 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIGenBench: Benchmarking the Reliability of Text-to-Infographic Generation
Jan 08, 2026Infographics are composite visual artifacts that combine data visualizations with textual and illustrative elements to communicate information. While recent text-to-image (T2I) models can generate aesthetically appealing images, their reliability in generating infographics remains unclear. Generated infographics may appear correct at first glance but contain easily overlooked issues, such as distorted data encoding or incorrect textual content. We present IGENBENCH, the first benchmark for evaluating the reliability of text-to-infographic generation, comprising 600 curated test cases spanning 30 infographic types. We design an automated evaluation framework that decomposes reliability verification into atomic yes/no questions based on a taxonomy of 10 question types. We employ multimodal large language models (MLLMs) to verify each question, yielding question-level accuracy (Q-ACC) and infographic-level accuracy (I-ACC). We comprehensively evaluate 10 state-of-the-art T2I models on IGENBENCH. Our systematic analysis reveals key insights for future model development: (i) a three-tier performance hierarchy with the top model achieving Q-ACC of 0.90 but I-ACC of only 0.49; (ii) data-related dimensions emerging as universal bottlenecks (e.g., Data Completeness: 0.21); and (iii) the challenge of achieving end-to-end correctness across all models. We release IGENBENCH at https://igen-bench.vercel.app/.
VIS-Shepherd: Constructing Critic for LLM-based Data Visualization Generation
Jun 16, 2025Data visualization generation using Large Language Models (LLMs) has shown promising results but often produces suboptimal visualizations that require human intervention for improvement. In this work, we introduce VIS-Shepherd, a specialized Multimodal Large Language Model (MLLM)-based critic to evaluate and provide feedback for LLM-generated data visualizations. At the core of our approach is a framework to construct a high-quality visualization critique dataset, where we collect human-created visualization instances, synthesize corresponding LLM-generated instances, and construct high-quality critiques. We conduct both model-based automatic evaluation and human preference studies to evaluate the effectiveness of our approach. Our experiments show that even small (7B parameters) open-source MLLM models achieve substantial performance gains by leveraging our high-quality visualization critique dataset, reaching levels comparable to much larger open-source or even proprietary models. Our work demonstrates significant potential for MLLM-based automated visualization critique and indicates promising directions for enhancing LLM-based data visualization generation. Our project page: https://github.com/bopan3/VIS-Shepherd.
SCORPIO: Serving the Right Requests at the Right Time for Heterogeneous SLOs in LLM Inference
May 29, 2025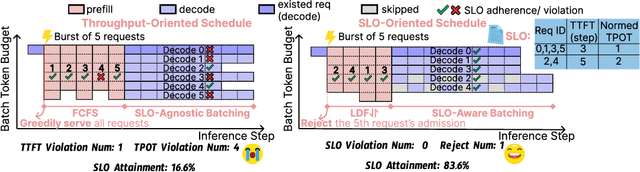
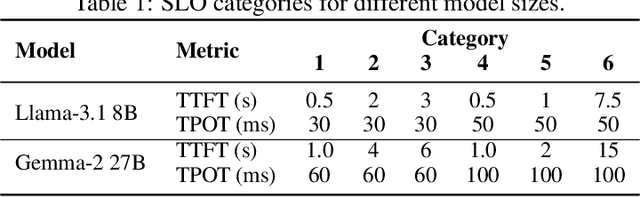
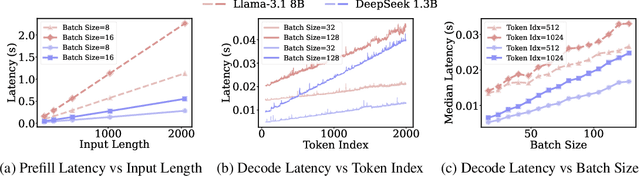
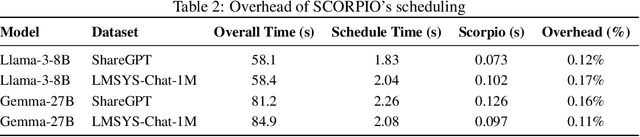
Existing Large Language Model (LLM) serving systems prioritize maximum throughput. They often neglect Service Level Objectives (SLOs) such as Time to First Token (TTFT) and Time Per Output Token (TPOT), which leads to suboptimal SLO attainment. This paper introduces SCORPIO, an SLO-oriented LLM serving system designed to maximize system goodput and SLO attainment for workloads with heterogeneous SLOs. Our core insight is to exploit SLO heterogeneity for adaptive scheduling across admission control, queue management, and batch selection. SCORPIO features a TTFT Guard, which employs least-deadline-first reordering and rejects unattainable requests, and a TPOT Guard, which utilizes a VBS-based admission control and a novel credit-based batching mechanism. Both guards are supported by a predictive module. Evaluations demonstrate that SCORPIO improves system goodput by up to 14.4X and SLO adherence by up to 46.5% compared to state-of-the-art baselines.
