 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-CLIP: Unleashing the Power of Vision-Language Models for Video Quality Assessment through Unified Cross-Modal Adaptation
Aug 08, 2025Accurate and efficient Video Quality Assessment (VQA) has long been a key research challenge. Current mainstream VQA methods typically improve performance by pretraining on large-scale classification datasets (e.g., ImageNet, Kinetics-400), followed by fine-tuning on VQA datasets. However, this strategy presents two significant challenges: (1) merely transferring semantic knowledge learned from pretraining is insufficient for VQA, as video quality depends on multiple factors (e.g., semantics, distortion, motion, aesthetics); (2) pretraining on large-scale datasets demands enormous computational resources, often dozens or even hundreds of times greater than training directly on VQA datasets. Recently, Vision-Language Models (VLMs) have shown remarkable generalization capabilities across a wide range of visual tasks, and have begun to demonstrate promising potential in quality assessment. In this work, we propose Q-CLIP, the first fully VLMs-based framework for VQA. Q-CLIP enhances both visual and textual representations through a Shared Cross-Modal Adapter (SCMA), which contains only a minimal number of trainable parameters and is the only component that requires training. This design significantly reduces computational cost. In addition, we introduce a set of five learnable quality-level prompts to guide the VLMs in perceiving subtle quality variations, thereby further enhancing the model's sensitivity to video quality. Furthermore, we investigate the impact of different frame sampling strategies on VQA performance, and find that frame-difference-based sampling leads to better generalization performance across datasets. Extensive experiments demonstrate that Q-CLIP exhibits excellent performance on several VQA datasets.
UGD-IML: A Unified Generative Diffusion-based Framework for Constrained and Unconstrained Image Manipulation Localization
Aug 08, 2025In the digital age, advanced image editing tools pose a serious threat to the integrity of visual content, making image forgery detection and localization a key research focus. Most existing Image Manipulation Localization (IML) methods rely on discriminative learning and require large, high-quality annotated datasets. However, current datasets lack sufficient scale and diversity, limiting model performance in real-world scenarios. To overcome this, recent studies have explored Constrained IML (CIML), which generates pixel-level annotations through algorithmic supervision. However, existing CIML approaches often depend on complex multi-stage pipelines, making the annotation process inefficient. In this work, we propose a novel generative framework based on diffusion models, named UGD-IML, which for the first time unifies both IML and CIML tasks within a single framework. By learning the underlying data distribution, generative diffusion models inherently reduce the reliance on large-scale labeled datasets, allowing our approach to perform effectively even under limited data conditions. In addition, by leveraging a class embedding mechanism and a parameter-sharing design, our model seamlessly switches between IML and CIML modes without extra components or training overhead. Furthermore, the end-to-end design enables our model to avoid cumbersome steps in the data annotation process. Extensive experimental results on multiple datasets demonstrate that UGD-IML outperforms the SOTA methods by an average of 9.66 and 4.36 in terms of F1 metrics for IML and CIML tasks, respectively. Moreover, the proposed method also excels in uncertainty estimation, visualization and robustness.
DS-ProGen: A Dual-Structure Deep Language Model for Functional Protein Design
May 18, 2025Inverse Protein Folding (IPF) is a critical subtask in the field of protein design, aiming to engineer amino acid sequences capable of folding correctly into a specified three-dimensional (3D) conformation. Although substantial progress has been achieved in recent years, existing methods generally rely on either backbone coordinates or molecular surface features alone, which restricts their ability to fully capture the complex chemical and geometric constraints necessary for precise sequence prediction. To address this limitation, we present DS-ProGen, a dual-structure deep language model for functional protein design, which integrates both backbone geometry and surface-level representations. By incorporating backbone coordinates as well as surface chemical and geometric descriptors into a next-amino-acid prediction paradigm, DS-ProGen is able to generate functionally relevant and structurally stable sequences while satisfying both global and local conformational constraints. On the PRIDE dataset, DS-ProGen attains the current state-of-the-art recovery rate of 61.47%, demonstrating the synergistic advantage of multi-modal structural encoding in protein design. Furthermore, DS-ProGen excels in predicting interactions with a variety of biological partners, including ligands, ions, and RNA, confirming its robust functional retention capabilities.
