 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-CAISR: Stage-Adaptive and Conflict-Aware Incremental Sequential Recommendation
Feb 09, 2026Sequential recommendation (SR) aims to predict a user's next action by learning from their historical interaction sequences. In real-world applications, these models require periodic updates to adapt to new interactions and evolving user preferences. While incremental learning methods facilitate these updates, they face significant challenges. Replay-based approaches incur high memory and computational costs, and regularization-based methods often struggle to discard outdated or conflicting knowledge. To overcome these challenges, we propose SA-CAISR, a Stage-Adaptive and Conflict-Aware Incremental Sequential Recommendation framework. As a buffer-free framework, SA-CAISR operates using only the old model and new data, directly addressing the high costs of replay-based techniques. SA-CAISR introduces a novel Fisher-weighted knowledge-screening mechanism that dynamically identifies outdated knowledge by estimating parameter-level conflicts between the old model and new data, allowing our approach to selectively remove obsolete knowledge while preserving compatible historical patterns. This dynamic balance between stability and adaptability allows our method to achieve a new state-of-the-art performance in incremental SR. Specifically, SA-CAISR improves Recall@20 by 2.0%, MRR@20 by 1.2%, and NDCG@20 by 1.4% on average across datasets, while reducing memory usage by 97.5% and training time by 46.9% compared to the best baselines. This efficiency allows real-world systems to rapidly update user profiles with minimal computational overhead, ensuring more timely and accurate recommendations.
Uncovering Selective State Space Model's Capabilities in Lifelong Sequential Recommendation
Mar 25, 2024



Sequential Recommenders have been widely applied in various online services, aiming to model users' dynamic interests from their sequential interactions. With users increasingly engaging with online platforms, vast amounts of lifelong user behavioral sequences have been generated. However, existing sequential recommender models often struggle to handle such lifelong sequences. The primary challenges stem from computational complexity and the ability to capture long-range dependencies within the sequence. Recently, a state space model featuring a selective mechanism (i.e., Mamba) has emerged. In this work, we investigate the performance of Mamba for lifelong sequential recommendation (i.e., length>=2k). More specifically, we leverage the Mamba block to model lifelong user sequences selectively. We conduct extensive experiments to evaluate the performance of representative sequential recommendation models in the setting of lifelong sequences. Experiments on two real-world datasets demonstrate the superiority of Mamba. We found that RecMamba achieves performance comparable to the representative model while significantly reducing training duration by approximately 70% and memory costs by 80%. Codes and data are available at \url{https://github.com/nancheng58/RecMamba}.
Rethinking Large Language Model Architectures for Sequential Recommendations
Feb 14, 2024



Recently, sequential recommendation has been adapted to the LLM paradigm to enjoy the power of LLMs. LLM-based methods usually formulate recommendation information into natural language and the model is trained to predict the next item in an auto-regressive manner. Despite their notable success, the substantial computational overhead of inference poses a significant obstacle to their real-world applicability. In this work, we endeavor to streamline existing LLM-based recommendation models and propose a simple yet highly effective model Lite-LLM4Rec. The primary goal of Lite-LLM4Rec is to achieve efficient inference for the sequential recommendation task. Lite-LLM4Rec circumvents the beam search decoding by using a straight item projection head for ranking scores generation. This design stems from our empirical observation that beam search decoding is ultimately unnecessary for sequential recommendations. Additionally, Lite-LLM4Rec introduces a hierarchical LLM structure tailored to efficiently handle the extensive contextual information associated with items, thereby reducing computational overhead while enjoying the capabilities of LLMs. Experiments on three publicly available datasets corroborate the effectiveness of Lite-LLM4Rec in both performance and inference efficiency (notably 46.8% performance improvement and 97.28% efficiency improvement on ML-1m) over existing LLM-based methods. Our implementations will be open sourced.