Exploring Multimodal Prompt for Visualization Authoring with Large Language Models
Apr 18, 2025



Recent advances in large language models (LLMs) have shown great potential in automating the process of visualization authoring through simple natural language utterances. However, instructing LLMs using natural language is limited in precision and expressiveness for conveying visualization intent, leading to misinterpretation and time-consuming iterations. To address these limitations, we conduct an empirical study to understand how LLMs interpret ambiguous or incomplete text prompts in the context of visualization authoring, and the conditions making LLMs misinterpret user intent. Informed by the findings, we introduce visual prompts as a complementary input modality to text prompts, which help clarify user intent and improve LLMs' interpretation abilities. To explore the potential of multimodal prompting in visualization authoring, we design VisPilot, which enables users to easily create visualizations using multimodal prompts, including text, sketches, and direct manipulations on existing visualizations. Through two case studies and a controlled user study, we demonstrate that VisPilot provides a more intuitive way to create visualizations without affecting the overall task efficiency compared to text-only prompting approaches. Furthermore, we analyze the impact of text and visual prompts in different visualization tasks. Our findings highlight the importance of multimodal prompting in improving the usability of LLMs for visualization authoring. We discuss design implications for future visualization systems and provide insights into how multimodal prompts can enhance human-AI collaboration in creative visualization tasks. All materials are available at https://OSF.IO/2QRAK.
DataLab: A Unified Platform for LLM-Powered Business Intelligence
Dec 04, 2024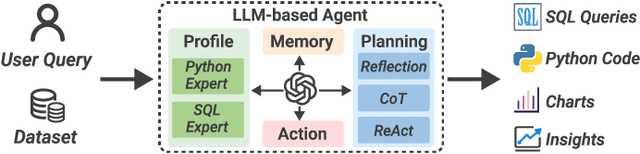
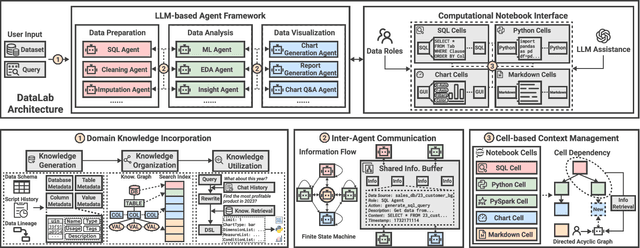
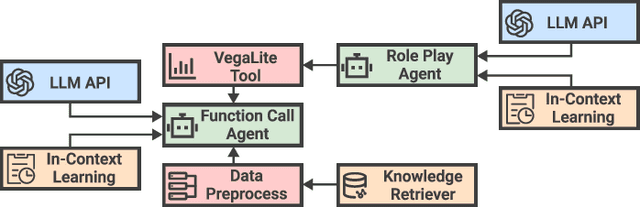
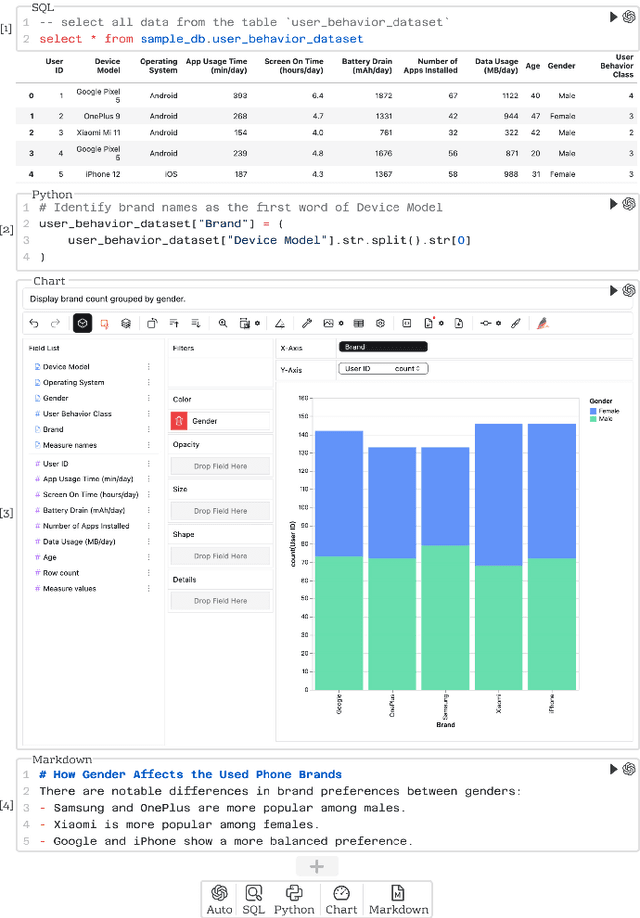
Business intelligence (BI) transforms large volumes of data within modern organizations into actionable insights for informed decision-making. Recently, large language model (LLM)-based agents have streamlined the BI workflow by automatically performing task planning, reasoning, and actions in executable environments based on natural language (NL) queries. However, existing approaches primarily focus on individual BI tasks such as NL2SQL and NL2VIS. The fragmentation of tasks across different data roles and tools lead to inefficiencies