 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIL: Self-Amplified Iterative Learning for Diffusion Model Alignment with Minimal Human Feedback
Feb 05, 2026Aligning diffusion models with human preferences remains challenging, particularly when reward models are unavailable or impractical to obtain, and collecting large-scale preference datasets is prohibitively expensive. \textit{This raises a fundamental question: can we achieve effective alignment using only minimal human feedback, without auxiliary reward models, by unlocking the latent capabilities within diffusion models themselves?} In this paper, we propose \textbf{SAIL} (\textbf{S}elf-\textbf{A}mplified \textbf{I}terative \textbf{L}earning), a novel framework that enables diffusion models to act as their own teachers through iterative self-improvement. Starting from a minimal seed set of human-annotated preference pairs, SAIL operates in a closed-loop manner where the model progressively generates diverse samples, self-annotates preferences based on its evolving understanding, and refines itself using this self-augmented dataset. To ensure robust learning and prevent catastrophic forgetting, we introduce a ranked preference mixup strategy that carefully balances exploration with adherence to initial human priors. Extensive experiments demonstrate that SAIL consistently outperforms state-of-the-art methods across multiple benchmarks while using merely 6\% of the preference data required by existing approaches, revealing that diffusion models possess remarkable self-improvement capabilities that, when properly harnessed, can effectively replace both large-scale human annotation and external reward models.
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
Mar 13, 2025Large Language Models have demonstrated remarkable reasoning capability in complex textual tasks. However, multimodal reasoning, which requires integrating visual and textual information, remains a significant challenge. Existing visual-language models often struggle to effectively analyze and reason visual content, resulting in suboptimal performance on complex reasoning tasks. Moreover, the absence of comprehensive benchmarks hinders the accurate assessment of multimodal reasoning capabilities. In this paper, we introduce R1-Onevision, a multimodal reasoning model designed to bridge the gap between visual perception and deep reasoning. To achieve this, we propose a cross-modal reasoning pipeline that transforms images into formal textural representations, enabling precise language-based reasoning. Leveraging this pipeline, we construct the R1-Onevision dataset which provides detailed, step-by-step multimodal reasoning annotations across diverse domains. We further develop the R1-Onevision model through supervised fine-tuning and reinforcement learning to cultivate advanced reasoning and robust generalization abilities. To comprehensively evaluate multimodal reasoning performance across different grades, we introduce R1-Onevision-Bench, a benchmark aligned with human educational stages, covering exams from junior high school to university and beyond. Experimental results show that R1-Onevision achieves state-of-the-art performance, outperforming models such as GPT-4o and Qwen2.5-VL on multiple challenging multimodal reasoning benchmarks.
TeG-DG: Textually Guided Domain Generalization for Face Anti-Spoofing
Nov 30, 2023



Enhancing the domain generalization performance of Face Anti-Spoofing (FAS) techniques has emerged as a research focus. Existing methods are dedicated to extracting domain-invariant features from various training domains. Despite the promising performance, the extracted features inevitably contain residual style feature bias (e.g., illumination, capture device), resulting in inferior generalization performance. In this paper, we propose an alternative and effective solution, the Textually Guided Domain Generalization (TeG-DG) framework, which can effectively leverage text information for cross-domain alignment. Our core insight is that text, as a more abstract and universal form of expression, can capture the commonalities and essential characteristics across various attacks, bridging the gap between different image domains. Contrary to existing vision-language models, the proposed framework is elaborately designed to enhance the domain generalization ability of the FAS task. Concretely, we first design a Hierarchical Attention Fusion (HAF) module to enable adaptive aggregation of visual features at different levels; Then, a Textual-Enhanced Visual Discriminator (TEVD) is proposed for not only better alignment between the two modalities but also to regularize the classifier with unbiased text features. TeG-DG significantly outperforms previous approaches, especially in situations with extremely limited source domain data (~14% and ~12% improvements on HTER and AUC respectively), showcasing impressive few-shot performance.
Unified Medical Image Pre-training in Language-Guided Common Semantic Space
Nov 24, 2023



Vision-Language Pre-training (VLP) has shown the merits of analysing medical images, by leveraging the semantic congruence between medical images and their corresponding reports. It efficiently learns visual representations, which in turn facilitates enhanced analysis and interpretation of intricate imaging data. However, such observation is predominantly justified on single-modality data (mostly 2D images like X-rays), adapting VLP to learning unified representations for medical images in real scenario remains an open challenge. This arises from medical images often encompass a variety of modalities, especially modalities with different various number of dimensions (e.g., 3D images like Computed Tomography). To overcome the aforementioned challenges, we propose an Unified Medical Image Pre-training framework, namely UniMedI, which utilizes diagnostic reports as common semantic space to create unified representations for diverse modalities of medical images (especially for 2D and 3D images). Under the text's guidance, we effectively uncover visual modality information, identifying the affected areas in 2D X-rays and slices containing lesion in sophisticated 3D CT scans, ultimately enhancing the consistency across various medical imaging modalities. To demonstrate the effectiveness and versatility of UniMedI, we evaluate its performance on both 2D and 3D images across 10 different datasets, covering a wide range of medical image tasks such as classification, segmentation, and retrieval. UniMedI has demonstrated superior performance in downstream tasks, showcasing its effectiveness in establishing a universal medical visual representation.