Improving Implicit Feedback-Based Recommendation through Multi-Behavior Alignment
May 09, 2023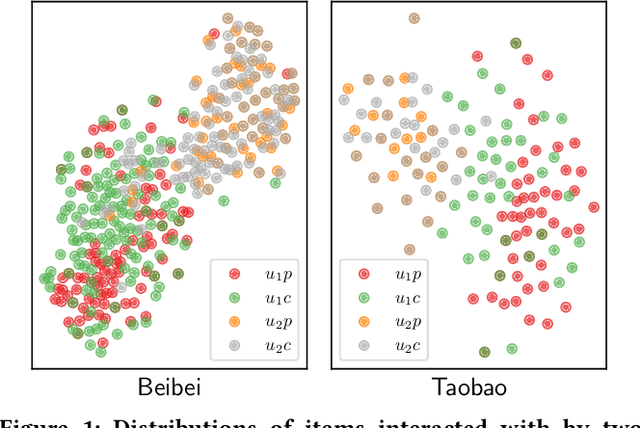
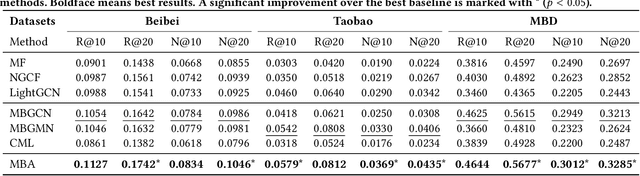
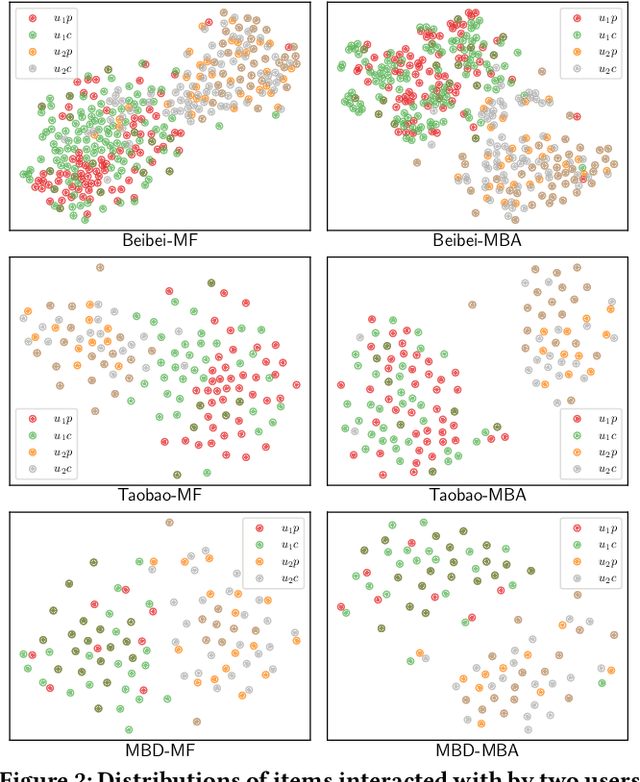
Recommender systems that learn from implicit feedback often use large volumes of a single type of implicit user feedback, such as clicks, to enhance the prediction of sparse target behavior such as purchases. Using multiple types of implicit user feedback for such target behavior prediction purposes is still an open question. Existing studies that attempted to learn from multiple types of user behavior often fail to: (i) learn universal and accurate user preferences from different behavioral data distributions, and (ii) overcome the noise and bias in observed implicit user feedback. To address the above problems, we propose multi-behavior alignment (MBA), a novel recommendation framework that learns from implicit feedback by using multiple types of behavioral data. We conjecture that multiple types of behavior from the same user (e.g., clicks and purchases) should reflect similar preferences of that user. To this end, we regard the underlying universal user preferences as a latent variable. The variable is inferred by maximizing the likelihood of multiple observed behavioral data distributions and, at the same time, minimizing the Kullback-Leibler divergence (KL-divergence) between user models learned from auxiliary behavior (such as clicks or views) and the target behavior separately. MBA infers universal user preferences from multi-behavior data and performs data denoising to enable effective knowledge transfer. We conduct experiments on three datasets, including a dataset collected from an operational e-commerce platform. Empirical results demonstrate the effectiveness of our proposed method in utilizing multiple types of behavioral data to enhance the prediction of the target behavior.
