 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Meta Distribution of SINR in UAV-Assisted Cellular Networks
Jan 30, 2023Mounting compact and lightweight base stations on unmanned aerial vehicles (UAVs) is a cost-effective and flexible solution to provide seamless coverage on the existing terrestrial networks. While the coverage probability in UAV-assisted cellular networks has been widely investigated, it provides only the first-order statistic of signal-to-interference-plus-noise ratio (SINR). In this paper, to analyze high-order statistics of SINR and characterize the disparity among individual links, we provide a meta distribution (MD)-based analytical framework for UAV-assisted cellular networks, in which the probabilistic line-of-sight channel and realistic antenna pattern are taken into account for air-to-ground transmissions. To accurately characterize the interference from UAVs, we relax the widely applied uniform off-boresight angle (OBA) assumption and derive the exact distribution of OBA. Using stochastic geometry, for both steerable and vertical antenna scenarios, we obtain mathematical expressions for the moments of condition success probability, the SINR MD, and the mean local delay. Moreover, we study the asymptotic behavior of the moments as network density approaches infinity. Numerical results validate the tightness of the theoretical results and show that the uniform OBA assumption underestimates the network performance, especially in the regime of moderate altitude of UAV. We also show that when UAVs are equipped with steerable antennas, the network coverage and user fairness can be optimized simultaneously by carefully adjusting the UAV parameters.
Heterogeneous Ultra-Dense Networks with Traffic Hotspots: A Unified Handover Analysis
Apr 07, 2022

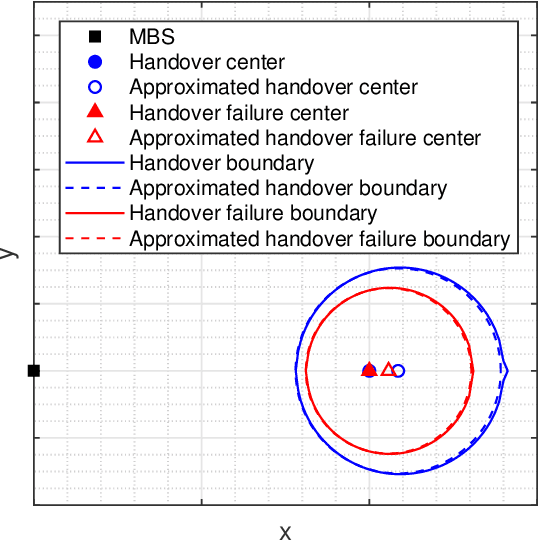
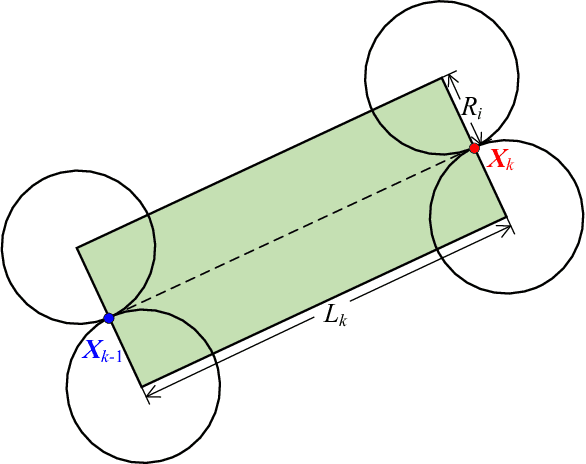
With the ever-growing communication demands and the unceasing miniaturization of mobile devices, the Internet of Things is expanding the amount of mobile terminals to an enormous level. To deal with such numbers of communication data, plenty of base stations (BSs) need to be deployed. However, denser deployments of heterogeneous networks (HetNets) lead to more frequent handovers, which could increase network burden and degrade the users experience, especially in traffic hotspot areas. In this paper, we develop a unified framework to investigate the handover performance of wireless networks with traffic hotspots. Using the stochastic geometry, we derive the theoretical expressions of average distances and handover metrics in HetNets, where the correlations between users and BSs in hotspots are captured. Specifically, the distributions of macro cells are modeled as independent Poisson point processes (PPPs), and the two tiers of small cells outside and inside the hotspots are modeled as PPP and Poisson cluster process (PCP) separately. A modified random waypoint (MRWP) model is also proposed to eliminate the density wave phenomenon in traditional models and to increase the accuracy of handover decision. By combining the PCP and MRWP model, the distributions of distances from a typical terminal to the BSs in different tiers are derived. Afterwards, we derive the expressions of average distances from a typical terminal to different BSs, and reveal that the handover rate, handover failure rate, and ping-pong rate are deduced as the functions of BS density, scattering variance of clustered small cell, user velocity, and threshold of triggered time. Simulation results verify the accuracy of the proposed analytical model and closed-form theoretical expressions.
