Multi-agent large language model frameworks are promising for complex multi step reasoning, yet existing systems remain weak for scientific and knowledge intensive domains due to static prompts and agent roles, rigid workflows, and homogeneous model reliance, leading to poor domain adaptation, limited reasoning flexibility, and high latency on heterogeneous or long-horizon scientific tasks. They also struggle to revise earlier decisions when intermediate reasoning diverges, reducing reliability in structured and calculation heavy settings. To address these limitations, we propose a scientific domain oriented interactive two tier multi model orchestration framework. A dedicated orchestration model analyzes each task, dynamically constructs a domain aware reasoning pipeline, and instantiates specialized expert agents with tailored prompts, while an execution model performs each step under generated role and instruction specifications. The orchestrator iteratively updates the pipeline based on intermediate feedback, enabling dynamic replanning, role reallocation, and prompt refinement across multi turn interactions, strengthening robustness and specialization for scientific reasoning through structured heterogeneous model collaboration. The framework is model agnostic and supports heterogeneous LLM integration with different capacities or costs, enabling flexible performance efficiency trade offs in practical scientific deployments. Experiments show consistent improvements over existing multi agent systems and strong baselines across diverse reasoning and scientific style benchmarks.
Uncovering the Bigger Picture: Comprehensive Event Understanding Via Diverse News Retrieval
Aug 27, 2025Access to diverse perspectives is essential for understanding real-world events, yet most news retrieval systems prioritize textual relevance, leading to redundant results and limited viewpoint exposure. We propose NEWSCOPE, a two-stage framework for diverse news retrieval that enhances event coverage by explicitly modeling semantic variation at the sentence level. The first stage retrieves topically relevant content using dense retrieval, while the second stage applies sentence-level clustering and diversity-aware re-ranking to surface complementary information. To evaluate retrieval diversity, we introduce three interpretable metrics, namely Average Pairwise Distance, Positive Cluster Coverage, and Information Density Ratio, and construct two paragraph-level benchmarks: LocalNews and DSGlobal. Experiments show that NEWSCOPE consistently outperforms strong baselines, achieving significantly higher diversity without compromising relevance. Our results demonstrate the effectiveness of fine-grained, interpretable modeling in mitigating redundancy and promoting comprehensive event understanding. The data and code are available at https://github.com/tangyixuan/NEWSCOPE.
Text Embeddings Should Capture Implicit Semantics, Not Just Surface Meaning
Jun 10, 2025This position paper argues that the text embedding research community should move beyond surface meaning and embrace implicit semantics as a central modeling goal. Text embedding models have become foundational in modern NLP, powering a wide range of applications and drawing increasing research attention. Yet, much of this progress remains narrowly focused on surface-level semantics. In contrast, linguistic theory emphasizes that meaning is often implicit, shaped by pragmatics, speaker intent, and sociocultural context. Current embedding models are typically trained on data that lacks such depth and evaluated on benchmarks that reward the capture of surface meaning. As a result, they struggle with tasks requiring interpretive reasoning, speaker stance, or social meaning. Our pilot study highlights this gap, showing that even state-of-the-art models perform only marginally better than simplistic baselines on implicit semantics tasks. To address this, we call for a paradigm shift: embedding research should prioritize more diverse and linguistically grounded training data, design benchmarks that evaluate deeper semantic understanding, and explicitly frame implicit meaning as a core modeling objective, better aligning embeddings with real-world language complexity.
Don't Reinvent the Wheel: Efficient Instruction-Following Text Embedding based on Guided Space Transformation
May 30, 2025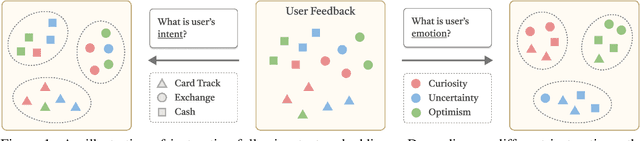
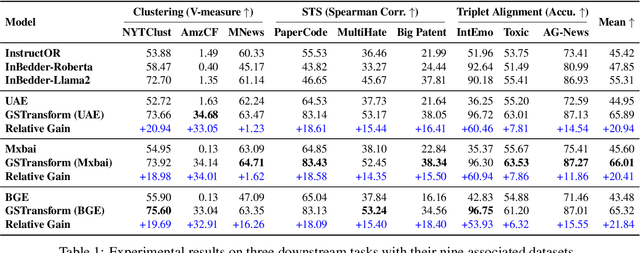

In this work, we investigate an important task named instruction-following text embedding, which generates dynamic text embeddings that adapt to user instructions, highlighting specific attributes of text. Despite recent advancements, existing approaches suffer from significant computational overhead, as they require re-encoding the entire corpus for each new instruction. To address this challenge, we propose GSTransform, a novel instruction-following text embedding framework based on Guided Space Transformation. Our key observation is that instruction-relevant information is inherently encoded in generic embeddings but remains underutilized. Instead of repeatedly encoding the corpus for each instruction, GSTransform is a lightweight transformation mechanism that adapts pre-computed embeddings in real time to align with user instructions, guided by a small amount of text data with instruction-focused label annotation. We conduct extensive experiments on three instruction-awareness downstream tasks across nine real-world datasets, demonstrating that GSTransform improves instruction-following text embedding quality over state-of-the-art methods while achieving dramatic speedups of 6~300x in real-time processing on large-scale datasets. The source code is available at https://github.com/YingchaojieFeng/GSTransform.