On the User Behavior Leakage from Recommender Exposure
Oct 16, 2022
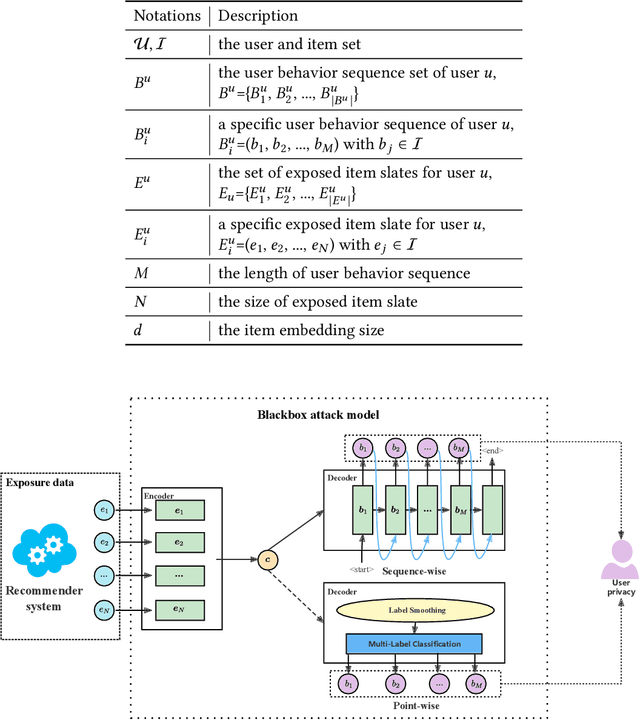
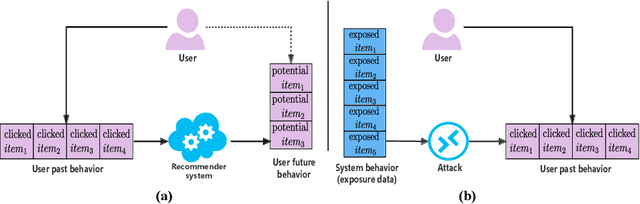
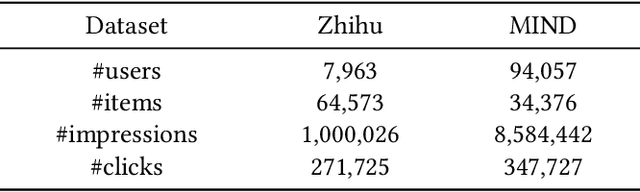
Modern recommender systems are trained to predict users potential future interactions from users historical behavior data. During the interaction process, despite the data coming from the user side recommender systems also generate exposure data to provide users with personalized recommendation slates. Compared with the sparse user behavior data, the system exposure data is much larger in volume since only very few exposed items would be clicked by the user. Besides, the users historical behavior data is privacy sensitive and is commonly protected with careful access authorization. However, the large volume of recommender exposure data usually receives less attention and could be accessed within a relatively larger scope of various information seekers. In this paper, we investigate the problem of user behavior leakage in recommender systems. We show that the privacy sensitive user past behavior data can be inferred through the modeling of system exposure. Besides, one can infer which items the user have clicked just from the observation of current system exposure for this user. Given the fact that system exposure data could be widely accessed from a relatively larger scope, we believe that the user past behavior privacy has a high risk of leakage in recommender systems. More precisely, we conduct an attack model whose input is the current recommended item slate (i.e., system exposure) for the user while the output is the user's historical behavior. Experimental results on two real-world datasets indicate a great danger of user behavior leakage. To address the risk, we propose a two-stage privacy-protection mechanism which firstly selects a subset of items from the exposure slate and then replaces the selected items with uniform or popularity-based exposure. Experimental evaluation reveals a trade-off effect between the recommendation accuracy and the privacy disclosure risk.