 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeServImage: An Image Generation and Editing Benchmark from Real-world Commercial Imaging Services
Apr 27, 2026Recent image generation and editing models demonstrate robust adherence to instructions and high visual quality on academic benchmarks. However, their performance on paid, real-world design projects remains uncertain. We introduce \textbf{ServImage}, a benchmark that explicitly correlates model outputs with economic value in commercial design projects. ServImage consists of (i) \textbf{\textit{ServImageBench}}: a dataset of 1.07k paid commercial design tasks and 2.05k designer deliverables totaling over \$295k, covering portrait, product, and digital content, along with 33k candidate images and 33k human annotations. (ii) \textbf{\textit{ServImageScore}}: an integrated scoring system that combines three quality dimensions: baseline requirements fulfilment, visual execution quality, and commercial necessity satisfaction. These three dimensions are designed to characterize the factors that drive human payment decisions and indicate whether an image is commercially acceptable. (iii) \textbf{\textit{ServImageModel}}: under this scoring system, we propose a payment prediction model trained on the human-annotated candidate images, achieving 82.00\% accuracy in predicting human payment decisions and producing calibrated payment probabilities. ServImage provides a comprehensive foundation for assessing the commercial viability of image generation models and offers a scalable resource for future research on economically grounded vision systems \href{https://github.com/FengxianJi/ServImage}{Github.}
M3MAD-Bench: Are Multi-Agent Debates Really Effective Across Domains and Modalities?
Jan 06, 2026As an agent-level reasoning and coordination paradigm, Multi-Agent Debate (MAD) orchestrates multiple agents through structured debate to improve answer quality and support complex reasoning. However, existing research on MAD suffers from two fundamental limitations: evaluations are conducted under fragmented and inconsistent settings, hindering fair comparison, and are largely restricted to single-modality scenarios that rely on textual inputs only. To address these gaps, we introduce M3MAD-Bench, a unified and extensible benchmark for evaluating MAD methods across Multi-domain tasks, Multi-modal inputs, and Multi-dimensional metrics. M3MAD-Bench establishes standardized protocols over five core task domains: Knowledge, Mathematics, Medicine, Natural Sciences, and Complex Reasoning, and systematically covers both pure text and vision-language datasets, enabling controlled cross-modality comparison. We evaluate MAD methods on nine base models spanning different architectures, scales, and modality capabilities. Beyond accuracy, M3MAD-Bench incorporates efficiency-oriented metrics such as token consumption and inference time, providing a holistic view of performance--cost trade-offs. Extensive experiments yield systematic insights into the effectiveness, robustness, and efficiency of MAD across text-only and multimodal scenarios. We believe M3MAD-Bench offers a reliable foundation for future research on standardized MAD evaluation. The code is available at http://github.com/liaolea/M3MAD-Bench.
When Personalization Tricks Detectors: The Feature-Inversion Trap in Machine-Generated Text Detection
Oct 14, 2025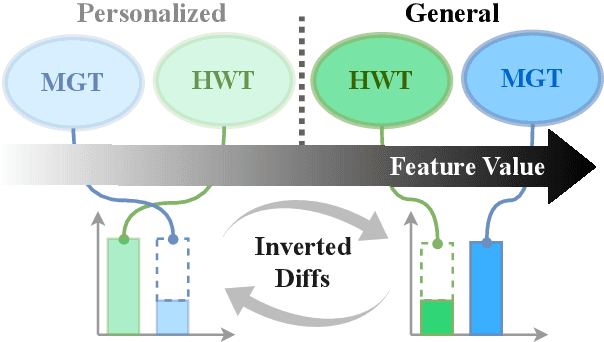

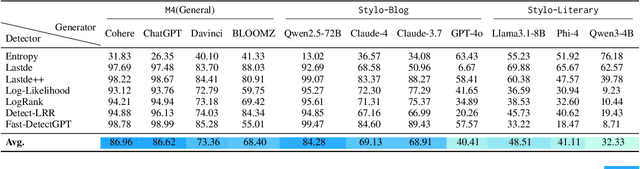
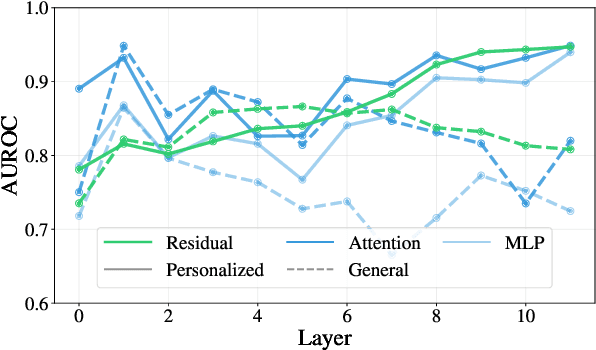
Large language models (LLMs) have grown more powerful in language generation, producing fluent text and even imitating personal style. Yet, this ability also heightens the risk of identity impersonation. To the best of our knowledge, no prior work has examined personalized machine-generated text (MGT) detection. In this paper, we introduce \dataset, the first benchmark for evaluating detector robustness in personalized settings, built from literary and blog texts paired with their LLM-generated imitations. Our experimental results demonstrate large performance gaps across detectors in personalized settings: some state-of-the-art models suffer significant drops. We attribute this limitation to the \textit{feature-inversion trap}, where features that are discriminative in general domains become inverted and misleading when applied to personalized text. Based on this finding, we propose \method, a simple and reliable way to predict detector performance changes in personalized settings. \method identifies latent directions corresponding to inverted features and constructs probe datasets that differ primarily along these features to evaluate detector dependence. Our experiments show that \method can accurately predict both the direction and the magnitude of post-transfer changes, showing 85\% correlation with the actual performance gaps. We hope that this work will encourage further research on personalized text detection.
SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
May 29, 2025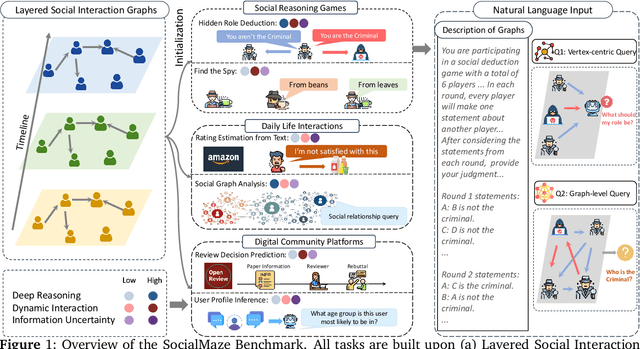
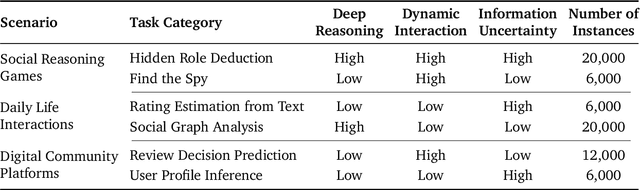
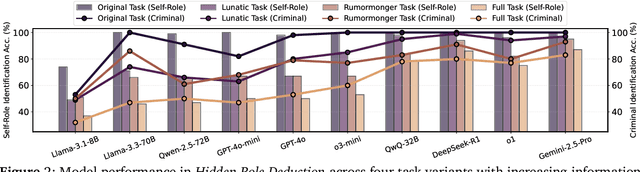
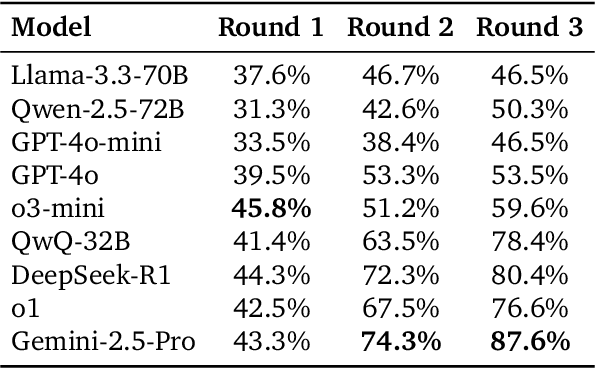
Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model's social reasoning ability - the capacity to interpret social contexts, infer others' mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze
Evaluate Bias without Manual Test Sets: A Concept Representation Perspective for LLMs
May 21, 2025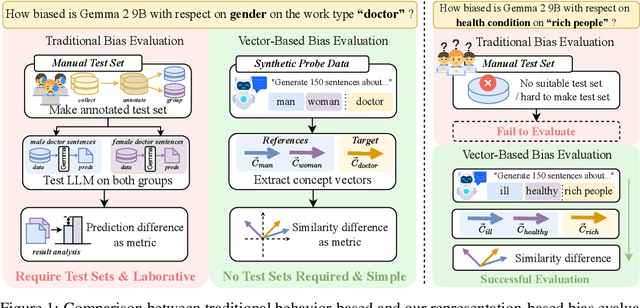
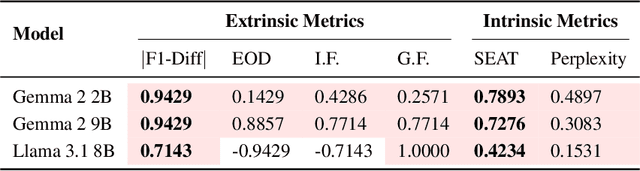
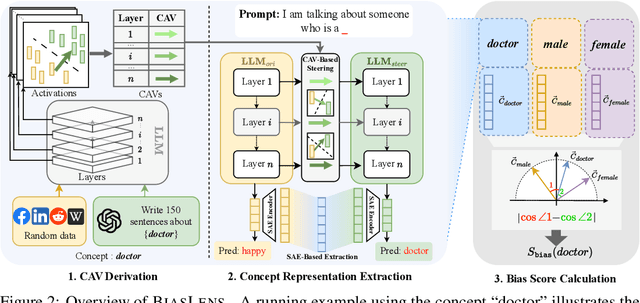
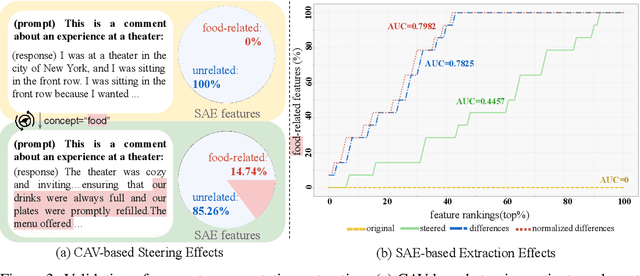
Bias in Large Language Models (LLMs) significantly undermines their reliability and fairness. We focus on a common form of bias: when two reference concepts in the model's concept space, such as sentiment polarities (e.g., "positive" and "negative"), are asymmetrically correlated with a third, target concept, such as a reviewing aspect, the model exhibits unintended bias. For instance, the understanding of "food" should not skew toward any particular sentiment. Existing bias evaluation methods assess behavioral differences of LLMs by constructing labeled data for different social groups and measuring model responses across them, a process that requires substantial human effort and captures only a limited set of social concepts. To overcome these limitations, we propose BiasLens, a test-set-free bias analysis framework based on the structure of the model's vector space. BiasLens combines Concept Activation Vectors (CAVs) with Sparse Autoencoders (SAEs) to extract interpretable concept representations, and quantifies bias by measuring the variation in representational similarity between the target concept and each of the reference concepts. Even without labeled data, BiasLens shows strong agreement with traditional bias evaluation metrics (Spearman correlation r > 0.85). Moreover, BiasLens reveals forms of bias that are