 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Controllable Time Series Generation
Mar 06, 2024Time Series Generation (TSG) has emerged as a pivotal technique in synthesizing data that accurately mirrors real-world time series, becoming indispensable in numerous applications. Despite significant advancements in TSG, its efficacy frequently hinges on having large training datasets. This dependency presents a substantial challenge in data-scarce scenarios, especially when dealing with rare or unique conditions. To confront these challenges, we explore a new problem of Controllable Time Series Generation (CTSG), aiming to produce synthetic time series that can adapt to various external conditions, thereby tackling the data scarcity issue. In this paper, we propose \textbf{C}ontrollable \textbf{T}ime \textbf{S}eries (\textsf{CTS}), an innovative VAE-agnostic framework tailored for CTSG. A key feature of \textsf{CTS} is that it decouples the mapping process from standard VAE training, enabling precise learning of a complex interplay between latent features and external conditions. Moreover, we develop a comprehensive evaluation scheme for CTSG. Extensive experiments across three real-world time series datasets showcase \textsf{CTS}'s exceptional capabilities in generating high-quality, controllable outputs. This underscores its adeptness in seamlessly integrating latent features with external conditions. Extending \textsf{CTS} to the image domain highlights its remarkable potential for explainability and further reinforces its versatility across different modalities.
TSGBench: Time Series Generation Benchmark
Sep 07, 2023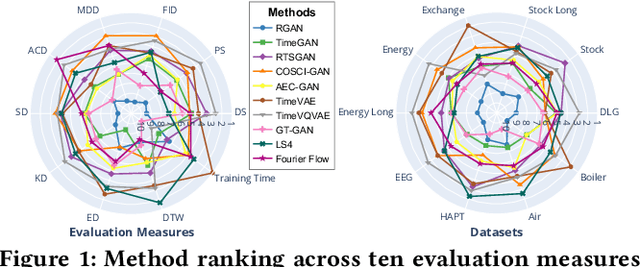


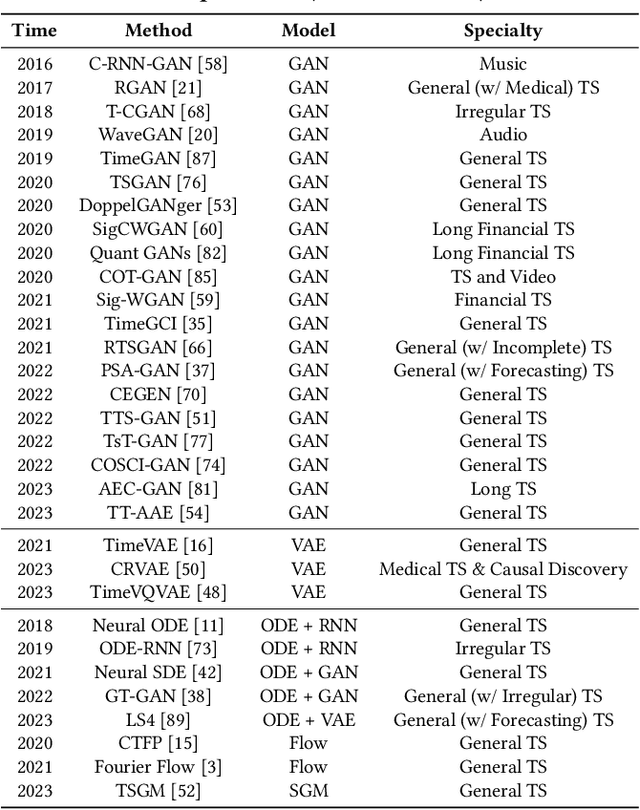
Synthetic Time Series Generation (TSG) is crucial in a range of applications, including data augmentation, anomaly detection, and privacy preservation. Although significant strides have been made in this field, existing methods exhibit three key limitations: (1) They often benchmark against similar model types, constraining a holistic view of performance capabilities. (2) The use of specialized synthetic and private datasets introduces biases and hampers generalizability. (3) Ambiguous evaluation measures, often tied to custom networks or downstream tasks, hinder consistent and fair comparison. To overcome these limitations, we introduce \textsf{TSGBench}, the inaugural TSG Benchmark, designed for a unified and comprehensive assessment of TSG methods. It comprises three modules: (1) a curated collection of publicly available, real-world datasets tailored for TSG, together with a standardized preprocessing pipeline; (2) a comprehensive evaluation measures suite including vanilla measures, new distance-based assessments, and visualization tools; (3) a pioneering generalization test rooted in Domain Adaptation (DA), compatible with all methods. We have conducted extensive experiments across ten real-world datasets from diverse domains, utilizing ten advanced TSG methods and twelve evaluation measures, all gauged through \textsf{TSGBench}. The results highlight its remarkable efficacy and consistency. More importantly, \textsf{TSGBench} delivers a statistical breakdown of method rankings, illuminating performance variations across different datasets and measures, and offering nuanced insights into the effectiveness of each method.
