 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterDeepResearch: Enabling Human-Agent Collaborative Information Seeking through Interactive Deep Research
Mar 13, 2026Deep research systems powered by LLM agents have transformed complex information seeking by automating the iterative retrieval, filtering, and synthesis of insights from massive-scale web sources. However, existing systems predominantly follow an autonomous "query-to-report" paradigm, limiting users to a passive role and failing to integrate their personal insights, contextual knowledge, and evolving research intents. This paper addresses the lack of human-in-the-loop collaboration in the agentic research process. Through a formative study, we identify that current systems hinder effective human-agent collaboration in terms of process observability, real-time steerability, and context navigation efficiency. Informed by these findings, we propose InterDeepResearch, an interactive deep research system backed by a dedicated research context management framework. The framework organizes research context into a hierarchical architecture with three levels (information, actions, and sessions), enabling dynamic context reduction to prevent LLM context exhaustion and cross-action backtracing for evidence provenance. Built upon this framework, the system interface integrates three coordinated views for visual sensemaking, and dedicated interaction mechanisms for interactive research context navigation. Evaluation on the Xbench-DeepSearch-v1 and Seal-0 benchmarks shows that InterDeepResearch achieves competitive performance compared to state-of-the-art deep research systems, while a formal user study demonstrates its effectiveness in supporting human-agent collaborative information seeking. Project page with system demo: https://github.com/bopan3/InterDeepResearch.
RAGExplorer: A Visual Analytics System for the Comparative Diagnosis of RAG Systems
Jan 19, 2026The advent of Retrieval-Augmented Generation (RAG) has significantly enhanced the ability of Large Language Models (LLMs) to produce factually accurate and up-to-date responses. However, the performance of a RAG system is not determined by a single component but emerges from a complex interplay of modular choices, such as embedding models and retrieval algorithms. This creates a vast and often opaque configuration space, making it challenging for developers to understand performance trade-offs and identify optimal designs. To address this challenge, we present RAGExplorer, a visual analytics system for the systematic comparison and diagnosis of RAG configurations. RAGExplorer guides users through a seamless macro-to-micro analytical workflow. Initially, it empowers developers to survey the performance landscape across numerous configurations, allowing for a high-level understanding of which design choices are most effective. For a deeper analysis, the system enables users to drill down into individual failure cases, investigate how differences in retrieved information contribute to errors, and interactively test hypotheses by manipulating the provided context to observe the resulting impact on the generated answer. We demonstrate the effectiveness of RAGExplorer through detailed case studies and user studies, validating its ability to empower developers in navigating the complex RAG design space. Our code and user guide are publicly available at https://github.com/Thymezzz/RAGExplorer.
VIS-Shepherd: Constructing Critic for LLM-based Data Visualization Generation
Jun 16, 2025Data visualization generation using Large Language Models (LLMs) has shown promising results but often produces suboptimal visualizations that require human intervention for improvement. In this work, we introduce VIS-Shepherd, a specialized Multimodal Large Language Model (MLLM)-based critic to evaluate and provide feedback for LLM-generated data visualizations. At the core of our approach is a framework to construct a high-quality visualization critique dataset, where we collect human-created visualization instances, synthesize corresponding LLM-generated instances, and construct high-quality critiques. We conduct both model-based automatic evaluation and human preference studies to evaluate the effectiveness of our approach. Our experiments show that even small (7B parameters) open-source MLLM models achieve substantial performance gains by leveraging our high-quality visualization critique dataset, reaching levels comparable to much larger open-source or even proprietary models. Our work demonstrates significant potential for MLLM-based automated visualization critique and indicates promising directions for enhancing LLM-based data visualization generation. Our project page: https://github.com/bopan3/VIS-Shepherd.