Investigating Transfer Learning in Multilingual Pre-trained Language Models through Chinese Natural Language Inference
Jun 07, 2021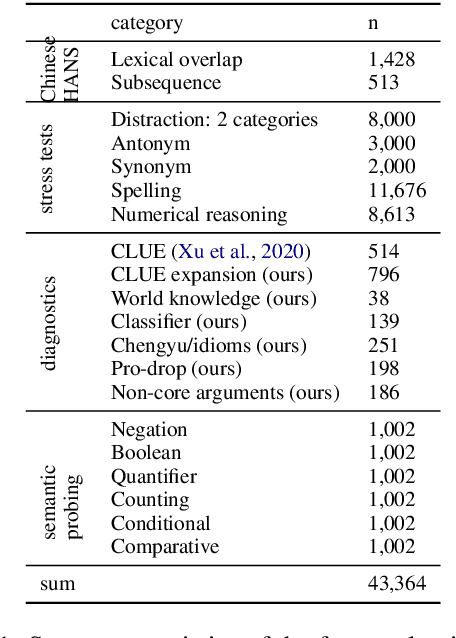


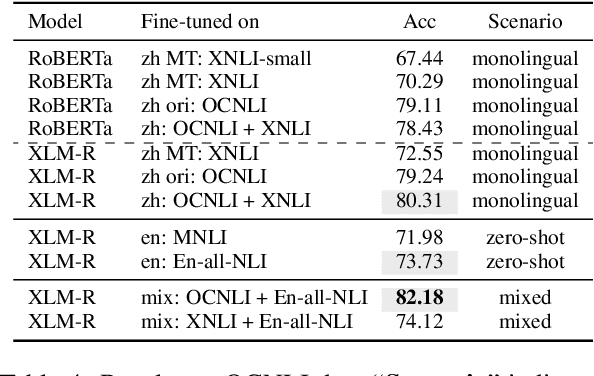
Multilingual transformers (XLM, mT5) have been shown to have remarkable transfer skills in zero-shot settings. Most transfer studies, however, rely on automatically translated resources (XNLI, XQuAD), making it hard to discern the particular linguistic knowledge that is being transferred, and the role of expert annotated monolingual datasets when developing task-specific models. We investigate the cross-lingual transfer abilities of XLM-R for Chinese and English natural language inference (NLI), with a focus on the recent large-scale Chinese dataset OCNLI. To better understand linguistic transfer, we created 4 categories of challenge and adversarial tasks (totaling 17 new datasets) for Chinese that build on several well-known resources for English (e.g., HANS, NLI stress-tests). We find that cross-lingual models trained on English NLI do transfer well across our Chinese tasks (e.g., in 3/4 of our challenge categories, they perform as well/better than the best monolingual models, even on 3/5 uniquely Chinese linguistic phenomena such as idioms, pro drop). These results, however, come with important caveats: cross-lingual models often perform best when trained on a mixture of English and high-quality monolingual NLI data (OCNLI), and are often hindered by automatically translated resources (XNLI-zh). For many phenomena, all models continue to struggle, highlighting the need for our new diagnostics to help benchmark Chinese and cross-lingual models. All new datasets/code are released at https://github.com/huhailinguist/ChineseNLIProbing.
CLUE: A Chinese Language Understanding Evaluation Benchmark
Apr 14, 2020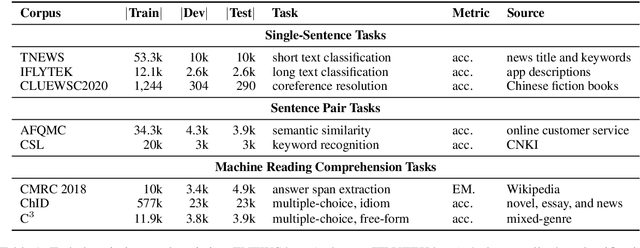
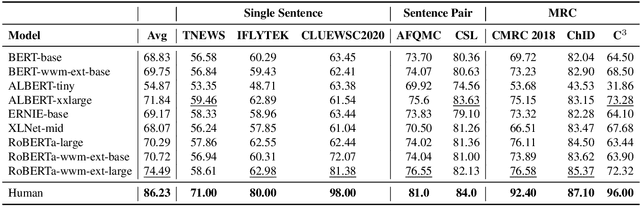
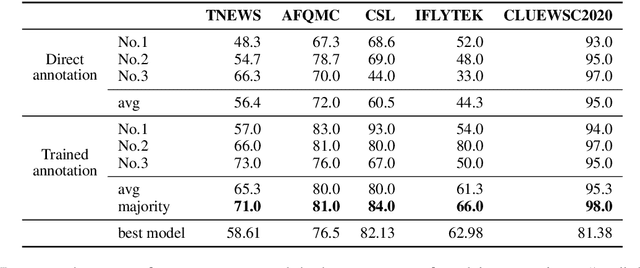
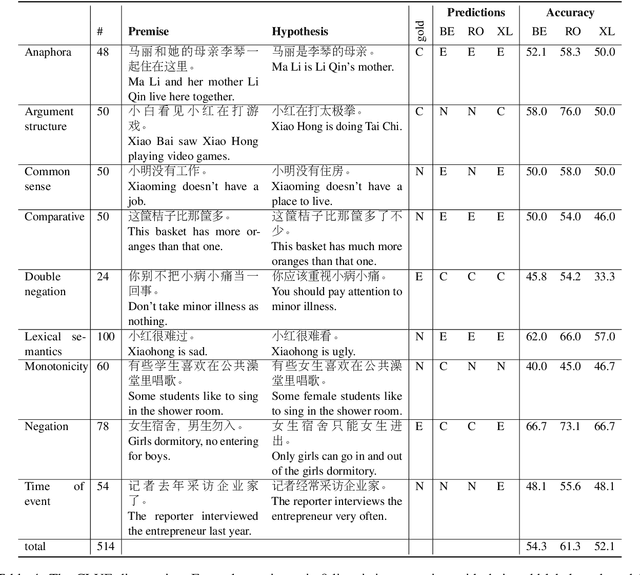
We introduce CLUE, a Chinese Language Understanding Evaluation benchmark. It contains eight different tasks, including single-sentence classification, sentence pair classification, and machine reading comprehension. We evaluate CLUE on a number of existing full-network pre-trained models for Chinese. We also include a small hand-crafted diagnostic test set designed to probe specific linguistic phenomena using different models, some of which are unique to Chinese. Along with CLUE, we release a large clean crawled raw text corpus that can be used for model pre-training. We release CLUE, baselines and pre-training dataset on Github.