 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Acceptability Judgements
May 24, 2023



Years have passed since the NLP community has last focused on linguistic acceptability. In this work, we revisit this topic in the context of large language models. We introduce CoLAC - Corpus of Linguistic Acceptability in Chinese, the first large-scale non-English acceptability dataset that is verified by native speakers and comes with two sets of labels. Our experiments show that even the largest InstructGPT model performs only at chance level on CoLAC, while ChatGPT's performance (48.30 MCC) is also way below supervised models (59.03 MCC) and human (65.11 MCC). Through cross-lingual transfer experiments and fine-grained linguistic analysis, we demonstrate for the first time that knowledge of linguistic acceptability can be transferred across typologically distinct languages, as well as be traced back to pre-training.
Investigating Transfer Learning in Multilingual Pre-trained Language Models through Chinese Natural Language Inference
Jun 07, 2021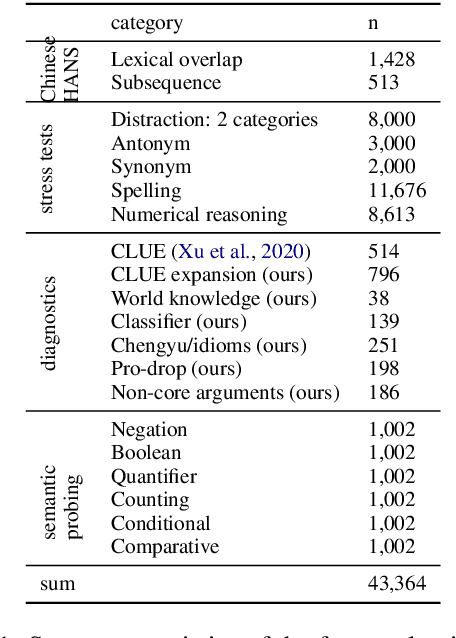


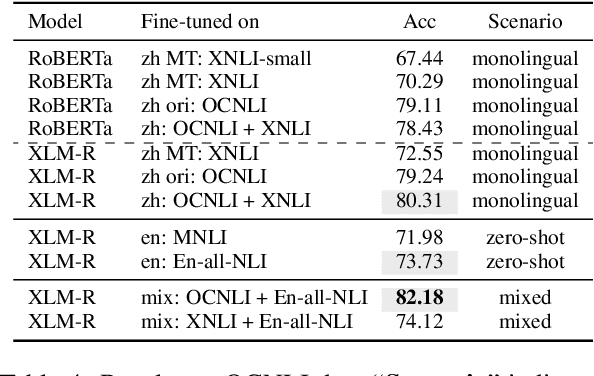
Multilingual transformers (XLM, mT5) have been shown to have remarkable transfer skills in zero-shot settings. Most transfer studies, however, rely on automatically translated resources (XNLI, XQuAD), making it hard to discern the particular linguistic knowledge that is being transferred, and the role of expert annotated monolingual datasets when developing task-specific models. We investigate the cross-lingual transfer abilities of XLM-R for Chinese and English natural language inference (NLI), with a focus on the recent large-scale Chinese dataset OCNLI. To better understand linguistic transfer, we created 4 categories of challenge and adversarial tasks (totaling 17 new datasets) for Chinese that build on several well-known resources for English (e.g., HANS, NLI stress-tests). We find that cross-lingual models trained on English NLI do transfer well across our Chinese tasks (e.g., in 3/4 of our challenge categories, they perform as well/better than the best monolingual models, even on 3/5 uniquely Chinese linguistic phenomena such as idioms, pro drop). These results, however, come with important caveats: cross-lingual models often perform best when trained on a mixture of English and high-quality monolingual NLI data (OCNLI), and are often hindered by automatically translated resources (XNLI-zh). For many phenomena, all models continue to struggle, highlighting the need for our new diagnostics to help benchmark Chinese and cross-lingual models. All new datasets/code are released at https://github.com/huhailinguist/ChineseNLIProbing.