Exploring Multimodal Prompt for Visualization Authoring with Large Language Models
Apr 18, 2025



Recent advances in large language models (LLMs) have shown great potential in automating the process of visualization authoring through simple natural language utterances. However, instructing LLMs using natural language is limited in precision and expressiveness for conveying visualization intent, leading to misinterpretation and time-consuming iterations. To address these limitations, we conduct an empirical study to understand how LLMs interpret ambiguous or incomplete text prompts in the context of visualization authoring, and the conditions making LLMs misinterpret user intent. Informed by the findings, we introduce visual prompts as a complementary input modality to text prompts, which help clarify user intent and improve LLMs' interpretation abilities. To explore the potential of multimodal prompting in visualization authoring, we design VisPilot, which enables users to easily create visualizations using multimodal prompts, including text, sketches, and direct manipulations on existing visualizations. Through two case studies and a controlled user study, we demonstrate that VisPilot provides a more intuitive way to create visualizations without affecting the overall task efficiency compared to text-only prompting approaches. Furthermore, we analyze the impact of text and visual prompts in different visualization tasks. Our findings highlight the importance of multimodal prompting in improving the usability of LLMs for visualization authoring. We discuss design implications for future visualization systems and provide insights into how multimodal prompts can enhance human-AI collaboration in creative visualization tasks. All materials are available at https://OSF.IO/2QRAK.
Rethinking Large Language Model Architectures for Sequential Recommendations
Feb 14, 2024



Recently, sequential recommendation has been adapted to the LLM paradigm to enjoy the power of LLMs. LLM-based methods usually formulate recommendation information into natural language and the model is trained to predict the next item in an auto-regressive manner. Despite their notable success, the substantial computational overhead of inference poses a significant obstacle to their real-world applicability. In this work, we endeavor to streamline existing LLM-based recommendation models and propose a simple yet highly effective model Lite-LLM4Rec. The primary goal of Lite-LLM4Rec is to achieve efficient inference for the sequential recommendation task. Lite-LLM4Rec circumvents the beam search decoding by using a straight item projection head for ranking scores generation. This design stems from our empirical observation that beam search decoding is ultimately unnecessary for sequential recommendations. Additionally, Lite-LLM4Rec introduces a hierarchical LLM structure tailored to efficiently handle the extensive contextual information associated with items, thereby reducing computational overhead while enjoying the capabilities of LLMs. Experiments on three publicly available datasets corroborate the effectiveness of Lite-LLM4Rec in both performance and inference efficiency (notably 46.8% performance improvement and 97.28% efficiency improvement on ML-1m) over existing LLM-based methods. Our implementations will be open sourced.
CaSP: Class-agnostic Semi-Supervised Pretraining for Detection and Segmentation
