 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterDeepResearch: Enabling Human-Agent Collaborative Information Seeking through Interactive Deep Research
Mar 13, 2026Deep research systems powered by LLM agents have transformed complex information seeking by automating the iterative retrieval, filtering, and synthesis of insights from massive-scale web sources. However, existing systems predominantly follow an autonomous "query-to-report" paradigm, limiting users to a passive role and failing to integrate their personal insights, contextual knowledge, and evolving research intents. This paper addresses the lack of human-in-the-loop collaboration in the agentic research process. Through a formative study, we identify that current systems hinder effective human-agent collaboration in terms of process observability, real-time steerability, and context navigation efficiency. Informed by these findings, we propose InterDeepResearch, an interactive deep research system backed by a dedicated research context management framework. The framework organizes research context into a hierarchical architecture with three levels (information, actions, and sessions), enabling dynamic context reduction to prevent LLM context exhaustion and cross-action backtracing for evidence provenance. Built upon this framework, the system interface integrates three coordinated views for visual sensemaking, and dedicated interaction mechanisms for interactive research context navigation. Evaluation on the Xbench-DeepSearch-v1 and Seal-0 benchmarks shows that InterDeepResearch achieves competitive performance compared to state-of-the-art deep research systems, while a formal user study demonstrates its effectiveness in supporting human-agent collaborative information seeking. Project page with system demo: https://github.com/bopan3/InterDeepResearch.
RAGExplorer: A Visual Analytics System for the Comparative Diagnosis of RAG Systems
Jan 19, 2026The advent of Retrieval-Augmented Generation (RAG) has significantly enhanced the ability of Large Language Models (LLMs) to produce factually accurate and up-to-date responses. However, the performance of a RAG system is not determined by a single component but emerges from a complex interplay of modular choices, such as embedding models and retrieval algorithms. This creates a vast and often opaque configuration space, making it challenging for developers to understand performance trade-offs and identify optimal designs. To address this challenge, we present RAGExplorer, a visual analytics system for the systematic comparison and diagnosis of RAG configurations. RAGExplorer guides users through a seamless macro-to-micro analytical workflow. Initially, it empowers developers to survey the performance landscape across numerous configurations, allowing for a high-level understanding of which design choices are most effective. For a deeper analysis, the system enables users to drill down into individual failure cases, investigate how differences in retrieved information contribute to errors, and interactively test hypotheses by manipulating the provided context to observe the resulting impact on the generated answer. We demonstrate the effectiveness of RAGExplorer through detailed case studies and user studies, validating its ability to empower developers in navigating the complex RAG design space. Our code and user guide are publicly available at https://github.com/Thymezzz/RAGExplorer.
V-Zero: Self-Improving Multimodal Reasoning with Zero Annotation
Jan 15, 2026Recent advances in multimodal learning have significantly enhanced the reasoning capabilities of vision-language models (VLMs). However, state-of-the-art approaches rely heavily on large-scale human-annotated datasets, which are costly and time-consuming to acquire. To overcome this limitation, we introduce V-Zero, a general post-training framework that facilitates self-improvement using exclusively unlabeled images. V-Zero establishes a co-evolutionary loop by instantiating two distinct roles: a Questioner and a Solver. The Questioner learns to synthesize high-quality, challenging questions by leveraging a dual-track reasoning reward that contrasts intuitive guesses with reasoned results. The Solver is optimized using pseudo-labels derived from majority voting over its own sampled responses. Both roles are trained iteratively via Group Relative Policy Optimization (GRPO), driving a cycle of mutual enhancement. Remarkably, without a single human annotation, V-Zero achieves consistent performance gains on Qwen2.5-VL-7B-Instruct, improving visual mathematical reasoning by +1.7 and general vision-centric by +2.6, demonstrating the potential of self-improvement in multimodal systems. Code is available at https://github.com/SatonoDia/V-Zero
IGenBench: Benchmarking the Reliability of Text-to-Infographic Generation
Jan 08, 2026Infographics are composite visual artifacts that combine data visualizations with textual and illustrative elements to communicate information. While recent text-to-image (T2I) models can generate aesthetically appealing images, their reliability in generating infographics remains unclear. Generated infographics may appear correct at first glance but contain easily overlooked issues, such as distorted data encoding or incorrect textual content. We present IGENBENCH, the first benchmark for evaluating the reliability of text-to-infographic generation, comprising 600 curated test cases spanning 30 infographic types. We design an automated evaluation framework that decomposes reliability verification into atomic yes/no questions based on a taxonomy of 10 question types. We employ multimodal large language models (MLLMs) to verify each question, yielding question-level accuracy (Q-ACC) and infographic-level accuracy (I-ACC). We comprehensively evaluate 10 state-of-the-art T2I models on IGENBENCH. Our systematic analysis reveals key insights for future model development: (i) a three-tier performance hierarchy with the top model achieving Q-ACC of 0.90 but I-ACC of only 0.49; (ii) data-related dimensions emerging as universal bottlenecks (e.g., Data Completeness: 0.21); and (iii) the challenge of achieving end-to-end correctness across all models. We release IGENBENCH at https://igen-bench.vercel.app/.