and potential errors due to the iterative and collaborative nature of BI. In this paper, we introduce DataLab, a unified BI platform that integrates a one-stop LLM-based agent framework with an augmented computational notebook interface. DataLab supports a wide range of BI tasks for different data roles by seamlessly combining LLM assistance with user customization within a single environment. To achieve this unification, we design a domain knowledge incorporation module tailored for enterprise-specific BI tasks, an inter-agent communication mechanism to facilitate information sharing across the BI workflow, and a cell-based context management strategy to enhance context utilization efficiency in BI notebooks. Extensive experiments demonstrate that DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks. Moreover, DataLab maintains high effectiveness and efficiency on real-world datasets from Tencent, achieving up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.
DataLab: A Unifed Platform for LLM-Powered Business Intelligence
Dec 03, 2024Business intelligence (BI) transforms large volumes of data within modern organizations into actionable insights for informed decision-making. Recently, large language model (LLM)-based agents have streamlined the BI workflow by automatically performing task planning, reasoning, and actions in executable environments based on natural language (NL) queries. However, existing approaches primarily focus on individual BI tasks such as NL2SQL and NL2VIS. The fragmentation of tasks across different data roles and tools lead to inefficiencies and potential errors due to the iterative and collaborative nature of BI. In this paper, we introduce DataLab, a unified BI platform that integrates a one-stop LLM-based agent framework with an augmented computational notebook interface. DataLab supports a wide range of BI tasks for different data roles by seamlessly combining LLM assistance with user customization within a single environment. To achieve this unification, we design a domain knowledge incorporation module tailored for enterprise-specific BI tasks, an inter-agent communication mechanism to facilitate information sharing across the BI workflow, and a cell-based context management strategy to enhance context utilization efficiency in BI notebooks. Extensive experiments demonstrate that DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks. Moreover, DataLab maintains high effectiveness and efficiency on real-world datasets from Tencent, achieving up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.