Dec 09, 2021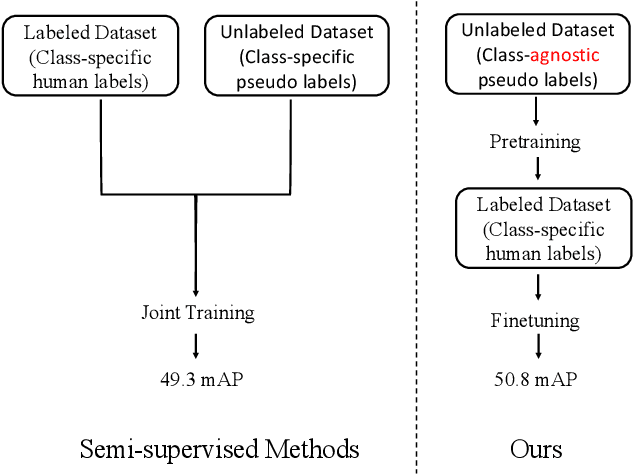
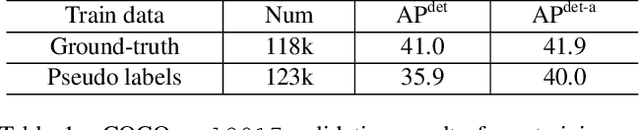
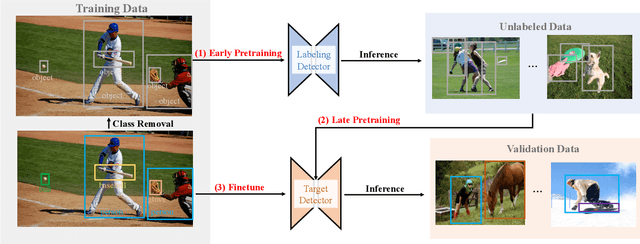
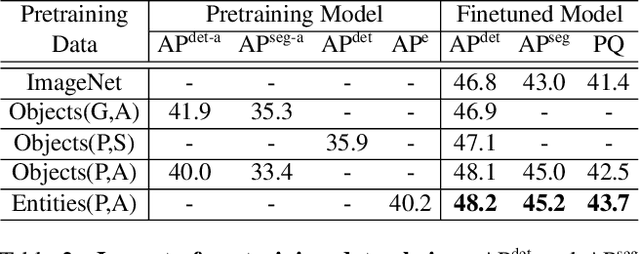
To improve instance-level detection/segmentation performance, existing self-supervised and semi-supervised methods extract either very task-unrelated or very task-specific training signals from unlabeled data. We argue that these two approaches, at the two extreme ends of the task-specificity spectrum, are suboptimal for the task performance. Utilizing too little task-specific training signals causes underfitting to the ground-truth labels of downstream tasks, while the opposite causes overfitting to the ground-truth labels. To this end, we propose a novel Class-agnostic Semi-supervised Pretraining (CaSP) framework to achieve a more favorable task-specificity balance in extracting training signals from unlabeled data. Compared to semi-supervised learning, CaSP reduces the task specificity in training signals by ignoring class information in the pseudo labels and having a separate pretraining stage that uses only task-unrelated unlabeled data. On the other hand, CaSP preserves the right amount of task specificity by leveraging box/mask-level pseudo labels. As a result, our pretrained model can better avoid underfitting/overfitting to ground-truth labels when finetuned on the downstream task. Using 3.6M unlabeled data, we achieve a remarkable performance gain of 4.7% over ImageNet-pretrained baseline on object detection. Our pretrained model also demonstrates excellent transferability to other detection and segmentation tasks/frameworks.
TAG: Toward Accurate Social Media Content Tagging with a Concept Graph
Oct 24, 2021
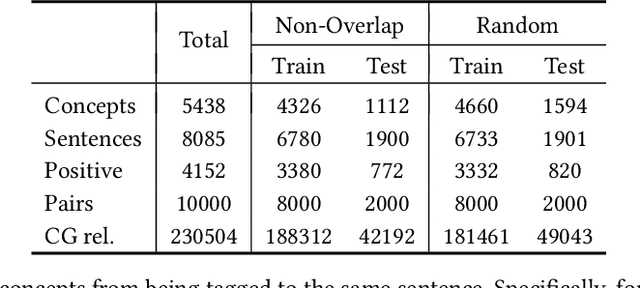

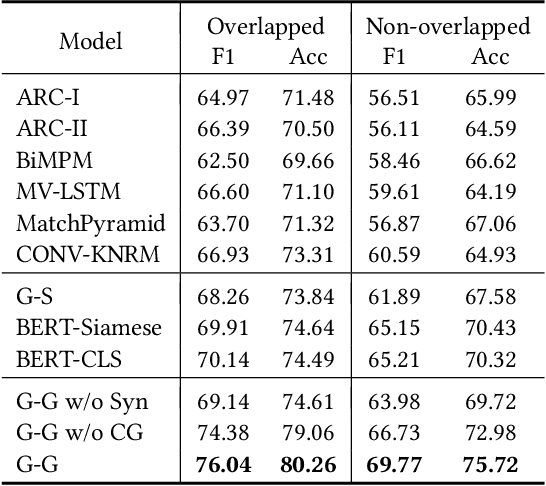
Although conceptualization has been widely studied in semantics and knowledge representation, it is still challenging to find the most accurate concept phrases to characterize the main idea of a text snippet on the fast-growing social media. This is partly attributed to the fact that most knowledge bases contain general terms of the world, such as trees and cars, which do not have the defining power or are not interesting enough to social media app users. Another reason is that the intricacy of natural language allows the use of tense, negation and grammar to change the logic or emphasis of language, thus conveying completely different meanings. In this paper, we present TAG, a high-quality concept matching dataset consisting of 10,000 labeled pairs of fine-grained concepts and web-styled natural language sentences, mined from the open-domain social media. The concepts we consider represent the trending interests of online users. Associated with TAG is a concept graph of these fine-grained concepts and entities to provide the structural context information. We evaluate a wide range of popular neural text matching models as well as pre-trained language models on TAG, and point out their insufficiency to tag social media content with the most appropriate concept. We further propose a novel graph-graph matching method that demonstrates superior abstraction and generalization performance by better utilizing both the structural context in the concept graph and logic interactions between semantic units in the sentence via syntactic dependency parsing. We open-source both the TAG dataset and the proposed methods to facilitate further research.