Mosaicking to Distill: Knowledge Distillation from Out-of-Domain Data
Oct 27, 2021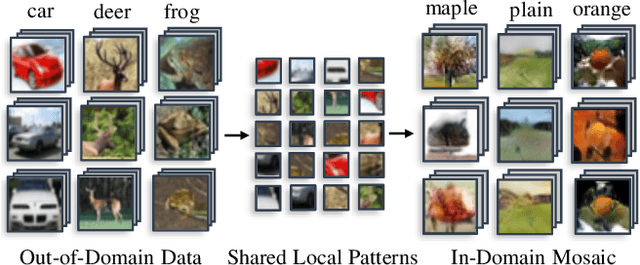
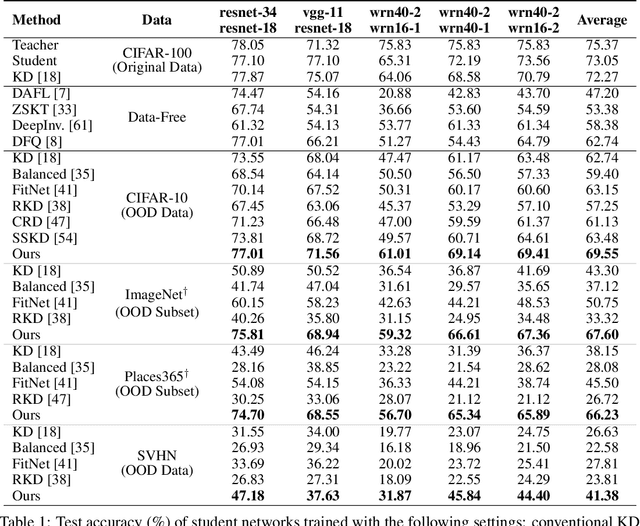
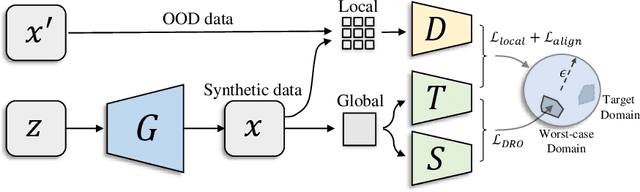
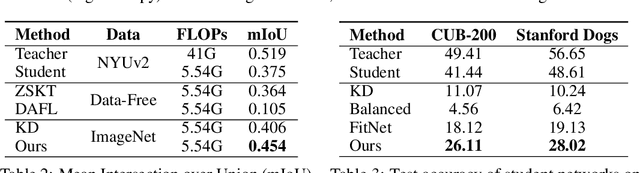
Knowledge distillation~(KD) aims to craft a compact student model that imitates the behavior of a pre-trained teacher in a target domain. Prior KD approaches, despite their gratifying results, have largely relied on the premise that \emph{in-domain} data is available to carry out the knowledge transfer. Such an assumption, unfortunately, in many cases violates the practical setting, since the original training data or even the data domain is often unreachable due to privacy or copyright reasons. In this paper, we attempt to tackle an ambitious task, termed as \emph{out-of-domain} knowledge distillation~(OOD-KD), which allows us to conduct KD using only OOD data that can be readily obtained at a very low cost. Admittedly, OOD-KD is by nature a highly challenging task due to the agnostic domain gap. To this end, we introduce a handy yet surprisingly efficacious approach, dubbed as~\textit{MosaicKD}. The key insight behind MosaicKD lies in that, samples from various domains share common local patterns, even though their global semantic may vary significantly; these shared local patterns, in turn, can be re-assembled analogous to mosaic tiling, to approximate the in-domain data and to further alleviating the domain discrepancy. In MosaicKD, this is achieved through a four-player min-max game, in which a generator, a discriminator, a student network, are collectively trained in an adversarial manner, partially under the guidance of a pre-trained teacher. We validate MosaicKD over {classification and semantic segmentation tasks} across various benchmarks, and demonstrate that it yields results much superior to the state-of-the-art counterparts on OOD data. Our code is available at \url{https://github.com/zju-vipa/MosaicKD}.