PRISM: A Framework for Producing Interpretable Political Bias Embeddings with Political-Aware Cross-Encoder
May 30, 2025Semantic Text Embedding is a fundamental NLP task that encodes textual content into vector representations, where proximity in the embedding space reflects semantic similarity. While existing embedding models excel at capturing general meaning, they often overlook ideological nuances, limiting their effectiveness in tasks that require an understanding of political bias. To address this gap, we introduce PRISM, the first framework designed to Produce inteRpretable polItical biaS eMbeddings. PRISM operates in two key stages: (1) Controversial Topic Bias Indicator Mining, which systematically extracts fine-grained political topics and their corresponding bias indicators from weakly labeled news data, and (2) Cross-Encoder Political Bias Embedding, which assigns structured bias scores to news articles based on their alignment with these indicators. This approach ensures that embeddings are explicitly tied to bias-revealing dimensions, enhancing both interpretability and predictive power. Through extensive experiments on two large-scale datasets, we demonstrate that PRISM outperforms state-of-the-art text embedding models in political bias classification while offering highly interpretable representations that facilitate diversified retrieval and ideological analysis. The source code is available at https://github.com/dukesun99/ACL-PRISM.
MAST-Pro: Dynamic Mixture-of-Experts for Adaptive Segmentation of Pan-Tumors with Knowledge-Driven Prompts
Mar 18, 2025Accurate tumor segmentation is crucial for cancer diagnosis and treatment. While foundation models have advanced general-purpose segmentation, existing methods still struggle with: (1) limited incorporation of medical priors, (2) imbalance between generic and tumor-specific features, and (3) high computational costs for clinical adaptation. To address these challenges, we propose MAST-Pro (Mixture-of-experts for Adaptive Segmentation of pan-Tumors with knowledge-driven Prompts), a novel framework that integrates dynamic Mixture-of-Experts (D-MoE) and knowledge-driven prompts for pan-tumor segmentation. Specifically, text and anatomical prompts provide domain-specific priors, guiding tumor representation learning, while D-MoE dynamically selects experts to balance generic and tumor-specific feature learning, improving segmentation accuracy across diverse tumor types. To enhance efficiency, we employ Parameter-Efficient Fine-Tuning (PEFT), optimizing MAST-Pro with significantly reduced computational overhead. Experiments on multi-anatomical tumor datasets demonstrate that MAST-Pro outperforms state-of-the-art approaches, achieving up to a 5.20% improvement in average DSC while reducing trainable parameters by 91.04%, without compromising accuracy.
