 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaying More Attention to Self-attention: Improving Pre-trained Language Models via Attention Guiding
Apr 06, 2022
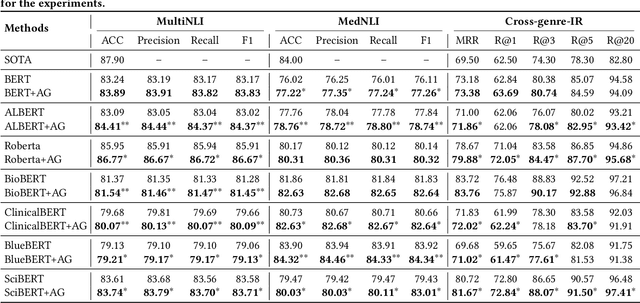
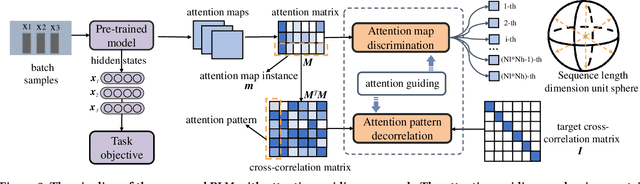
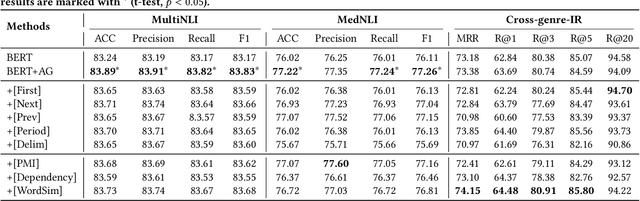
Pre-trained language models (PLM) have demonstrated their effectiveness for a broad range of information retrieval and natural language processing tasks. As the core part of PLM, multi-head self-attention is appealing for its ability to jointly attend to information from different positions. However, researchers have found that PLM always exhibits fixed attention patterns regardless of the input (e.g., excessively paying attention to [CLS] or [SEP]), which we argue might neglect important information in the other positions. In this work, we propose a simple yet effective attention guiding mechanism to improve the performance of PLM by encouraging attention towards the established goals. Specifically, we propose two kinds of attention guiding methods, i.e., map discrimination guiding (MDG) and attention pattern decorrelation guiding (PDG). The former definitely encourages the diversity among multiple self-attention heads to jointly attend to information from different representation subspaces, while the latter encourages self-attention to attend to as many different positions of the input as possible. We conduct experiments with multiple general pre-trained models (i.e., BERT, ALBERT, and Roberta) and domain-specific pre-trained models (i.e., BioBERT, ClinicalBERT, BlueBert, and SciBERT) on three benchmark datasets (i.e., MultiNLI, MedNLI, and Cross-genre-IR). Extensive experimental results demonstrate that our proposed MDG and PDG bring stable performance improvements on all datasets with high efficiency and low cost.
M^2-MedDialog: A Dataset and Benchmarks for Multi-domain Multi-service Medical Dialogues
Sep 08, 2021
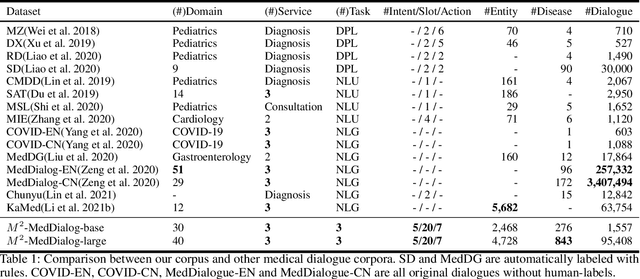
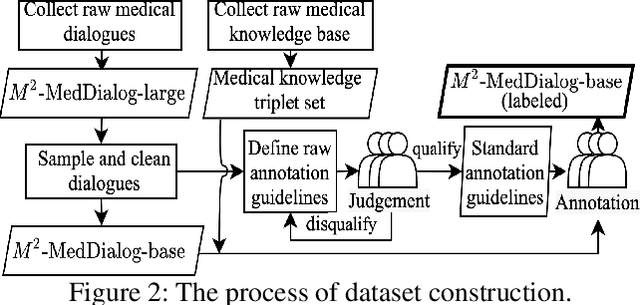
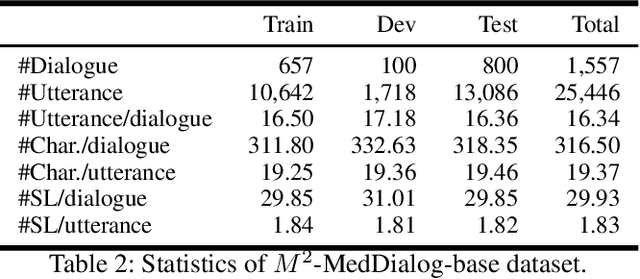
Medical dialogue systems (MDSs) aim to assist doctors and patients with a range of professional medical services, i.e., diagnosis, consultation, and treatment. However, one-stop MDS is still unexplored because: (1) no dataset has so large-scale dialogues contains both multiple medical services and fine-grained medical labels (i.e., intents, slots, values); (2) no model has addressed a MDS based on multiple-service conversations in a unified framework. In this work, we first build a Multiple-domain Multiple-service medical dialogue (M^2-MedDialog)dataset, which contains 1,557 conversations between doctors and patients, covering 276 types of diseases, 2,468 medical entities, and 3 specialties of medical services. To the best of our knowledge, it is the only medical dialogue dataset that includes both multiple medical services and fine-grained medical labels. Then, we formulate a one-stop MDS as a sequence-to-sequence generation problem. We unify a MDS with causal language modeling and conditional causal language modeling, respectively. Specifically, we employ several pretrained models (i.e., BERT-WWM, BERT-MED, GPT2, and MT5) and their variants to get benchmarks on M^2-MedDialog dataset. We also propose pseudo labeling and natural perturbation methods to expand M2-MedDialog dataset and enhance the state-of-the-art pretrained models. We demonstrate the results achieved by the benchmarks so far through extensive experiments on M2-MedDialog. We release the dataset, the code, as well as the evaluation scripts to facilitate future research in this important research direction.