Robustness-Guided Image Synthesis for Data-Free Quantization
Oct 05, 2023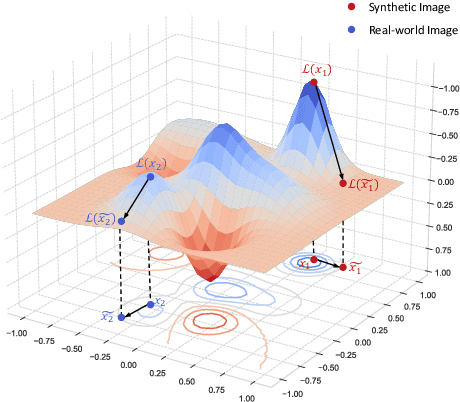
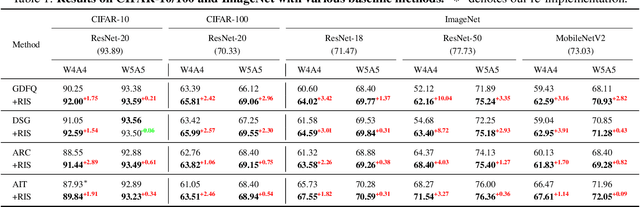
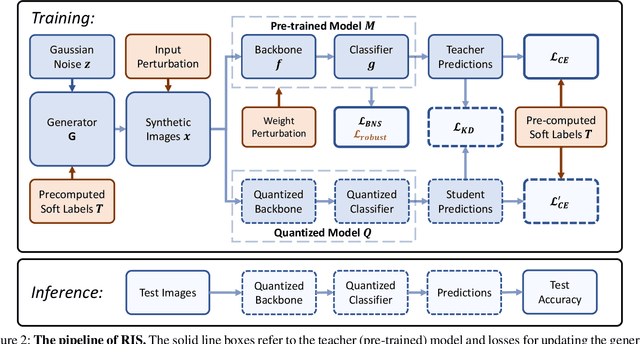
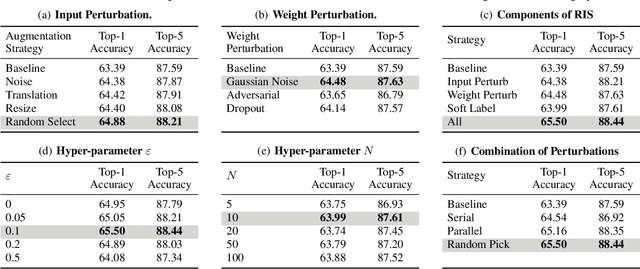
Quantization has emerged as a promising direction for model compression. Recently, data-free quantization has been widely studied as a promising method to avoid privacy concerns, which synthesizes images as an alternative to real training data. Existing methods use classification loss to ensure the reliability of the synthesized images. Unfortunately, even if these images are well-classified by the pre-trained model, they still suffer from low semantics and homogenization issues. Intuitively, these low-semantic images are sensitive to perturbations, and the pre-trained model tends to have inconsistent output when the generator synthesizes an image with poor semantics. To this end, we propose Robustness-Guided Image Synthesis (RIS), a simple but effective method to enrich the semantics of synthetic images and improve image diversity, further boosting the performance of downstream data-free compression tasks. Concretely, we first introduce perturbations on input and model weight, then define the inconsistency metrics at feature and prediction levels before and after perturbations. On the basis of inconsistency on two levels, we design a robustness optimization objective to enhance the semantics of synthetic images. Moreover, we also make our approach diversity-aware by forcing the generator to synthesize images with small correlations in the label space. With RIS, we achieve state-of-the-art performance for various settings on data-free quantization and can be extended to other data-free compression tasks.