GenesisGeo: Technical Report
Sep 26, 2025We present GenesisGeo, an automated theorem prover in Euclidean geometry. We have open-sourced a large-scale geometry dataset of 21.8 million geometric problems, over 3 million of which contain auxiliary constructions. Specially, we significantly accelerate the symbolic deduction engine DDARN by 120x through theorem matching, combined with a C++ implementation of its core components. Furthermore, we build our neuro-symbolic prover, GenesisGeo, upon Qwen3-0.6B-Base, which solves 24 of 30 problems (IMO silver medal level) in the IMO-AG-30 benchmark using a single model, and achieves 26 problems (IMO gold medal level) with a dual-model ensemble.
VIS-Shepherd: Constructing Critic for LLM-based Data Visualization Generation
Jun 16, 2025Data visualization generation using Large Language Models (LLMs) has shown promising results but often produces suboptimal visualizations that require human intervention for improvement. In this work, we introduce VIS-Shepherd, a specialized Multimodal Large Language Model (MLLM)-based critic to evaluate and provide feedback for LLM-generated data visualizations. At the core of our approach is a framework to construct a high-quality visualization critique dataset, where we collect human-created visualization instances, synthesize corresponding LLM-generated instances, and construct high-quality critiques. We conduct both model-based automatic evaluation and human preference studies to evaluate the effectiveness of our approach. Our experiments show that even small (7B parameters) open-source MLLM models achieve substantial performance gains by leveraging our high-quality visualization critique dataset, reaching levels comparable to much larger open-source or even proprietary models. Our work demonstrates significant potential for MLLM-based automated visualization critique and indicates promising directions for enhancing LLM-based data visualization generation. Our project page: https://github.com/bopan3/VIS-Shepherd.
Don't Reinvent the Wheel: Efficient Instruction-Following Text Embedding based on Guided Space Transformation
May 30, 2025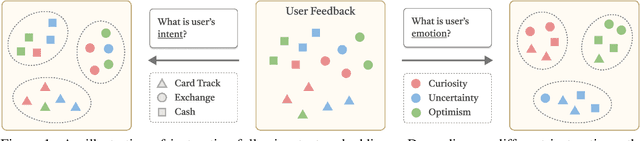
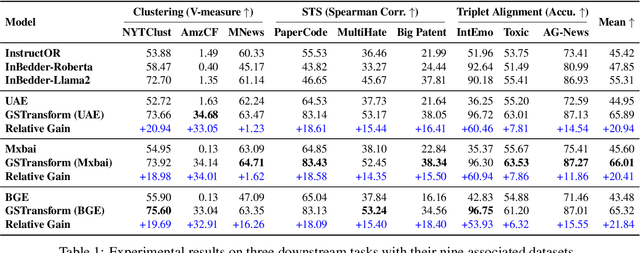
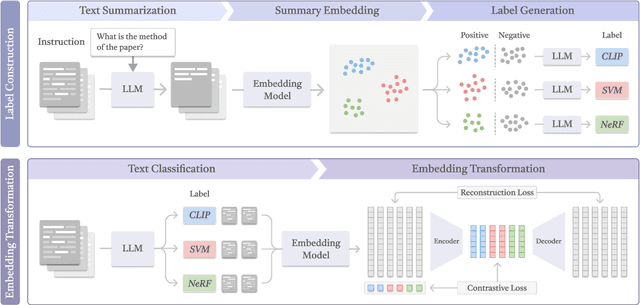

In this work, we investigate an important task named instruction-following text embedding, which generates dynamic text embeddings that adapt to user instructions, highlighting specific attributes of text. Despite recent advancements, existing approaches suffer from significant computational overhead, as they require re-encoding the entire corpus for each new instruction. To address this challenge, we propose GSTransform, a novel instruction-following text embedding framework based on Guided Space Transformation. Our key observation is that instruction-relevant information is inherently encoded in generic embeddings but remains underutilized. Instead of repeatedly encoding the corpus for each instruction, GSTransform is a lightweight transformation mechanism that adapts pre-computed embeddings in real time to align with user instructions, guided by a small amount of text data with instruction-focused label annotation. We conduct extensive experiments on three instruction-awareness downstream tasks across nine real-world datasets, demonstrating that GSTransform improves instruction-following text embedding quality over state-of-the-art methods while achieving dramatic speedups of 6~300x in real-time processing on large-scale datasets. The source code is available at https://github.com/YingchaojieFeng/GSTransform.