Few-Shot Electronic Health Record Coding through Graph Contrastive Learning
Jun 29, 2021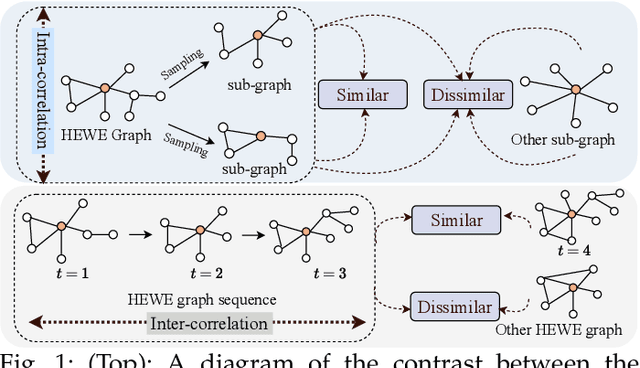
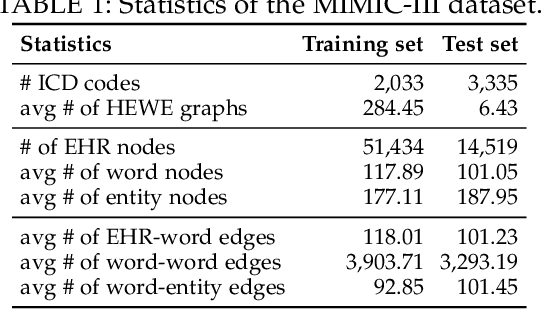
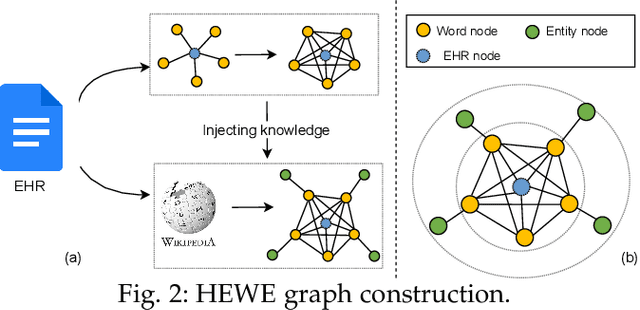

Electronic health record (EHR) coding is the task of assigning ICD codes to each EHR. Most previous studies either only focus on the frequent ICD codes or treat rare and frequent ICD codes in the same way. These methods perform well on frequent ICD codes but due to the extremely unbalanced distribution of ICD codes, the performance on rare ones is far from satisfactory. We seek to improve the performance for both frequent and rare ICD codes by using a contrastive graph-based EHR coding framework, CoGraph, which re-casts EHR coding as a few-shot learning task. First, we construct a heterogeneous EHR word-entity (HEWE) graph for each EHR, where the words and entities extracted from an EHR serve as nodes and the relations between them serve as edges. Then, CoGraph learns similarities and dissimilarities between HEWE graphs from different ICD codes so that information can be transferred among them. In a few-shot learning scenario, the model only has access to frequent ICD codes during training, which might force it to encode features that are useful for frequent ICD codes only. To mitigate this risk, CoGraph devises two graph contrastive learning schemes, GSCL and GECL, that exploit the HEWE graph structures so as to encode transferable features. GSCL utilizes the intra-correlation of different sub-graphs sampled from HEWE graphs while GECL exploits the inter-correlation among HEWE graphs at different clinical stages. Experiments on the MIMIC-III benchmark dataset show that CoGraph significantly outperforms state-of-the-art methods on EHR coding, not only on frequent ICD codes, but also on rare codes, in terms of several evaluation indicators. On frequent ICD codes, GSCL and GECL improve the classification accuracy and F1 by 1.31% and 0.61%, respectively, and on rare ICD codes CoGraph has more obvious improvements by 2.12% and 2.95%.
