 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMGDiff: Soccer Motion Generation using diffusion probabilistic models
Nov 25, 2024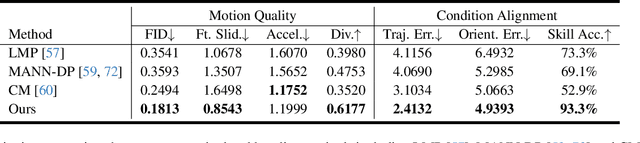


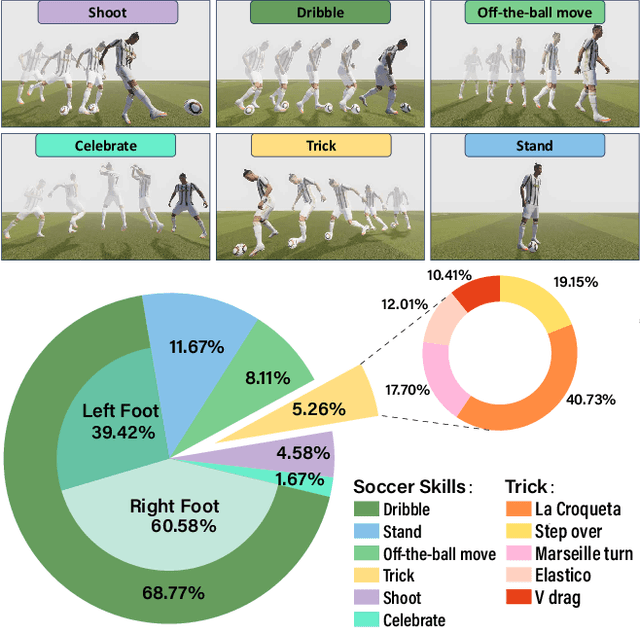
Soccer is a globally renowned sport with significant applications in video games and VR/AR. However, generating realistic soccer motions remains challenging due to the intricate interactions between the human player and the ball. In this paper, we introduce SMGDiff, a novel two-stage framework for generating real-time and user-controllable soccer motions. Our key idea is to integrate real-time character control with a powerful diffusion-based generative model, ensuring high-quality and diverse output motion. In the first stage, we instantly transform coarse user controls into diverse global trajectories of the character. In the second stage, we employ a transformer-based autoregressive diffusion model to generate soccer motions based on trajectory conditioning. We further incorporate a contact guidance module during inference to optimize the contact details for realistic ball-foot interactions. Moreover, we contribute a large-scale soccer motion dataset consisting of over 1.08 million frames of diverse soccer motions. Extensive experiments demonstrate that our SMGDiff significantly outperforms existing methods in terms of motion quality and condition alignment.
HandDiffuse: Generative Controllers for Two-Hand Interactions via Diffusion Models
Dec 08, 2023Existing hands datasets are largely short-range and the interaction is weak due to the self-occlusion and self-similarity of hands, which can not yet fit the need for interacting hands motion generation. To rescue the data scarcity, we propose HandDiffuse12.5M, a novel dataset that consists of temporal sequences with strong two-hand interactions. HandDiffuse12.5M has the largest scale and richest interactions among the existing two-hand datasets. We further present a strong baseline method HandDiffuse for the controllable motion generation of interacting hands using various controllers. Specifically, we apply the diffusion model as the backbone and design two motion representations for different controllers. To reduce artifacts, we also propose Interaction Loss which explicitly quantifies the dynamic interaction process. Our HandDiffuse enables various applications with vivid two-hand interactions, i.e., motion in-betweening and trajectory control. Experiments show that our method outperforms the state-of-the-art techniques in motion generation and can also contribute to data augmentation for other datasets. Our dataset, corresponding codes, and pre-trained models will be disseminated to the community for future research towards two-hand interaction modeling.
NeuralDome: A Neural Modeling Pipeline on Multi-View Human-Object Interactions
Dec 15, 2022
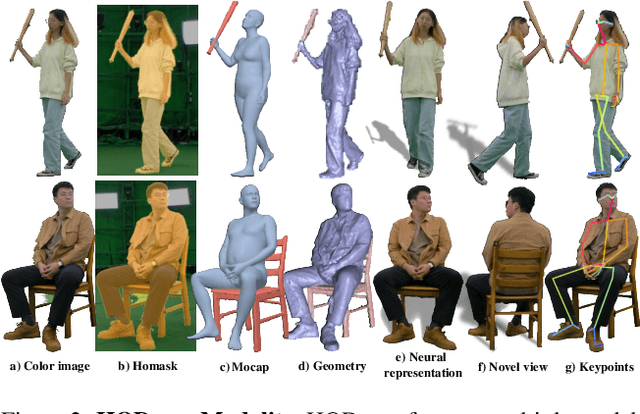
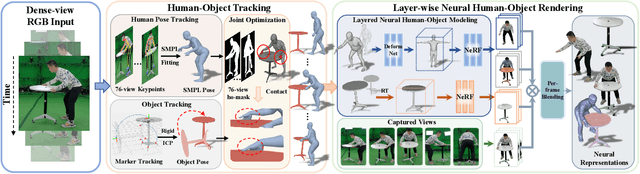
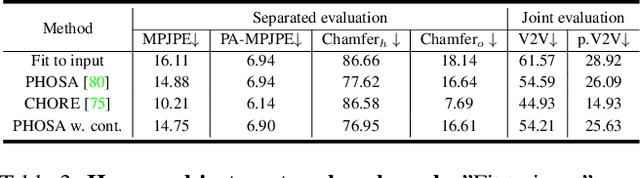
Humans constantly interact with objects in daily life tasks. Capturing such processes and subsequently conducting visual inferences from a fixed viewpoint suffers from occlusions, shape and texture ambiguities, motions, etc. To mitigate the problem, it is essential to build a training dataset that captures free-viewpoint interactions. We construct a dense multi-view dome to acquire a complex human object interaction dataset, named HODome, that consists of $\sim$75M frames on 10 subjects interacting with 23 objects. To process the HODome dataset, we develop NeuralDome, a layer-wise neural processing pipeline tailored for multi-view video inputs to conduct accurate tracking, geometry reconstruction and free-view rendering, for both human subjects and objects. Extensive experiments on the HODome dataset demonstrate the effectiveness of NeuralDome on a variety of inference, modeling, and rendering tasks. Both the dataset and the NeuralDome tools will be disseminated to the community for further development.