 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQNCD: Quantization Noise Correction for Diffusion Models
Mar 28, 2024



Diffusion models have revolutionized image synthesis, setting new benchmarks in quality and creativity. However, their widespread adoption is hindered by the intensive computation required during the iterative denoising process. Post-training quantization (PTQ) presents a solution to accelerate sampling, aibeit at the expense of sample quality, extremely in low-bit settings. Addressing this, our study introduces a unified Quantization Noise Correction Scheme (QNCD), aimed at minishing quantization noise throughout the sampling process. We identify two primary quantization challenges: intra and inter quantization noise. Intra quantization noise, mainly exacerbated by embeddings in the resblock module, extends activation quantization ranges, increasing disturbances in each single denosing step. Besides, inter quantization noise stems from cumulative quantization deviations across the entire denoising process, altering data distributions step-by-step. QNCD combats these through embedding-derived feature smoothing for eliminating intra quantization noise and an effective runtime noise estimatiation module for dynamicly filtering inter quantization noise. Extensive experiments demonstrate that our method outperforms previous quantization methods for diffusion models, achieving lossless results in W4A8 and W8A8 quantization settings on ImageNet (LDM-4). Code is available at: https://github.com/huanpengchu/QNCD
Robustness-Guided Image Synthesis for Data-Free Quantization
Oct 05, 2023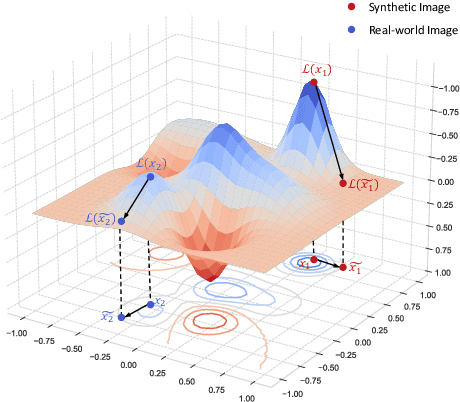
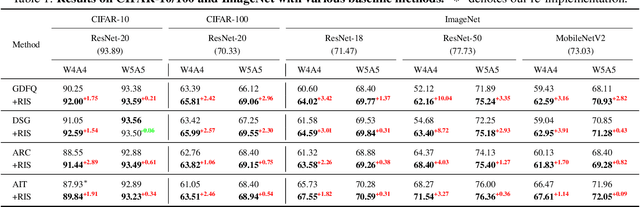
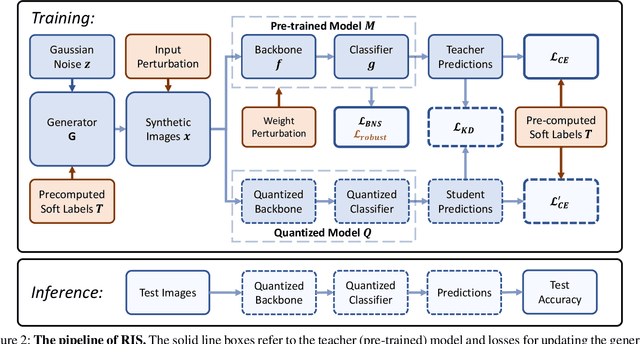
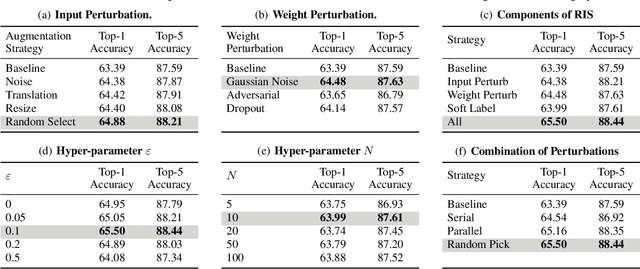
Quantization has emerged as a promising direction for model compression. Recently, data-free quantization has been widely studied as a promising method to avoid privacy concerns, which synthesizes images as an alternative to real training data. Existing methods use classification loss to ensure the reliability of the synthesized images. Unfortunately, even if these images are well-classified by the pre-trained model, they still suffer from low semantics and homogenization issues. Intuitively, these low-semantic images are sensitive to perturbations, and the pre-trained model tends to have inconsistent output when the generator synthesizes an image with poor semantics. To this end, we propose Robustness-Guided Image Synthesis (RIS), a simple but effective method to enrich the semantics of synthetic images and improve image diversity, further boosting the performance of downstream data-free compression tasks. Concretely, we first introduce perturbations on input and model weight, then define the inconsistency metrics at feature and prediction levels before and after perturbations. On the basis of inconsistency on two levels, we design a robustness optimization objective to enhance the semantics of synthetic images. Moreover, we also make our approach diversity-aware by forcing the generator to synthesize images with small correlations in the label space. With RIS, we achieve state-of-the-art performance for various settings on data-free quantization and can be extended to other data-free compression tasks.