difficult to detect using existing methods. For example, in simulated clinical scenarios, a patient's insurance status can cause the LLM to produce biased diagnostic assessments. Overall, BiasLens offers a scalable, interpretable, and efficient paradigm for bias discovery, paving the way for improving fairness and transparency in LLMs.
Audio Jailbreak: An Open Comprehensive Benchmark for Jailbreaking Large Audio-Language Models
May 21, 2025



The rise of Large Audio Language Models (LAMs) brings both potential and risks, as their audio outputs may contain harmful or unethical content. However, current research lacks a systematic, quantitative evaluation of LAM safety especially against jailbreak attacks, which are challenging due to the temporal and semantic nature of speech. To bridge this gap, we introduce AJailBench, the first benchmark specifically designed to evaluate jailbreak vulnerabilities in LAMs. We begin by constructing AJailBench-Base, a dataset of 1,495 adversarial audio prompts spanning 10 policy-violating categories, converted from textual jailbreak attacks using realistic text to speech synthesis. Using this dataset, we evaluate several state-of-the-art LAMs and reveal that none exhibit consistent robustness across attacks. To further strengthen jailbreak testing and simulate more realistic attack conditions, we propose a method to generate dynamic adversarial variants. Our Audio Perturbation Toolkit (APT) applies targeted distortions across time, frequency, and amplitude domains. To preserve the original jailbreak intent, we enforce a semantic consistency constraint and employ Bayesian optimization to efficiently search for perturbations that are both subtle and highly effective. This results in AJailBench-APT, an extended dataset of optimized adversarial audio samples. Our findings demonstrate that even small, semantically preserved perturbations can significantly reduce the safety performance of leading LAMs, underscoring the need for more robust and semantically aware defense mechanisms.
