 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

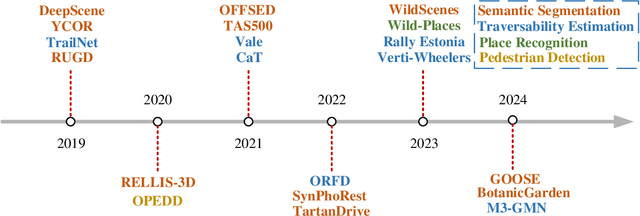

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
Occ-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction
Jun 07, 2023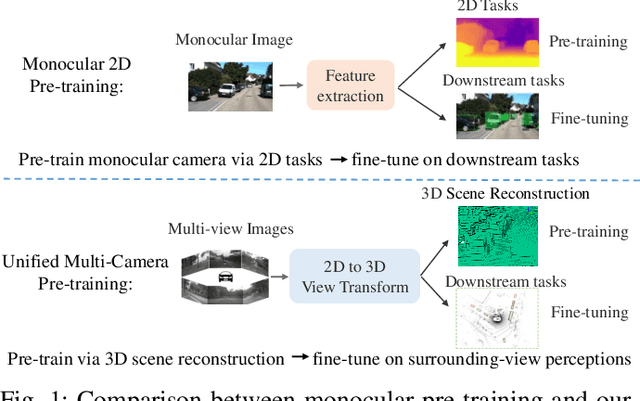



Multi-camera 3D perception has emerged as a prominent research field in autonomous driving, offering a viable and cost-effective alternative to LiDAR-based solutions. However, existing multi-camera algorithms primarily rely on monocular image pre-training, which overlooks the spatial and temporal correlations among different camera views. To address this limitation, we propose the first multi-camera unified pre-training framework called Occ-BEV, which involves initially reconstructing the 3D scene as the foundational stage and subsequently fine-tuning the model on downstream tasks. Specifically, a 3D decoder is designed for leveraging Bird's Eye View (BEV) features from multi-view images to predict the 3D geometric occupancy to enable the model to capture a more comprehensive understanding of the 3D environment. A significant benefit of Occ-BEV is its capability of utilizing a considerable volume of unlabeled image-LiDAR pairs for pre-training purposes. The proposed multi-camera unified pre-training framework demonstrates promising results in key tasks such as multi-camera 3D object detection and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, Occ-BEV shows a significant improvement of about 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. Codes are publicly available at https://github.com/chaytonmin/Occ-BEV.