 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOUT: Semantic scene COverage via Uncertainty-guided Traversal
Jun 04, 2026Robots that operate over extended periods should not merely visit space; they should progressively understand it. Yet most 3D scene graph pipelines treat perception as a post-processing stage over a fixed dataset, decoupling scene representation from the decisions that determine what is observed in the first place. We present SCOUT, an online semantic exploration framework that closes this loop by coupling active traversal with probabilistic scene graph construction. Given a prior 2D occupancy map and posed RGB-D observations, SCOUT incrementally builds an uncertainty-aware 3D scene graph whose nodes maintain fused geometry and posterior beliefs over open-vocabulary object labels, while edges encode structural relations such as on, inside, belong, and next to. These beliefs are fed back to an uncertainty-guided traversal planner, which selects viewpoints by balancing expected semantic certainty gain, geometric coverage gain, and travel cost. In this way, the robot revisits ambiguous objects when additional evidence matters and expands into unseen free space when the scene remains incomplete. The resulting system treats semantic scene completeness as an operational objective rather than a passive by-product of semantic mapping, moving toward autonomous agents that can patrol, update, and reason about evolving indoor environments with minimal human intervention.
MELA: Multilingual Evaluation of Linguistic Acceptability
Nov 15, 2023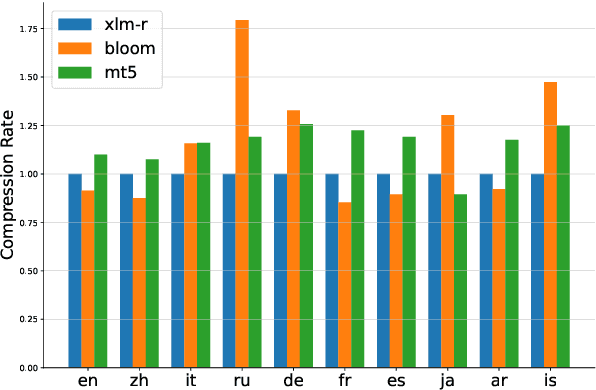
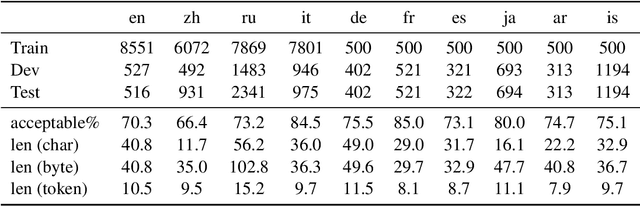
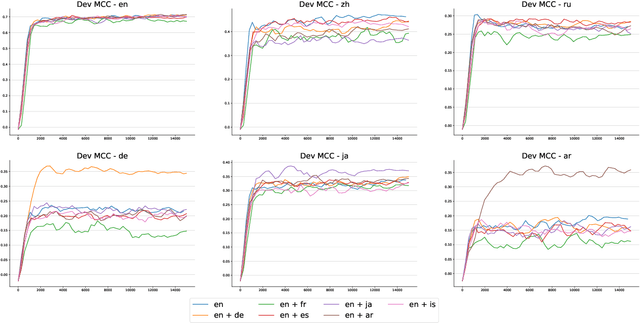
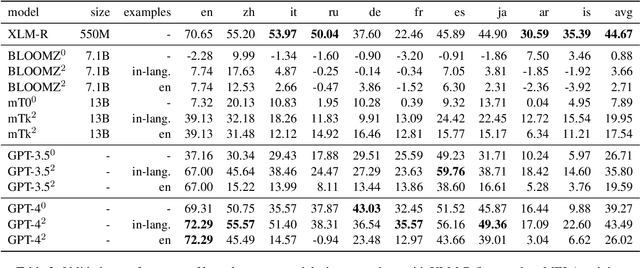
Recent benchmarks for Large Language Models (LLMs) have mostly focused on application-driven tasks such as complex reasoning and code generation, and this has led to a scarcity in purely linguistic evaluation of LLMs. Against this background, we introduce Multilingual Evaluation of Linguistic Acceptability -- MELA, the first multilingual benchmark on linguistic acceptability with 48K samples covering 10 languages from a diverse set of language families. We establish baselines of commonly used LLMs along with supervised models, and conduct cross-lingual transfer and multi-task learning experiments with XLM-R. In pursuit of multilingual interpretability, we analyze the weights of fine-tuned XLM-R to explore the possibility of identifying transfer difficulty between languages. Our results show that ChatGPT benefits much from in-context examples but still lags behind fine-tuned XLM-R, while the performance of GPT-4 is on par with fine-tuned XLM-R even in zero-shot setting. Cross-lingual and multi-task learning experiments show that unlike semantic tasks, in-language training data is crucial in acceptability judgements. Results in layerwise probing indicate that the upper layers of XLM-R become a task-specific but language-agnostic region for multilingual acceptability judgment. We also introduce the concept of conflicting weight, which could be a potential indicator for the difficulty of cross-lingual transfer between languages. Our data will be available at https://github.com/sjtu-compling/MELA.
Prompt position really matters in few-shot and zero-shot NLU tasks
May 23, 2023Prompt-based models have made remarkable advancements in the fields of zero-shot and few-shot learning, attracting a lot of attention from researchers. Developing an effective prompt template plays a critical role. However, prior studies have mainly focused on prompt vocabulary selection or embedding initialization with the reserved prompt position fixed. In this empirical study, we conduct the most comprehensive analysis to date of prompt position option for natural language understanding tasks. Our findings quantify the substantial impact prompt position has on model performance. We observe that the prompt position used in prior studies is often sub-optimal for both zero-shot and few-shot settings. These findings suggest prompt position optimisation as an interesting research direction alongside the existing focus on prompt engineering.