Adversarial Cooperative Rationalization: The Risk of Spurious Correlations in Even Clean Datasets
May 04, 2025
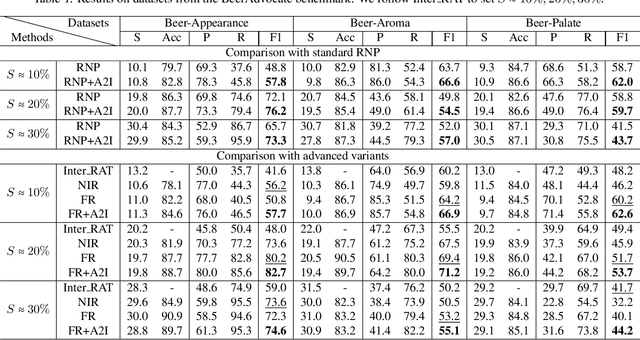

This study investigates the self-rationalization framework constructed with a cooperative game, where a generator initially extracts the most informative segment from raw input, and a subsequent predictor utilizes the selected subset for its input. The generator and predictor are trained collaboratively to maximize prediction accuracy. In this paper, we first uncover a potential caveat: such a cooperative game could unintentionally introduce a sampling bias during rationale extraction. Specifically, the generator might inadvertently create an incorrect correlation between the selected rationale candidate and the label, even when they are semantically unrelated in the original dataset. Subsequently, we elucidate the origins of this bias using both detailed theoretical analysis and empirical evidence. Our findings suggest a direction for inspecting these correlations through attacks, based on which we further introduce an instruction to prevent the predictor from learning the correlations. Through experiments on six text classification datasets and two graph classification datasets using three network architectures (GRUs, BERT, and GCN), we show that our method not only significantly outperforms recent rationalization methods, but also achieves comparable or even better results than a representative LLM (llama3.1-8b-instruct).
Word Form Matters: LLMs' Semantic Reconstruction under Typoglycemia
Mar 03, 2025Human readers can efficiently comprehend scrambled words, a phenomenon known as Typoglycemia, primarily by relying on word form; if word form alone is insufficient, they further utilize contextual cues for interpretation. While advanced large language models (LLMs) exhibit similar abilities, the underlying mechanisms remain unclear. To investigate this, we conduct controlled experiments to analyze the roles of word form and contextual information in semantic reconstruction and examine LLM attention patterns. Specifically, we first propose SemRecScore, a reliable metric to quantify the degree of semantic reconstruction, and validate its effectiveness. Using this metric, we study how word form and contextual information influence LLMs' semantic reconstruction ability, identifying word form as the core factor in this process. Furthermore, we analyze how LLMs utilize word form and find that they rely on specialized attention heads to extract and process word form information, with this mechanism remaining stable across varying levels of word scrambling. This distinction between LLMs' fixed attention patterns primarily focused on word form and human readers' adaptive strategy in balancing word form and contextual information provides insights into enhancing LLM performance by incorporating human-like, context-aware mechanisms.
Shaping the Safety Boundaries: Understanding and Defending Against Jailbreaks in Large Language Models
Dec 22, 2024



Jailbreaking in Large Language Models (LLMs) is a major security concern as it can deceive LLMs to generate harmful text. Yet, there is still insufficient understanding of how jailbreaking works, which makes it hard to develop effective defense strategies. We aim to shed more light into this issue: we conduct a detailed large-scale analysis of seven different jailbreak methods and find that these disagreements stem from insufficient observation samples. In particular, we introduce \textit{safety boundary}, and we find that jailbreaks shift harmful activations outside that safety boundary, where LLMs are less sensitive to harmful information. We also find that the low and the middle layers are critical in such shifts, while deeper layers have less impact. Leveraging on these insights, we propose a novel defense called \textbf{Activation Boundary Defense} (ABD), which adaptively constrains the activations within the safety boundary. We further use Bayesian optimization to selectively apply the defense method to the low and the middle layers. Our experiments on several benchmarks show that ABD achieves an average DSR of over 98\% against various forms of jailbreak attacks, with less than 2\% impact on the model's general capabilities.
MedTrinity-25M: A Large-scale Multimodal Dataset with Multigranular Annotations for Medicine
Aug 06, 2024This paper introduces MedTrinity-25M, a comprehensive, large-scale multimodal dataset for medicine, covering over 25 million images across 10 modalities, with multigranular annotations for more than 65 diseases. These enriched annotations encompass both global textual information, such as disease/lesion type, modality, region-specific descriptions, and inter-regional relationships, as well as detailed local annotations for regions of interest (ROIs), including bounding boxes, segmentation masks. Unlike existing approach which is limited by the availability of image-text pairs, we have developed the first automated pipeline that scales up multimodal data by generating multigranular visual and texual annotations (in the form of image-ROI-description triplets) without the need for any paired text descriptions. Specifically, data from over 90 different sources have been collected, preprocessed, and grounded using domain-specific expert models to identify ROIs related to abnormal regions. We then build a comprehensive knowledge base and prompt multimodal large language models to perform retrieval-augmented generation with the identified ROIs as guidance, resulting in multigranular texual descriptions. Compared to existing datasets, MedTrinity-25M provides the most enriched annotations, supporting a comprehensive range of multimodal tasks such as captioning and report generation, as well as vision-centric tasks like classification and segmentation. Pretraining on MedTrinity-25M, our model achieves state-of-the-art performance on VQA-RAD and PathVQA, surpassing both multimodal large language models and other representative SoTA approaches. This dataset can also be utilized to support large-scale pre-training of multimodal medical AI models, contributing to the development of future foundation models in the medical domain.