Privacy Threats Analysis to Secure Federated Learning
Jun 24, 2021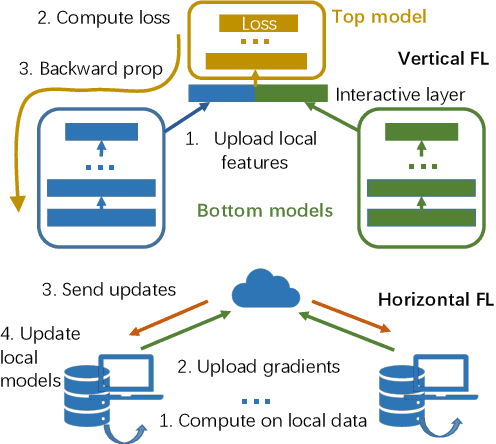
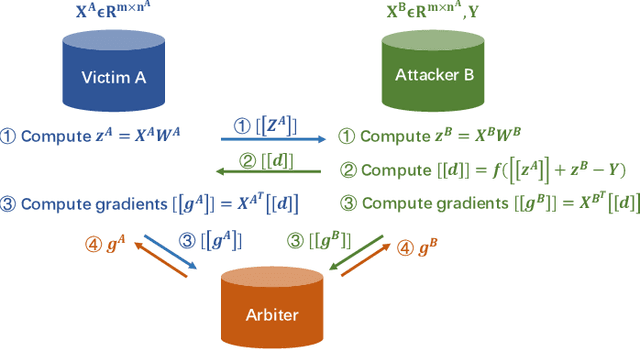
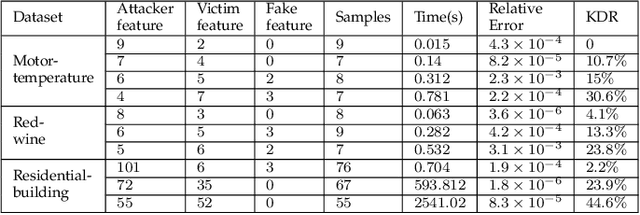
Federated learning is emerging as a machine learning technique that trains a model across multiple decentralized parties. It is renowned for preserving privacy as the data never leaves the computational devices, and recent approaches further enhance its privacy by hiding messages transferred in encryption. However, we found that despite the efforts, federated learning remains privacy-threatening, due to its interactive nature across different parties. In this paper, we analyze the privacy threats in industrial-level federated learning frameworks with secure computation, and reveal such threats widely exist in typical machine learning models such as linear regression, logistic regression and decision tree. For the linear and logistic regression, we show through theoretical analysis that it is possible for the attacker to invert the entire private input of the victim, given very few information. For the decision tree model, we launch an attack to infer the range of victim's private inputs. All attacks are evaluated on popular federated learning frameworks and real-world datasets.