GIANT: Scalable Creation of a Web-scale Ontology
Apr 05, 2020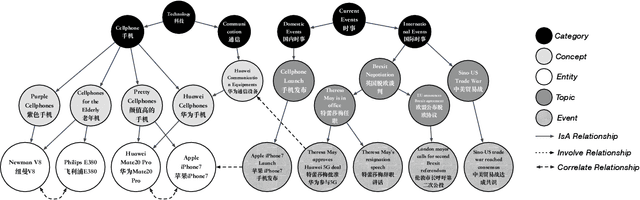

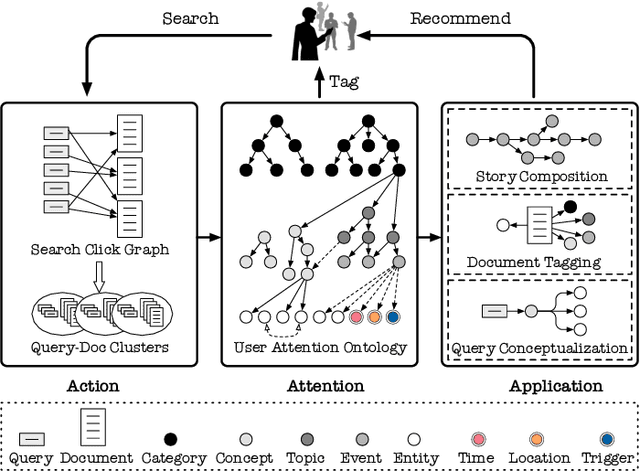
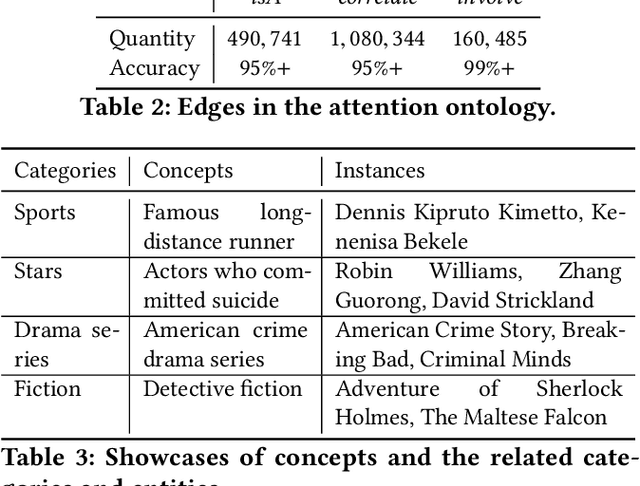
Understanding what online users may pay attention to is key to content recommendation and search services. These services will benefit from a highly structured and web-scale ontology of entities, concepts, events, topics and categories. While existing knowledge bases and taxonomies embody a large volume of entities and categories, we argue that they fail to discover properly grained concepts, events and topics in the language style of online population. Neither is a logically structured ontology maintained among these notions. In this paper, we present GIANT, a mechanism to construct a user-centered, web-scale, structured ontology, containing a large number of natural language phrases conforming to user attentions at various granularities, mined from a vast volume of web documents and search click graphs. Various types of edges are also constructed to maintain a hierarchy in the ontology. We present our graph-neural-network-based techniques used in GIANT, and evaluate the proposed methods as compared to a variety of baselines. GIANT has produced the Attention Ontology, which has been deployed in various Tencent applications involving over a billion users. Online A/B testing performed on Tencent QQ Browser shows that Attention Ontology can significantly improve click-through rates in news recommendation.