UPMAD-Net: A Brain Tumor Segmentation Network with Uncertainty Guidance and Adaptive Multimodal Feature Fusion
May 06, 2025Background: Brain tumor segmentation has a significant impact on the diagnosis and treatment of brain tumors. Accurate brain tumor segmentation remains challenging due to their irregular shapes, vague boundaries, and high variability. Objective: We propose a brain tumor segmentation method that combines deep learning with prior knowledge derived from a region-growing algorithm. Methods: The proposed method utilizes a multi-scale feature fusion (MSFF) module and adaptive attention mechanisms (AAM) to extract multi-scale features and capture global contextual information. To enhance the model's robustness in low-confidence regions, the Monte Carlo Dropout (MC Dropout) strategy is employed for uncertainty estimation. Results: Extensive experiments demonstrate that the proposed method achieves superior performance on Brain Tumor Segmentation (BraTS) datasets, significantly outperforming various state-of-the-art methods. On the BraTS2021 dataset, the test Dice scores are 89.18% for Enhancing Tumor (ET) segmentation, 93.67% for Whole Tumor (WT) segmentation, and 91.23% for Tumor Core (TC) segmentation. On the BraTS2019 validation set, the validation Dice scores are 87.43%, 90.92%, and 90.40% for ET, WT, and TC segmentation, respectively. Ablation studies further confirmed the contribution of each module to segmentation accuracy, indicating that each component played a vital role in overall performance improvement. Conclusion: This study proposed a novel 3D brain tumor segmentation network based on the U-Net architecture. By incorporating the prior knowledge and employing the uncertainty estimation method, the robustness and performance were improved. The code for the proposed method is available at https://github.com/chenzhao2023/UPMAD_Net_BrainSeg.
Myocardial Region-guided Feature Aggregation Net for Automatic Coronary artery Segmentation and Stenosis Assessment using Coronary Computed Tomography Angiography
Apr 27, 2025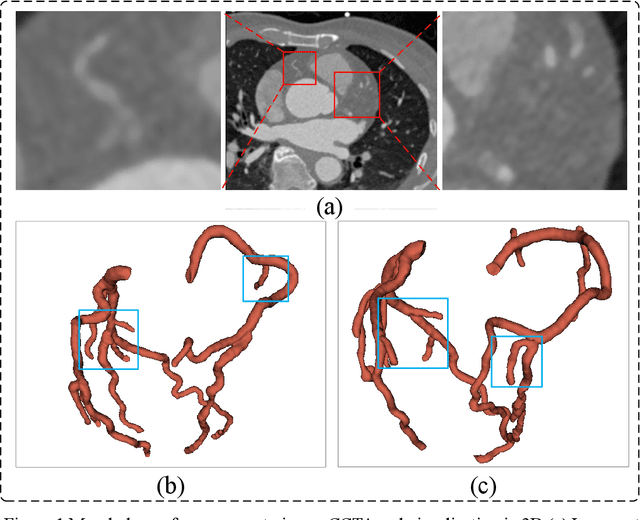
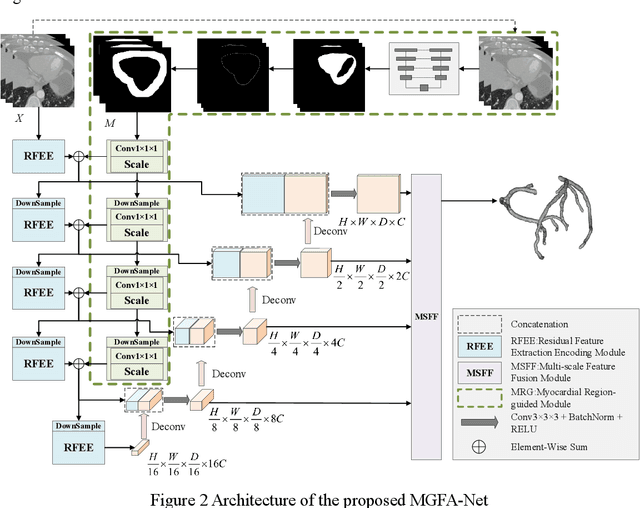
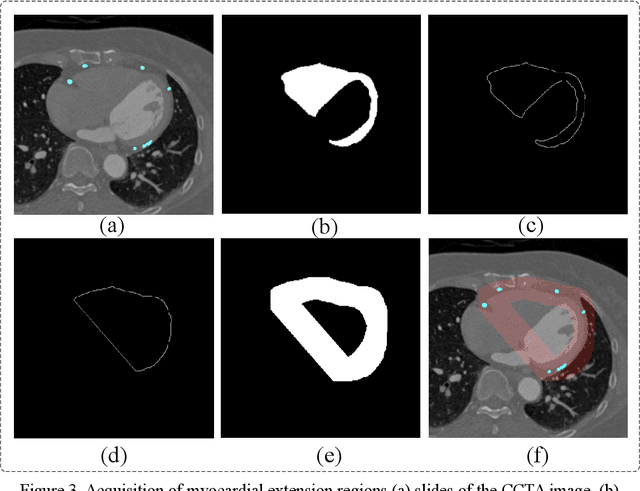
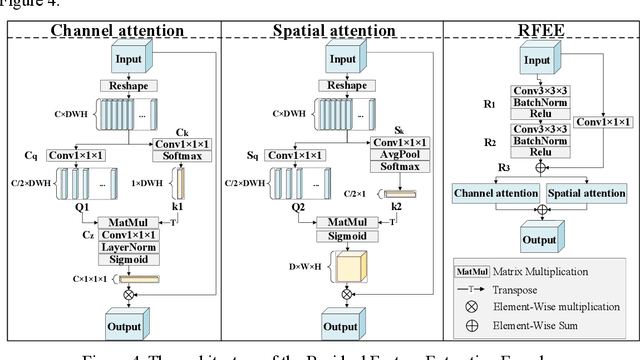
Coronary artery disease (CAD) remains a leading cause of mortality worldwide, requiring accurate segmentation and stenosis detection using Coronary Computed Tomography angiography (CCTA). Existing methods struggle with challenges such as low contrast, morphological variability and small vessel segmentation. To address these limitations, we propose the Myocardial Region-guided Feature Aggregation Net, a novel U-shaped dual-encoder architecture that integrates anatomical prior knowledge to enhance robustness in coronary artery segmentation. Our framework incorporates three key innovations: (1) a Myocardial Region-guided Module that directs attention to coronary regions via myocardial contour expansion and multi-scale feature fusion, (2) a Residual Feature Extraction Encoding Module that combines parallel spatial channel attention with residual blocks to enhance local-global feature discrimination, and (3) a Multi-scale