 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learned Distributed Multi-Robot Navigation with Reciprocal Velocity Obstacle Shaped Rewards
Paper and Code
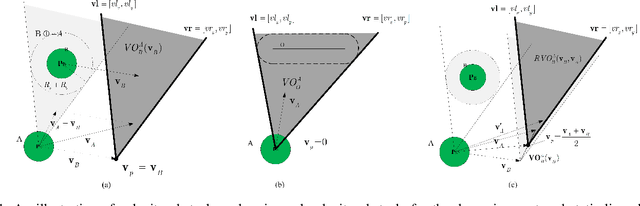
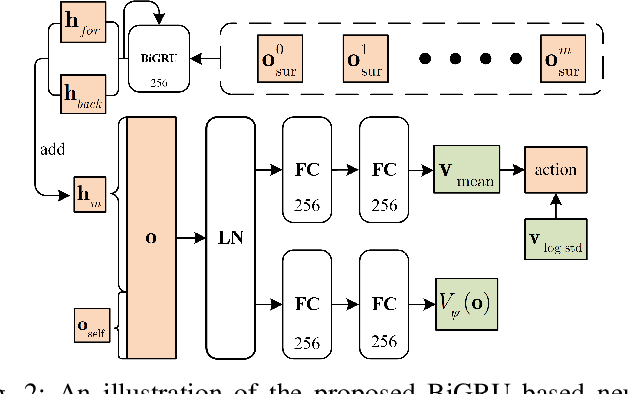
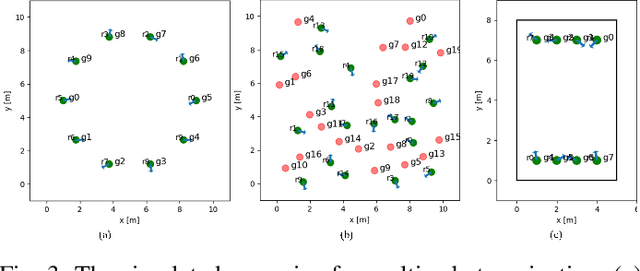
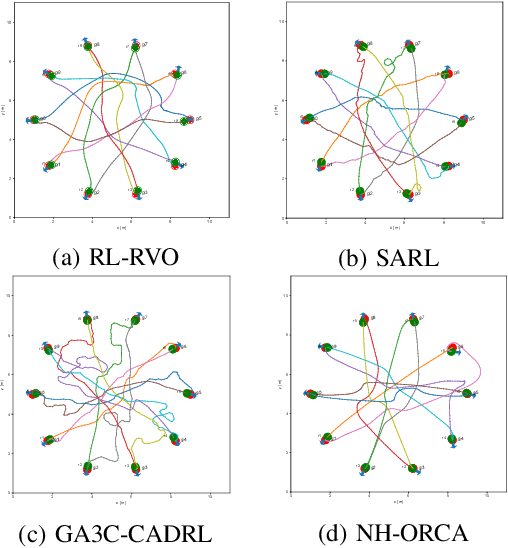
The challenges to solving the collision avoidance problem lie in adaptively choosing optimal robot velocities in complex scenarios full of interactive obstacles. In this paper, we propose a distributed approach for multi-robot navigation which combines the concept of reciprocal velocity obstacle (RVO) and the scheme of deep reinforcement learning (DRL) to solve the reciprocal collision avoidance problem under limited information. The novelty of this work is threefold: (1) using a set of sequential VO and RVO vectors to represent the interactive environmental states of static and dynamic obstacles, respectively; (2) developing a bidirectional recurrent module based neural network, which maps the states of a varying number of surrounding obstacles to the actions directly; (3) developing a RVO area and expected collision time based reward function to encourage reciprocal collision avoidance behaviors and trade off between collision risk and travel time. The proposed policy is trained through simulated scenarios and updated by the actor-critic based DRL algorithm. We validate the policy in complex environments with various numbers of differential drive robots and obstacles. The experiment results demonstrate that our approach outperforms the state-of-art methods and other learning based approaches in terms of the success rate, travel time, and average speed. Source code of this approach is available at https://github.com/hanruihua/rl_rvo_nav.