 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMELA: Multilingual Evaluation of Linguistic Acceptability
Nov 15, 2023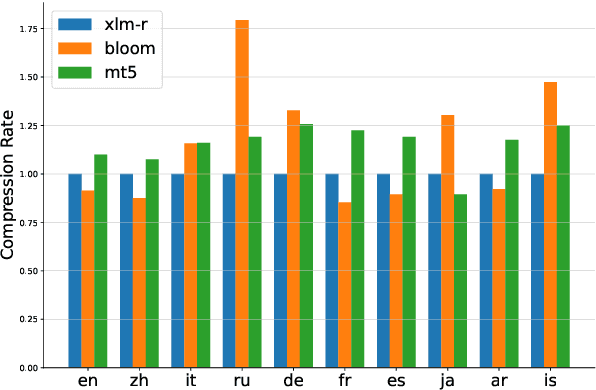
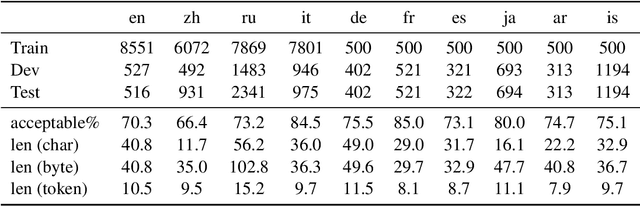
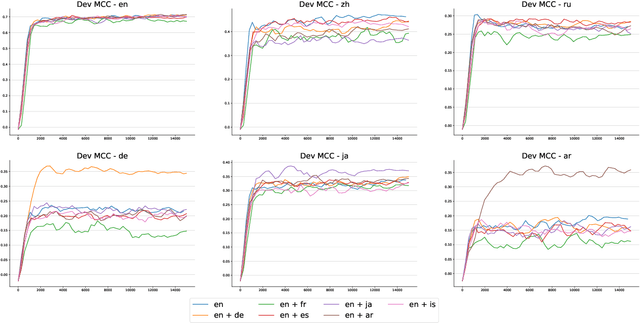
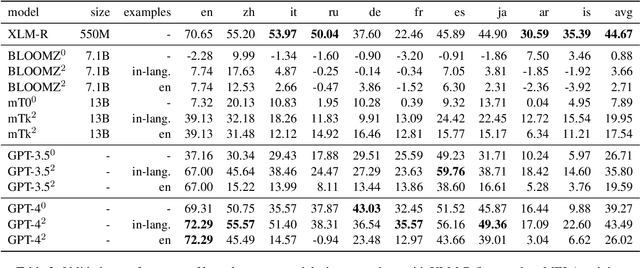
Recent benchmarks for Large Language Models (LLMs) have mostly focused on application-driven tasks such as complex reasoning and code generation, and this has led to a scarcity in purely linguistic evaluation of LLMs. Against this background, we introduce Multilingual Evaluation of Linguistic Acceptability -- MELA, the first multilingual benchmark on linguistic acceptability with 48K samples covering 10 languages from a diverse set of language families. We establish baselines of commonly used LLMs along with supervised models, and conduct cross-lingual transfer and multi-task learning experiments with XLM-R. In pursuit of multilingual interpretability, we analyze the weights of fine-tuned XLM-R to explore the possibility of identifying transfer difficulty between languages. Our results show that ChatGPT benefits much from in-context examples but still lags behind fine-tuned XLM-R, while the performance of GPT-4 is on par with fine-tuned XLM-R even in zero-shot setting. Cross-lingual and multi-task learning experiments show that unlike semantic tasks, in-language training data is crucial in acceptability judgements. Results in layerwise probing indicate that the upper layers of XLM-R become a task-specific but language-agnostic region for multilingual acceptability judgment. We also introduce the concept of conflicting weight, which could be a potential indicator for the difficulty of cross-lingual transfer between languages. Our data will be available at https://github.com/sjtu-compling/MELA.
Revisiting Acceptability Judgements
May 24, 2023



Years have passed since the NLP community has last focused on linguistic acceptability. In this work, we revisit this topic in the context of large language models. We introduce CoLAC - Corpus of Linguistic Acceptability in Chinese, the first large-scale non-English acceptability dataset that is verified by native speakers and comes with two sets of labels. Our experiments show that even the largest InstructGPT model performs only at chance level on CoLAC, while ChatGPT's performance (48.30 MCC) is also way below supervised models (59.03 MCC) and human (65.11 MCC). Through cross-lingual transfer experiments and fine-grained linguistic analysis, we demonstrate for the first time that knowledge of linguistic acceptability can be transferred across typologically distinct languages, as well as be traced back to pre-training.