Feature Fusion Module for adaptive aggregation of hierarchical vascular features. Additionally, Monte Carlo dropout f quantifies prediction uncertainty, supporting clinical interpretability. For stenosis detection, a morphology-based centerline extraction algorithm separates the vascular tree into anatomical branches, enabling cross-sectional area quantification and stenosis grading. The superiority of MGFA-Net was demonstrated by achieving an Dice score of 85.04%, an accuracy of 84.24%, an HD95 of 6.1294 mm, and an improvement of 5.46% in true positive rate for stenosis detection compared to3D U-Net. The integrated segmentation-to-stenosis pipeline provides automated, clinically interpretable CAD assessment, bridging deep learning with anatomical prior knowledge for precision medicine. Our code is publicly available at http://github.com/chenzhao2023/MGFA_CCTA
UniGenX: Unified Generation of Sequence and Structure with Autoregressive Diffusion
Mar 09, 2025Unified generation of sequence and structure for scientific data (e.g., materials, molecules, proteins) is a critical task. Existing approaches primarily rely on either autoregressive sequence models or diffusion models, each offering distinct advantages and facing notable limitations. Autoregressive models, such as GPT, Llama, and Phi-4, have demonstrated remarkable success in natural language generation and have been extended to multimodal tasks (e.g., image, video, and audio) using advanced encoders like VQ-VAE to represent complex modalities as discrete sequences. However, their direct application to scientific domains is challenging due to the high precision requirements and the diverse nature of scientific data. On the other hand, diffusion models excel at generating high-dimensional scientific data, such as protein, molecule, and material structures, with remarkable accuracy. Yet, their inability to effectively model sequences limits their potential as general-purpose multimodal foundation models. To address these challenges, we propose UniGenX, a unified framework that combines autoregressive next-token prediction with conditional diffusion models. This integration leverages the strengths of autoregressive models to ease the training of conditional diffusion models, while diffusion-based generative heads enhance the precision of autoregressive predictions. We validate the effectiveness of UniGenX on material and small molecule generation tasks, achieving a significant leap in state-of-the-art performance for material crystal structure prediction and establishing new state-of-the-art results for small molecule structure prediction, de novo design, and conditional generation. Notably, UniGenX demonstrates significant improvements, especially in handling long sequences for complex structures, showcasing its efficacy as a versatile tool for scientific data generation.
NatureLM: Deciphering the Language of Nature for Scientific Discovery
Feb 11, 2025



