 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMePT: Multi-Representation Guided Prompt Tuning for Vision-Language Model
Paper and Code
Aug 19, 2024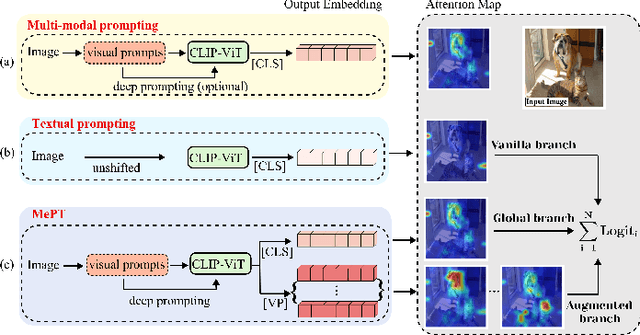
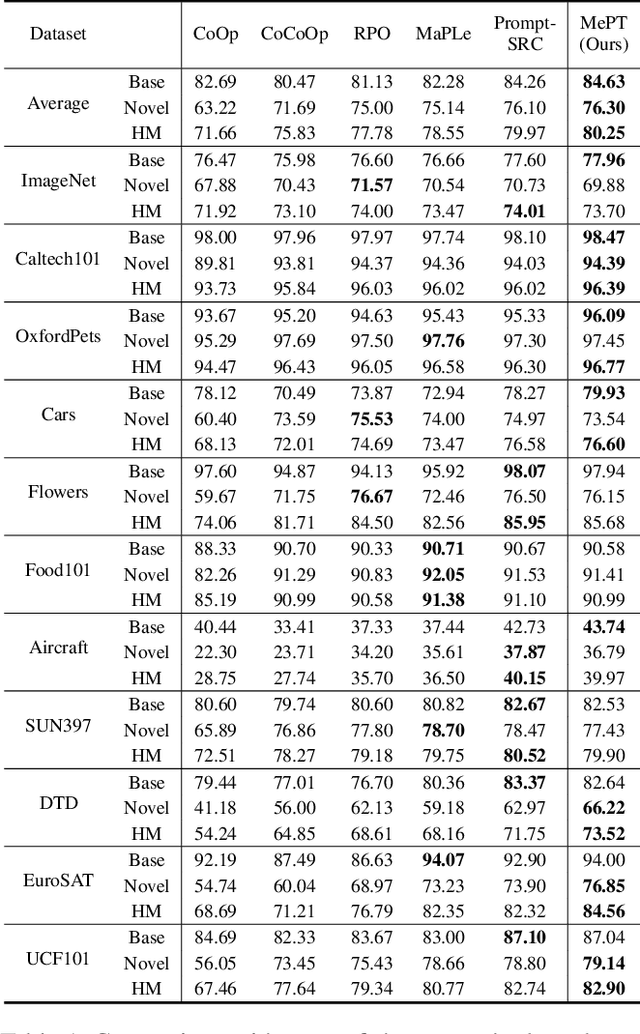
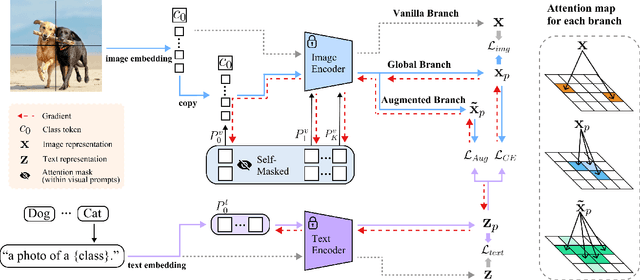
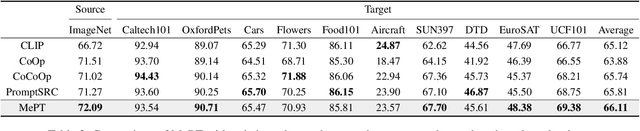
Recent advancements in pre-trained Vision-Language Models (VLMs) have highlighted the significant potential of prompt tuning for adapting these models to a wide range of downstream tasks. However, existing prompt tuning methods typically map an image to a single representation, limiting the model's ability to capture the diverse ways an image can be described. To address this limitation, we investigate the impact of visual prompts on the model's generalization capability and introduce a novel method termed Multi-Representation Guided Prompt Tuning (MePT). Specifically, MePT employs a three-branch framework that focuses on diverse salient regions, uncovering the inherent knowledge within images which is crucial for robust generalization. Further, we employ efficient self-ensemble techniques to integrate these versatile image representations, allowing MePT to learn all conditional, marginal, and fine-grained distributions effectively. We validate the effectiveness of MePT through extensive experiments, demonstrating significant improvements on both base-to-novel class prediction and domain generalization tasks.