A General Framework for Producing Interpretable Semantic Text Embeddings
Oct 04, 2024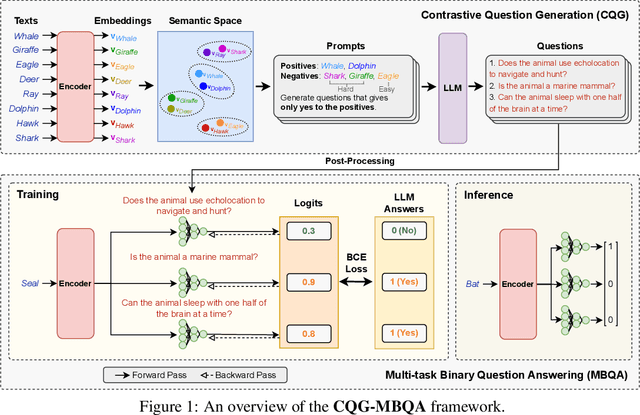
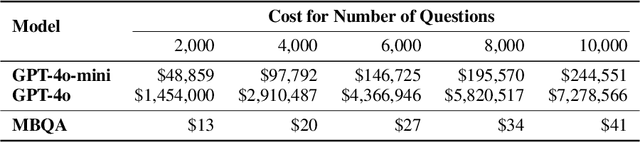
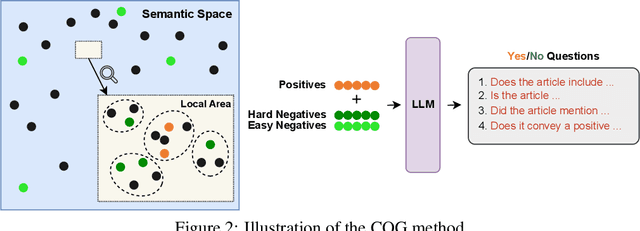
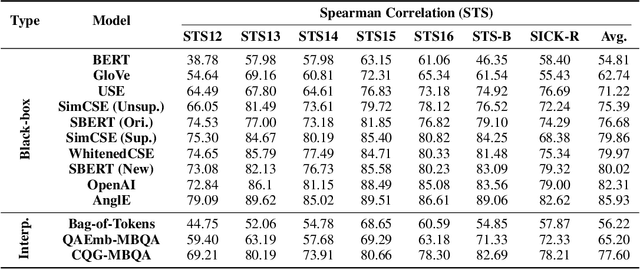
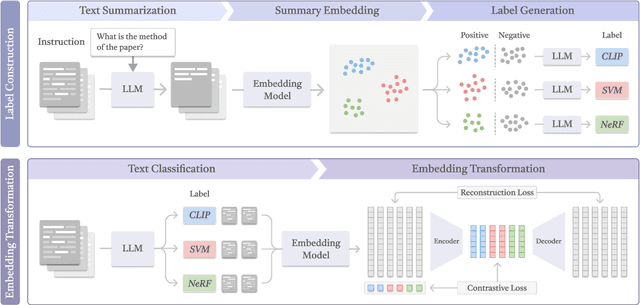
Semantic text embedding is essential to many tasks in Natural Language Processing (NLP). While black-box models are capable of generating high-quality embeddings, their lack of interpretability limits their use in tasks that demand transparency. Recent approaches have improved interpretability by leveraging domain-expert-crafted or LLM-generated questions, but these methods rely heavily on expert input or well-prompt design, which restricts their generalizability and ability to generate discriminative questions across a wide range of tasks. To address these challenges, we introduce \algo{CQG-MBQA} (Contrastive Question Generation - Multi-task Binary Question Answering), a general framework for producing interpretable semantic text embeddings across diverse tasks. Our framework systematically generates highly discriminative, low cognitive load yes/no questions through the \algo{CQG} method and answers them efficiently with the \algo{MBQA} model, resulting in interpretable embeddings in a cost-effective manner. We validate the effectiveness and interpretability of \algo{CQG-MBQA} through extensive experiments and ablation studies, demonstrating that it delivers embedding quality comparable to many advanced black-box models while maintaining inherently interpretability. Additionally, \algo{CQG-MBQA} outperforms other interpretable text embedding methods across various downstream tasks.
Diversity-Aware $k$-Maximum Inner Product Search Revisited
Feb 21, 2024



The $k$-Maximum Inner Product Search ($k$MIPS) serves as a foundational component in recommender systems and various data mining tasks. However, while most existing $k$MIPS approaches prioritize the efficient retrieval of highly relevant items for users, they often neglect an equally pivotal facet of search results: \emph{diversity}. To bridge this gap, we revisit and refine the diversity-aware $k$MIPS (D$k$MIPS) problem by incorporating two well-known diversity objectives -- minimizing the average and maximum pairwise item similarities within the results -- into the original relevance objective. This enhancement, inspired by Maximal Marginal Relevance (MMR), offers users a controllable trade-off between relevance and diversity. We introduce \textsc{Greedy} and \textsc{DualGreedy}, two linear scan-based algorithms tailored for D$k$MIPS. They both achieve data-dependent approximations and, when aiming to minimize the average pairwise similarity, \textsc{DualGreedy} attains an approximation ratio of $1/4$ with an additive term for regularization. To further improve query efficiency, we integrate a lightweight Ball-Cone Tree (BC-Tree) index with the two algorithms. Finally, comprehensive experiments on ten real-world data sets demonstrate the efficacy of our proposed methods, showcasing their capability to efficiently deliver diverse and relevant search results to users.