Foundation models have revolutionized natural language processing and artificial intelligence, significantly enhancing how machines comprehend and generate human languages. Inspired by the success of these foundation models, researchers have developed foundation models for individual scientific domains, including small molecules, materials, proteins, DNA, and RNA. However, these models are typically trained in isolation, lacking the ability to integrate across different scientific domains. Recognizing that entities within these domains can all be represented as sequences, which together form the "language of nature", we introduce Nature Language Model (briefly, NatureLM), a sequence-based science foundation model designed for scientific discovery. Pre-trained with data from multiple scientific domains, NatureLM offers a unified, versatile model that enables various applications including: (i) generating and optimizing small molecules, proteins, RNA, and materials using text instructions; (ii) cross-domain generation/design, such as protein-to-molecule and protein-to-RNA generation; and (iii) achieving state-of-the-art performance in tasks like SMILES-to-IUPAC translation and retrosynthesis on USPTO-50k. NatureLM offers a promising generalist approach for various scientific tasks, including drug discovery (hit generation/optimization, ADMET optimization, synthesis), novel material design, and the development of therapeutic proteins or nucleotides. We have developed NatureLM models in different sizes (1 billion, 8 billion, and 46.7 billion parameters) and observed a clear improvement in performance as the model size increases.
Vision Transformer-based Multimodal Feature Fusion Network for Lymphoma Segmentation on PET/CT Images
Feb 04, 2024Background: Diffuse large B-cell lymphoma (DLBCL) segmentation is a challenge in medical image analysis. Traditional segmentation methods for lymphoma struggle with the complex patterns and the presence of DLBCL lesions. Objective: We aim to develop an accurate method for lymphoma segmentation with 18F-Fluorodeoxyglucose positron emission tomography (PET) and computed tomography (CT) images. Methods: Our lymphoma segmentation approach combines a vision transformer with dual encoders, adeptly fusing PET and CT data via multimodal cross-attention fusion (MMCAF) module. In this study, PET and CT data from 165 DLBCL patients were analyzed. A 5-fold cross-validation was employed to evaluate the performance and generalization ability of our method. Ground truths were annotated by experienced nuclear medicine experts. We calculated the total metabolic tumor volume (TMTV) and performed a statistical analysis on our results. Results: The proposed method exhibited accurate performance in DLBCL lesion segmentation, achieving a Dice similarity coefficient of 0.9173$\pm$0.0071, a Hausdorff distance of 2.71$\pm$0.25mm, a sensitivity of 0.9462$\pm$0.0223, and a specificity of 0.9986$\pm$0.0008. Additionally, a Pearson correlation coefficient of 0.9030$\pm$0.0179 and an R-square of 0.8586$\pm$0.0173 were observed in TMTV when measured on manual annotation compared to our segmentation results. Conclusion: This study highlights the advantages of MMCAF and vision transformer for lymphoma segmentation using PET and CT, offering great promise for computer-aided lymphoma diagnosis and treatment.
