 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAG: Toward Accurate Social Media Content Tagging with a Concept Graph
Paper and Code

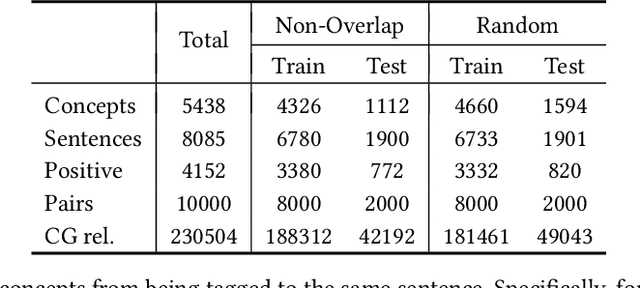

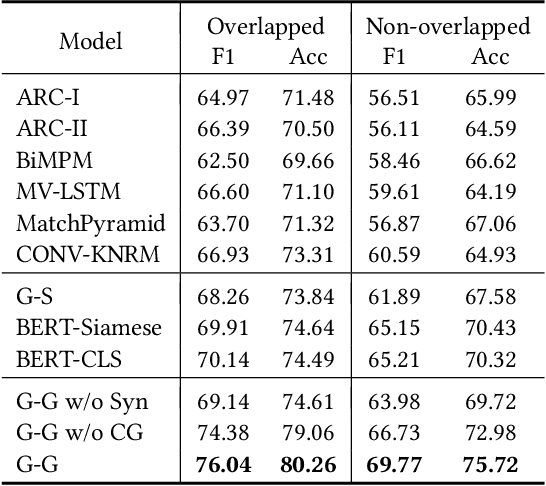
Although conceptualization has been widely studied in semantics and knowledge representation, it is still challenging to find the most accurate concept phrases to characterize the main idea of a text snippet on the fast-growing social media. This is partly attributed to the fact that most knowledge bases contain general terms of the world, such as trees and cars, which do not have the defining power or are not interesting enough to social media app users. Another reason is that the intricacy of natural language allows the use of tense, negation and grammar to change the logic or emphasis of language, thus conveying completely different meanings. In this paper, we present TAG, a high-quality concept matching dataset consisting of 10,000 labeled pairs of fine-grained concepts and web-styled natural language sentences, mined from the open-domain social media. The concepts we consider represent the trending interests of online users. Associated with TAG is a concept graph of these fine-grained concepts and entities to provide the structural context information. We evaluate a wide range of popular neural text matching models as well as pre-trained language models on TAG, and point out their insufficiency to tag social media content with the most appropriate concept. We further propose a novel graph-graph matching method that demonstrates superior abstraction and generalization performance by better utilizing both the structural context in the concept graph and logic interactions between semantic units in the sentence via syntactic dependency parsing. We open-source both the TAG dataset and the proposed methods to facilitate further research.