Improving Transformer-based Sequential Recommenders through Preference Editing
Jun 23, 2021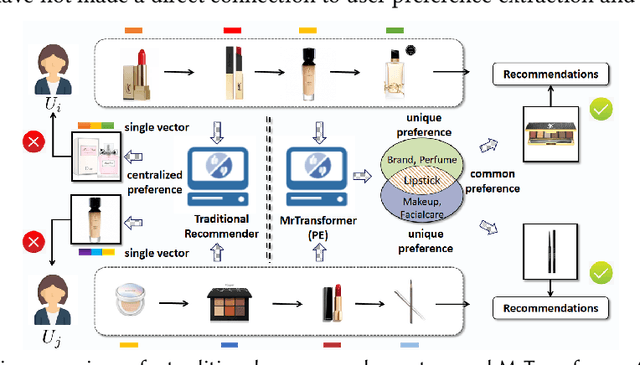
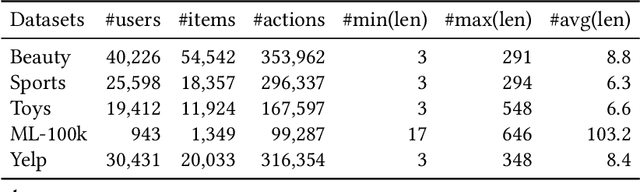
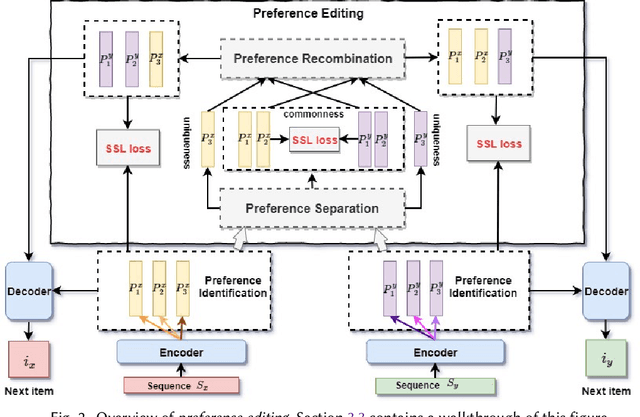
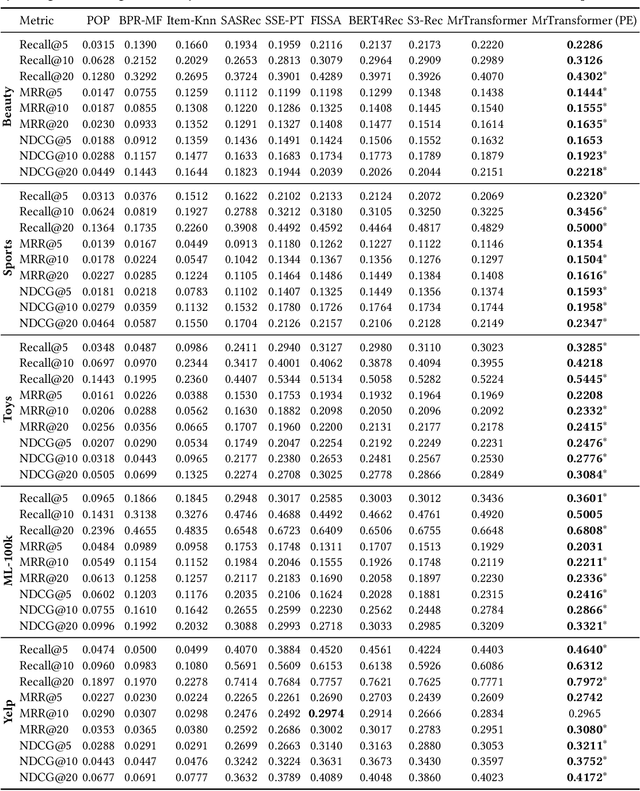
One of the key challenges in Sequential Recommendation (SR) is how to extract and represent user preferences. Traditional SR methods rely on the next item as the supervision signal to guide preference extraction and representation. We propose a novel learning strategy, named preference editing. The idea is to force the SR model to discriminate the common and unique preferences in different sequences of interactions between users and the recommender system. By doing so, the SR model is able to learn how to identify common and unique user preferences, and thereby do better user preference extraction and representation. We propose a transformer based SR model, named MrTransformer (Multi-preference Transformer), that concatenates some special tokens in front of the sequence to represent multiple user preferences and makes sure they capture different aspects through a preference coverage mechanism. Then, we devise a preference editing-based self-supervised learning mechanism for training MrTransformer which contains two main operations: preference separation and preference recombination. The former separates the common and unique user preferences for a given pair of sequences. The latter swaps the common preferences to obtain recombined user preferences for each sequence. Based on the preference separation and preference recombination operations, we define two types of SSL loss that require that the recombined preferences are similar to the original ones, and the common preferences are close to each other. We carry out extensive experiments on two benchmark datasets. MrTransformer with preference editing significantly outperforms state-of-the-art SR methods in terms of Recall, MRR and NDCG. We find that long sequences whose user preferences are harder to extract and represent benefit most from preference editing.