A novel improved fuzzy support vector machine based stock price trend forecast model
Jan 02, 2018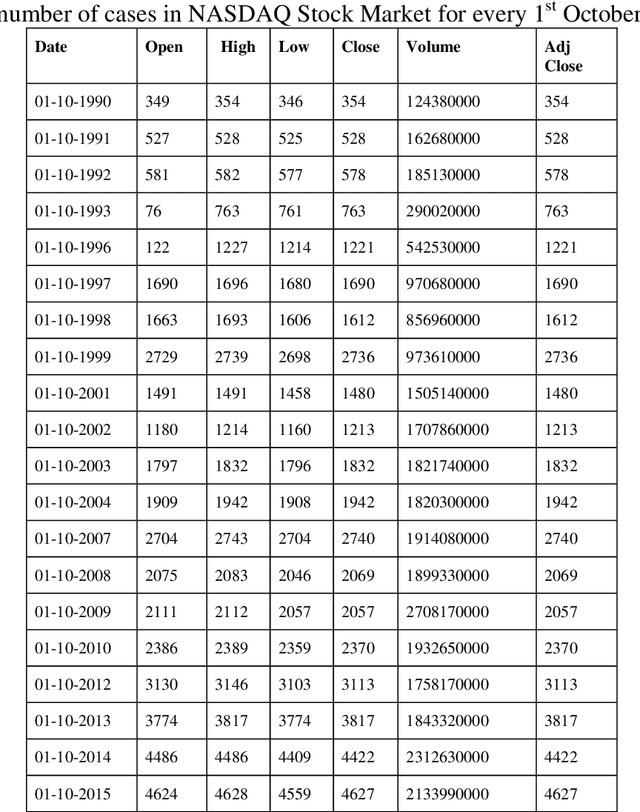
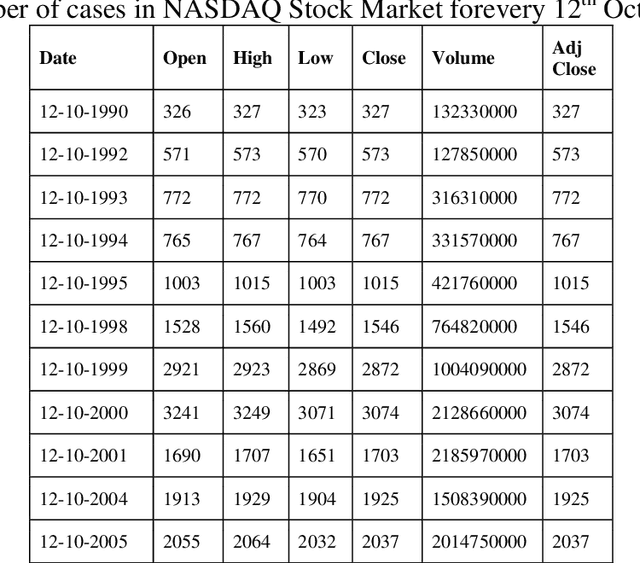
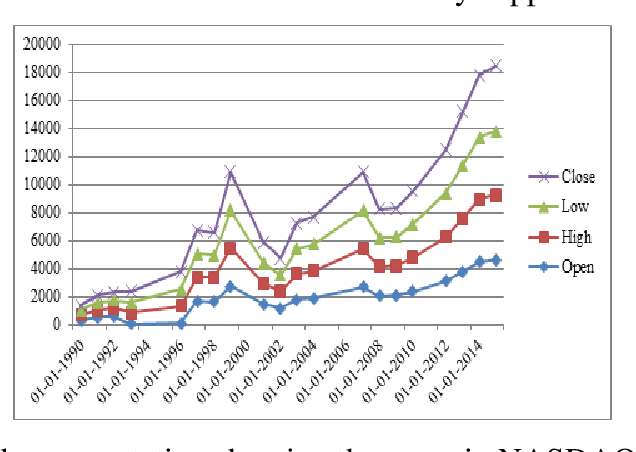
Application of fuzzy support vector machine in stock price forecast. Support vector machine is a new type of machine learning method proposed in 1990s. It can deal with classification and regression problems very successfully. Due to the excellent learning performance of support vector machine, the technology has become a hot research topic in the field of machine learning, and it has been successfully applied in many fields. However, as a new technology, there are many limitations to support vector machines. There is a large amount of fuzzy information in the objective world. If the training of support vector machine contains noise and fuzzy information, the performance of the support vector machine will become very weak and powerless. As the complexity of many factors influence the stock price prediction, the prediction results of traditional support vector machine cannot meet people with precision, this study improved the traditional support vector machine fuzzy prediction algorithm is proposed to improve the new model precision. NASDAQ Stock Market, Standard & Poor's (S&P) Stock market are considered. Novel advanced- fuzzy support vector machine (NA-FSVM) is the proposed methodology.