Exploring Multimodal Prompt for Visualization Authoring with Large Language Models
Apr 18, 2025



Recent advances in large language models (LLMs) have shown great potential in automating the process of visualization authoring through simple natural language utterances. However, instructing LLMs using natural language is limited in precision and expressiveness for conveying visualization intent, leading to misinterpretation and time-consuming iterations. To address these limitations, we conduct an empirical study to understand how LLMs interpret ambiguous or incomplete text prompts in the context of visualization authoring, and the conditions making LLMs misinterpret user intent. Informed by the findings, we introduce visual prompts as a complementary input modality to text prompts, which help clarify user intent and improve LLMs' interpretation abilities. To explore the potential of multimodal prompting in visualization authoring, we design VisPilot, which enables users to easily create visualizations using multimodal prompts, including text, sketches, and direct manipulations on existing visualizations. Through two case studies and a controlled user study, we demonstrate that VisPilot provides a more intuitive way to create visualizations without affecting the overall task efficiency compared to text-only prompting approaches. Furthermore, we analyze the impact of text and visual prompts in different visualization tasks. Our findings highlight the importance of multimodal prompting in improving the usability of LLMs for visualization authoring. We discuss design implications for future visualization systems and provide insights into how multimodal prompts can enhance human-AI collaboration in creative visualization tasks. All materials are available at https://OSF.IO/2QRAK.
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
Mar 13, 2025Large Language Models have demonstrated remarkable reasoning capability in complex textual tasks. However, multimodal reasoning, which requires integrating visual and textual information, remains a significant challenge. Existing visual-language models often struggle to effectively analyze and reason visual content, resulting in suboptimal performance on complex reasoning tasks. Moreover, the absence of comprehensive benchmarks hinders the accurate assessment of multimodal reasoning capabilities. In this paper, we introduce R1-Onevision, a multimodal reasoning model designed to bridge the gap between visual perception and deep reasoning. To achieve this, we propose a cross-modal reasoning pipeline that transforms images into formal textural representations, enabling precise language-based reasoning. Leveraging this pipeline, we construct the R1-Onevision dataset which provides detailed, step-by-step multimodal reasoning annotations across diverse domains. We further develop the R1-Onevision model through supervised fine-tuning and reinforcement learning to cultivate advanced reasoning and robust generalization abilities. To comprehensively evaluate multimodal reasoning performance across different grades, we introduce R1-Onevision-Bench, a benchmark aligned with human educational stages, covering exams from junior high school to university and beyond. Experimental results show that R1-Onevision achieves state-of-the-art performance, outperforming models such as GPT-4o and Qwen2.5-VL on multiple challenging multimodal reasoning benchmarks.