On the Effectiveness of Out-of-Distribution Data in Self-Supervised Long-Tail Learning
Jun 08, 2023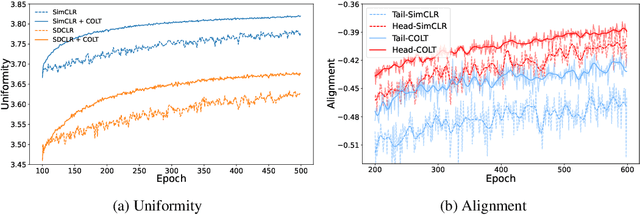
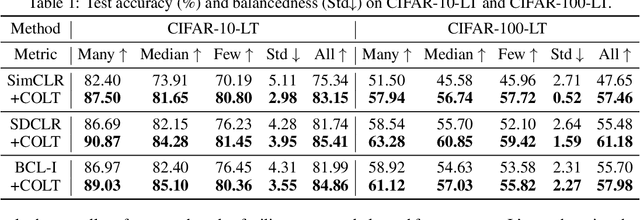
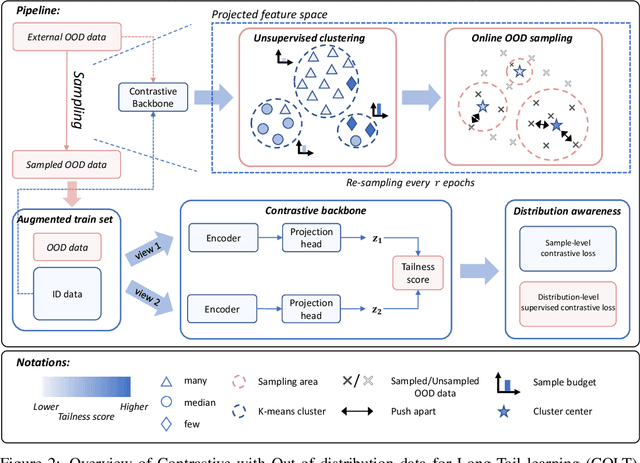
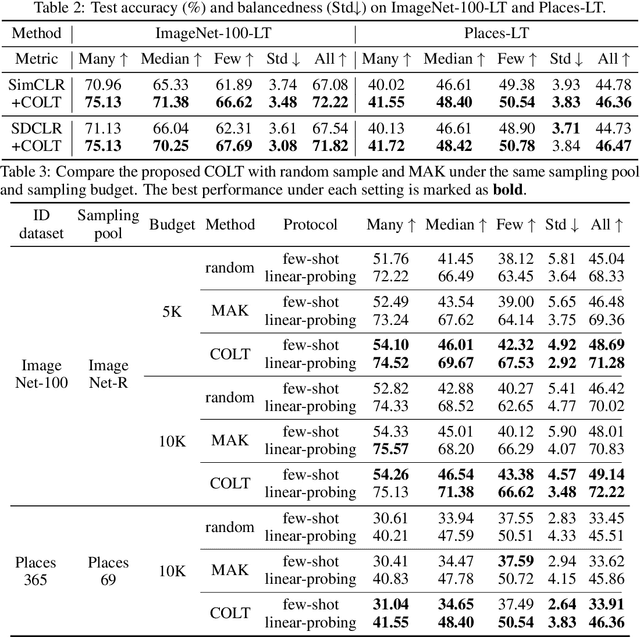
Though Self-supervised learning (SSL) has been widely studied as a promising technique for representation learning, it doesn't generalize well on long-tailed datasets due to the majority classes dominating the feature space. Recent work shows that the long-tailed learning performance could be boosted by sampling extra in-domain (ID) data for self-supervised training, however, large-scale ID data which can rebalance the minority classes are expensive to collect. In this paper, we propose an alternative but easy-to-use and effective solution, Contrastive with Out-of-distribution (OOD) data for Long-Tail learning (COLT), which can effectively exploit OOD data to dynamically re-balance the feature space. We empirically identify the counter-intuitive usefulness of OOD samples in SSL long-tailed learning and principally design a novel SSL method. Concretely, we first localize the `head' and `tail' samples by assigning a tailness score to each OOD sample based on its neighborhoods in the feature space. Then, we propose an online OOD sampling strategy to dynamically re-balance the feature space. Finally, we enforce the model to be capable of distinguishing ID and OOD samples by a distribution-level supervised contrastive loss. Extensive experiments are conducted on various datasets and several state-of-the-art SSL frameworks to verify the effectiveness of the proposed method. The results show that our method significantly improves the performance of SSL on long-tailed datasets by a large margin, and even outperforms previous work which uses external ID data. Our code is available at https://github.com/JianhongBai/COLT.