A Robust Deep Learning Method with Uncertainty Estimation for the Pathological Classification of Renal Cell Carcinoma based on CT Images
Nov 12, 2023



Objectives To develop and validate a deep learning-based diagnostic model incorporating uncertainty estimation so as to facilitate radiologists in the preoperative differentiation of the pathological subtypes of renal cell carcinoma (RCC) based on CT images. Methods Data from 668 consecutive patients, pathologically proven RCC, were retrospectively collected from Center 1. By using five-fold cross-validation, a deep learning model incorporating uncertainty estimation was developed to classify RCC subtypes into clear cell RCC (ccRCC), papillary RCC (pRCC), and chromophobe RCC (chRCC). An external validation set of 78 patients from Center 2 further evaluated the model's performance. Results In the five-fold cross-validation, the model's area under the receiver operating characteristic curve (AUC) for the classification of ccRCC, pRCC, and chRCC was 0.868 (95% CI: 0.826-0.923), 0.846 (95% CI: 0.812-0.886), and 0.839 (95% CI: 0.802-0.88), respectively. In the external validation set, the AUCs were 0.856 (95% CI: 0.838-0.882), 0.787 (95% CI: 0.757-0.818), and 0.793 (95% CI: 0.758-0.831) for ccRCC, pRCC, and chRCC, respectively. Conclusions The developed deep learning model demonstrated robust performance in predicting the pathological subtypes of RCC, while the incorporated uncertainty emphasized the importance of understanding model confidence, which is crucial for assisting clinical decision-making for patients with renal tumors. Clinical relevance statement Our deep learning approach, integrated with uncertainty estimation, offers clinicians a dual advantage: accurate RCC subtype predictions complemented by diagnostic confidence references, promoting informed decision-making for patients with RCC.
MLA-BIN: Model-level Attention and Batch-instance Style Normalization for Domain Generalization of Federated Learning on Medical Image Segmentation
Jun 29, 2023



The privacy protection mechanism of federated learning (FL) offers an effective solution for cross-center medical collaboration and data sharing. In multi-site medical image segmentation, each medical site serves as a client of FL, and its data naturally forms a domain. FL supplies the possibility to improve the performance of seen domains model. However, there is a problem of domain generalization (DG) in the actual de-ployment, that is, the performance of the model trained by FL in unseen domains will decrease. Hence, MLA-BIN is proposed to solve the DG of FL in this study. Specifically, the model-level attention module (MLA) and batch-instance style normalization (BIN) block were designed. The MLA represents the unseen domain as a linear combination of seen domain models. The atten-tion mechanism is introduced for the weighting coefficient to obtain the optimal coefficient ac-cording to the similarity of inter-domain data features. MLA enables the global model to gen-eralize to unseen domain. In the BIN block, batch normalization (BN) and instance normalization (IN) are combined to perform the shallow layers of the segmentation network for style normali-zation, solving the influence of inter-domain image style differences on DG. The extensive experimental results of two medical image seg-mentation tasks demonstrate that the proposed MLA-BIN outperforms state-of-the-art methods.