 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Selective State Space Model's Capabilities in Lifelong Sequential Recommendation
Mar 25, 2024



Sequential Recommenders have been widely applied in various online services, aiming to model users' dynamic interests from their sequential interactions. With users increasingly engaging with online platforms, vast amounts of lifelong user behavioral sequences have been generated. However, existing sequential recommender models often struggle to handle such lifelong sequences. The primary challenges stem from computational complexity and the ability to capture long-range dependencies within the sequence. Recently, a state space model featuring a selective mechanism (i.e., Mamba) has emerged. In this work, we investigate the performance of Mamba for lifelong sequential recommendation (i.e., length>=2k). More specifically, we leverage the Mamba block to model lifelong user sequences selectively. We conduct extensive experiments to evaluate the performance of representative sequential recommendation models in the setting of lifelong sequences. Experiments on two real-world datasets demonstrate the superiority of Mamba. We found that RecMamba achieves performance comparable to the representative model while significantly reducing training duration by approximately 70% and memory costs by 80%. Codes and data are available at \url{https://github.com/nancheng58/RecMamba}.
Improving Transformer-based Sequential Recommenders through Preference Editing
Jun 23, 2021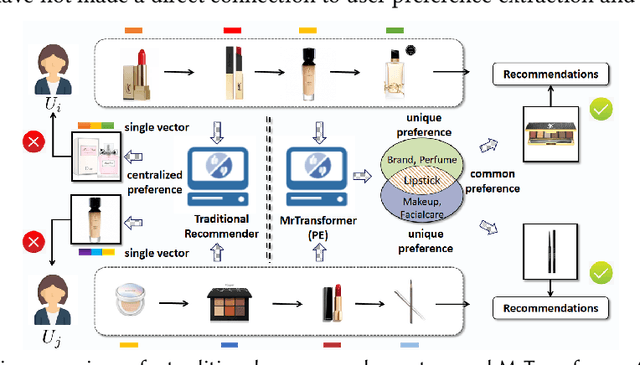
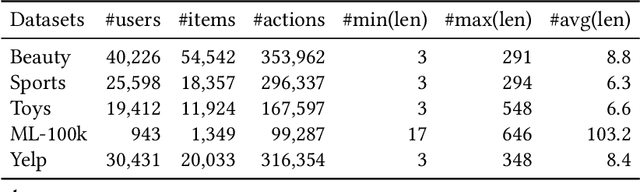
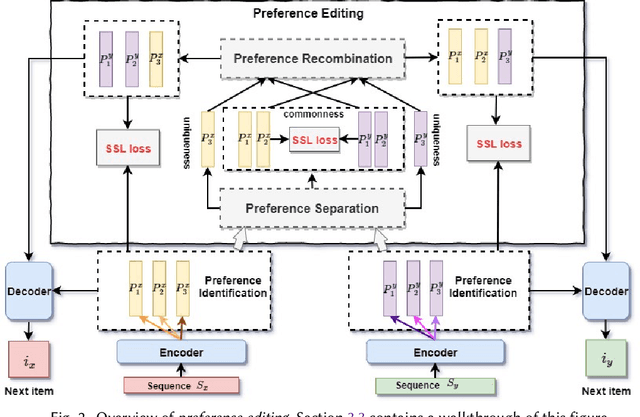
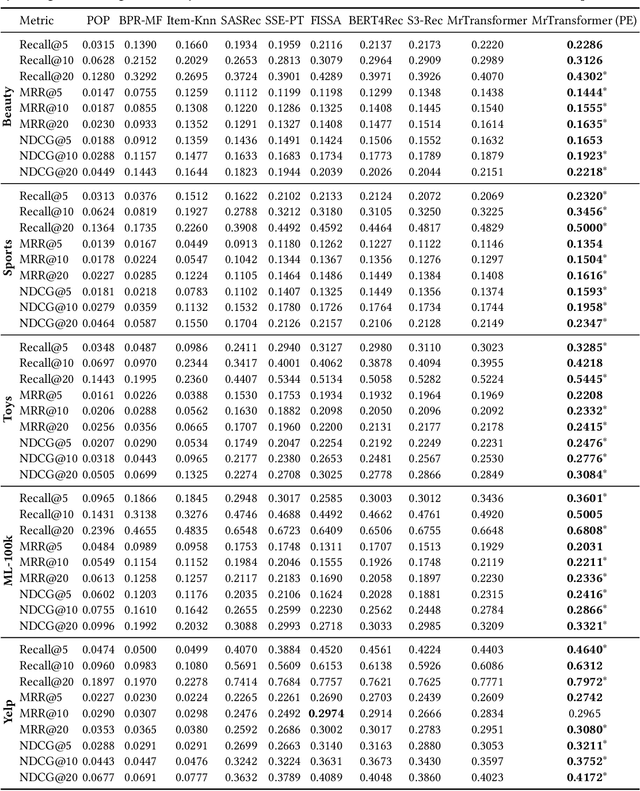
One of the key challenges in Sequential Recommendation (SR) is how to extract and represent user preferences. Traditional SR methods rely on the next item as the supervision signal to guide preference extraction and representation. We propose a novel learning strategy, named preference editing. The idea is to force the SR model to discriminate the common and unique preferences in different sequences of interactions between users and the recommender system. By doing so, the SR model is able to learn how to identify common and unique user preferences, and thereby do better user preference extraction and representation. We propose a transformer based SR model, named MrTransformer (Multi-preference Transformer), that concatenates some special tokens in front of the sequence to represent multiple user preferences and makes sure they capture different aspects through a preference coverage mechanism. Then, we devise a preference editing-based self-supervised learning mechanism for training MrTransformer which contains two main operations: preference separation and preference recombination. The former separates the common and unique user preferences for a given pair of sequences. The latter swaps the common preferences to obtain recombined user preferences for each sequence. Based on the preference separation and preference recombination operations, we define two types of SSL loss that require that the recombined preferences are similar to the original ones, and the common preferences are close to each other. We carry out extensive experiments on two benchmark datasets. MrTransformer with preference editing significantly outperforms state-of-the-art SR methods in terms of Recall, MRR and NDCG. We find that long sequences whose user preferences are harder to extract and represent benefit most from preference editing.