A Survey on Social Media Anomaly Detection
Feb 17, 2016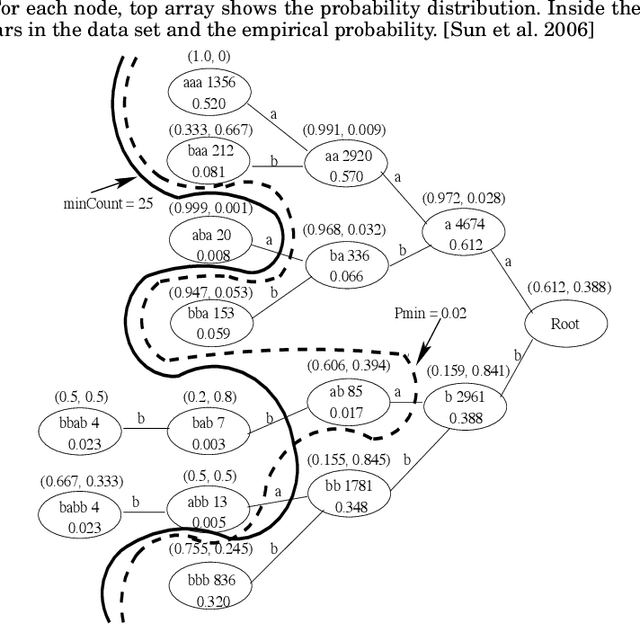
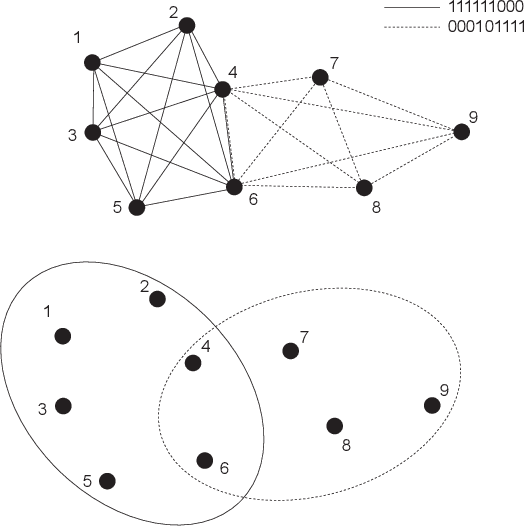
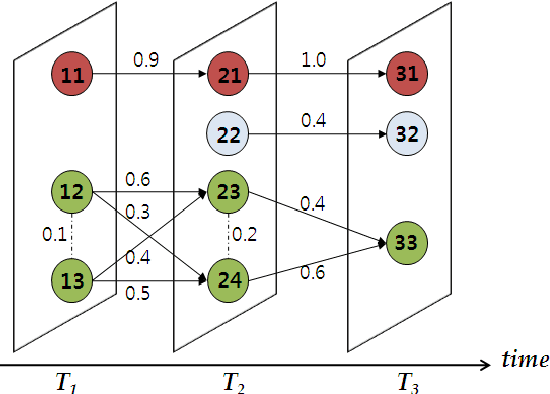
Social media anomaly detection is of critical importance to prevent malicious activities such as bullying, terrorist attack planning, and fraud information dissemination. With the recent popularity of social media, new types of anomalous behaviors arise, causing concerns from various parties. While a large amount of work have been dedicated to traditional anomaly detection problems, we observe a surge of research interests in the new realm of social media anomaly detection. In this paper, we present a survey on existing approaches to address this problem. We focus on the new type of anomalous phenomena in the social media and review the recent developed techniques to detect those special types of anomalies. We provide a general overview of the problem domain, common formulations, existing methodologies and potential directions. With this work, we hope to call out the attention from the research community on this challenging problem and open up new directions that we can contribute in the future.