DataLab: A Unified Platform for LLM-Powered Business Intelligence
Dec 04, 2024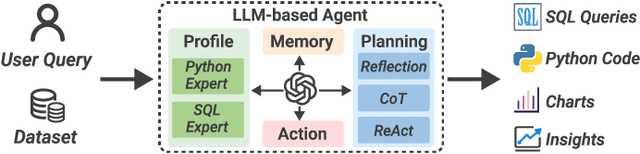
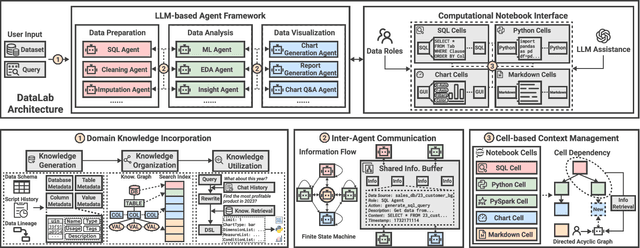
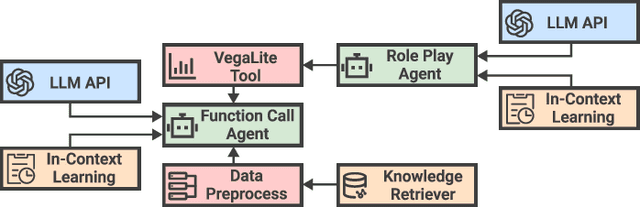
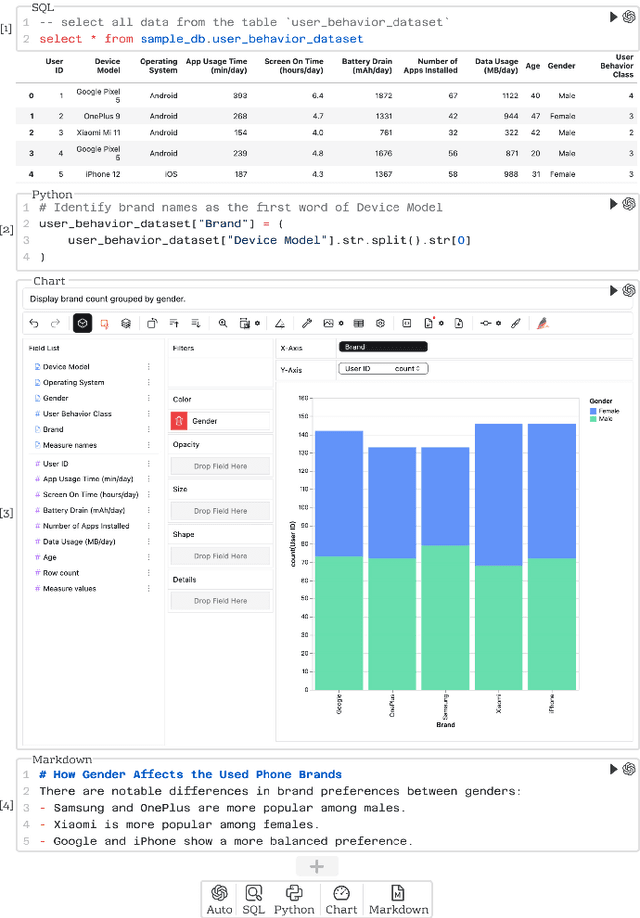
Business intelligence (BI) transforms large volumes of data within modern organizations into actionable insights for informed decision-making. Recently, large language model (LLM)-based agents have streamlined the BI workflow by automatically performing task planning, reasoning, and actions in executable environments based on natural language (NL) queries. However, existing approaches primarily focus on individual BI tasks such as NL2SQL and NL2VIS. The fragmentation of tasks across different data roles and tools lead to inefficiencies and potential errors due to the iterative and collaborative nature of BI. In this paper, we introduce DataLab, a unified BI platform that integrates a one-stop LLM-based agent framework with an augmented computational notebook interface. DataLab supports a wide range of BI tasks for different data roles by seamlessly combining LLM assistance with user customization within a single environment. To achieve this unification, we design a domain knowledge incorporation module tailored for enterprise-specific BI tasks, an inter-agent communication mechanism to facilitate information sharing across the BI workflow, and a cell-based context management strategy to enhance context utilization efficiency in BI notebooks. Extensive experiments demonstrate that DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks. Moreover, DataLab maintains high effectiveness and efficiency on real-world datasets from Tencent, achieving up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.