Uniformly Distributed Category Prototype-Guided Vision-Language Framework for Long-Tail Recognition
Aug 24, 2023



Recently, large-scale pre-trained vision-language models have presented benefits for alleviating class imbalance in long-tailed recognition. However, the long-tailed data distribution can corrupt the representation space, where the distance between head and tail categories is much larger than the distance between two tail categories. This uneven feature space distribution causes the model to exhibit unclear and inseparable decision boundaries on the uniformly distributed test set, which lowers its performance. To address these challenges, we propose the uniformly category prototype-guided vision-language framework to effectively mitigate feature space bias caused by data imbalance. Especially, we generate a set of category prototypes uniformly distributed on a hypersphere. Category prototype-guided mechanism for image-text matching makes the features of different classes converge to these distinct and uniformly distributed category prototypes, which maintain a uniform distribution in the feature space, and improve class boundaries. Additionally, our proposed irrelevant text filtering and attribute enhancement module allows the model to ignore irrelevant noisy text and focus more on key attribute information, thereby enhancing the robustness of our framework. In the image recognition fine-tuning stage, to address the positive bias problem of the learnable classifier, we design the class feature prototype-guided classifier, which compensates for the performance of tail classes while maintaining the performance of head classes. Our method outperforms previous vision-language methods for long-tailed learning work by a large margin and achieves state-of-the-art performance.
Towards Calibrated Hyper-Sphere Representation via Distribution Overlap Coefficient for Long-tailed Learning
Aug 22, 2022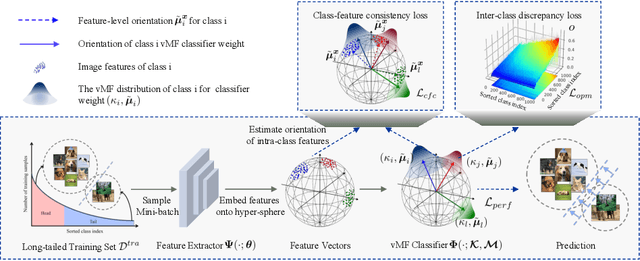
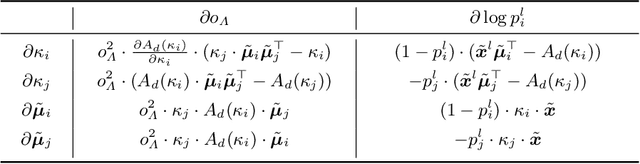
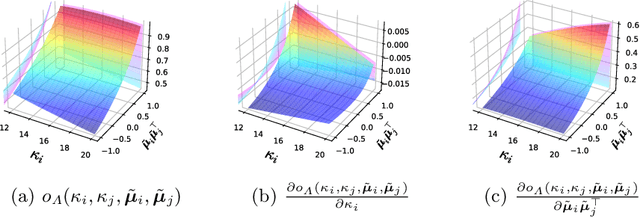
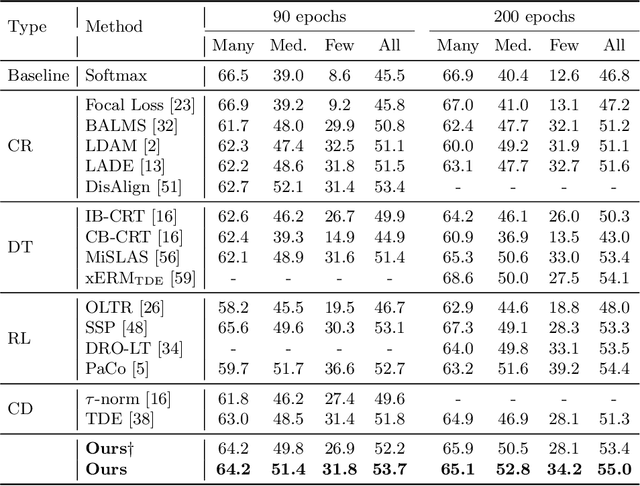
Long-tailed learning aims to tackle the crucial challenge that head classes dominate the training procedure under severe class imbalance in real-world scenarios. However, little attention has been given to how to quantify the dominance severity of head classes in the representation space. Motivated by this, we generalize the cosine-based classifiers to a von Mises-Fisher (vMF) mixture model, denoted as vMF classifier, which enables to quantitatively measure representation quality upon the hyper-sphere space via calculating distribution overlap coefficient. To our knowledge, this is the first work to measure representation quality of classifiers and features from the perspective of distribution overlap coefficient. On top of it, we formulate the inter-class discrepancy and class-feature consistency loss terms to alleviate the interference among the classifier weights and align features with classifier weights. Furthermore, a novel post-training calibration algorithm is devised to zero-costly boost the performance via inter-class overlap coefficients. Our method outperforms previous work with a large margin and achieves state-of-the-art performance on long-tailed image classification, semantic segmentation, and instance segmentation tasks (e.g., we achieve 55.0\% overall accuracy with ResNetXt-50 in ImageNet-LT). Our code is available at https://github.com/VipaiLab/vMF\_OP.