 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Evaluating the Edit Locality of LLM Model Editing Properly?
Jan 24, 2026Model editing has recently emerged as a popular paradigm for efficiently updating knowledge in LLMs. A central desideratum of updating knowledge is to balance editing efficacy, i.e., the successful injection of target knowledge, and specificity (also known as edit locality), i.e., the preservation of existing non-target knowledge. However, we find that existing specificity evaluation protocols are inadequate for this purpose. We systematically elaborated on the three fundamental issues it faces. Beyond the conceptual issues, we further empirically demonstrate that existing specificity metrics are weakly correlated with the strength of specificity regularizers. We also find that current metrics lack sufficient sensitivity, rendering them ineffective at distinguishing the specificity performance of different methods. Finally, we propose a constructive evaluation protocol. Under this protocol, the conflict between open-ended LLMs and the assumption of determined answers is eliminated, query-independent fluency biases are avoided, and the evaluation strictness can be smoothly adjusted within a near-continuous space. Experiments across various LLMs, datasets, and editing methods show that metrics derived from the proposed protocol are more sensitive to changes in the strength of specificity regularizers and exhibit strong correlation with them, enabling more fine-grained discrimination of different methods' knowledge preservation capabilities.
Is Model Editing Built on Sand? Revealing Its Illusory Success and Fragile Foundation
Oct 01, 2025



Large language models (LLMs) inevitably encode outdated or incorrect knowledge. Updating, deleting, and forgetting such knowledge is important for alignment, safety, and other issues. To address this issue, model editing has emerged as a promising paradigm: by precisely editing a small subset of parameters such that a specific fact is updated while preserving other knowledge. Despite its great success reported in previous papers, we find the apparent reliability of editing rests on a fragile foundation and the current literature is largely driven by illusory success. The fundamental goal of steering the model's output toward a target with minimal modification would encourage exploiting hidden shortcuts, rather than utilizing real semantics. This problem directly challenges the feasibility of the current model editing literature at its very foundation, as shortcuts are inherently at odds with robust knowledge integration. Coincidentally, this issue has long been obscured by evaluation frameworks that lack the design of negative examples. To uncover it, we systematically develop a suite of new evaluation methods. Strikingly, we find that state-of-the-art approaches collapse even under the simplest negation queries. Our empirical evidence shows that editing is likely to be based on shortcuts rather than full semantics, calling for an urgent reconsideration of the very basis of model editing before further advancements can be meaningfully pursued.
Adversarial Cooperative Rationalization: The Risk of Spurious Correlations in Even Clean Datasets
May 04, 2025
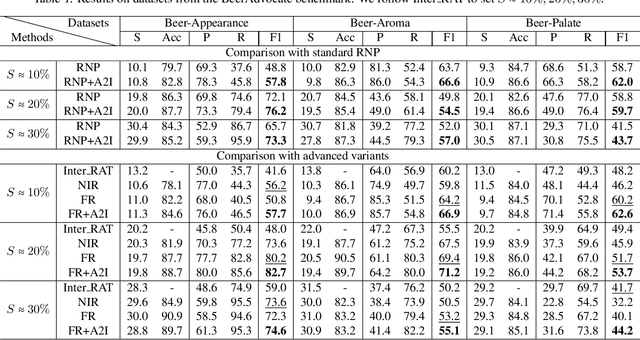

This study investigates the self-rationalization framework constructed with a cooperative game, where a generator initially extracts the most informative segment from raw input, and a subsequent predictor utilizes the selected subset for its input. The generator and predictor are trained collaboratively to maximize prediction accuracy. In this paper, we first uncover a potential caveat: such a cooperative game could unintentionally introduce a sampling bias during rationale extraction. Specifically, the generator might inadvertently create an incorrect correlation between the selected rationale candidate and the label, even when they are semantically unrelated in the original dataset. Subsequently, we elucidate the origins of this bias using both detailed theoretical analysis and empirical evidence. Our findings suggest a direction for inspecting these correlations through attacks, based on which we further introduce an instruction to prevent the predictor from learning the correlations. Through experiments on six text classification datasets and two graph classification datasets using three network architectures (GRUs, BERT, and GCN), we show that our method not only significantly outperforms recent rationalization methods, but also achieves comparable or even better results than a representative LLM (llama3.1-8b-instruct).
Breaking Free from MMI: A New Frontier in Rationalization by Probing Input Utilization
Mar 08, 2025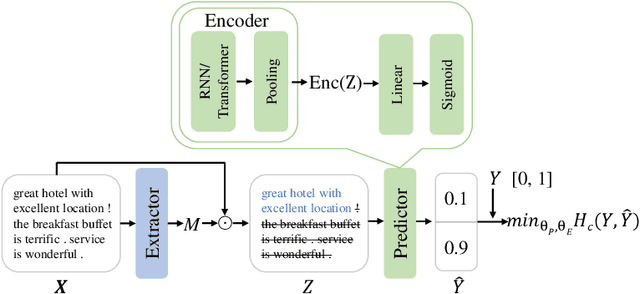

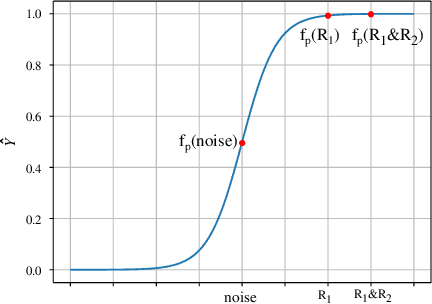

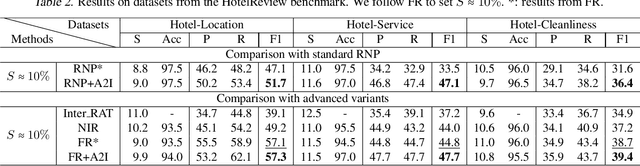
Extracting a small subset of crucial rationales from the full input is a key problem in explainability research. The most widely used fundamental criterion for rationale extraction is the maximum mutual information (MMI) criterion. In this paper, we first demonstrate that MMI suffers from diminishing marginal returns. Once part of the rationale has been identified, finding the remaining portions contributes only marginally to increasing the mutual information, making it difficult to use MMI to locate the rest. In contrast to MMI that aims to reproduce the prediction, we seek to identify the parts of the input that the network can actually utilize. This is achieved by comparing how different rationale candidates match the capability space of the weight matrix. The weight matrix of a neural network is typically low-rank, meaning that the linear combinations of its column vectors can only cover part of the directions in a high-dimensional space (high-dimension: the dimensions of an input vector). If an input is fully utilized by the network, {it generally matches these directions (e.g., a portion of a hypersphere), resulting in a representation with a high norm. Conversely, if an input primarily falls outside (orthogonal to) these directions}, its representation norm will approach zero, behaving like noise that the network cannot effectively utilize. Building on this, we propose using the norms of rationale candidates as an alternative objective to MMI. Through experiments on four text classification datasets and one graph classification dataset using three network architectures (GRUs, BERT, and GCN), we show that our method outperforms MMI and its improved variants in identifying better rationales. We also compare our method with a representative LLM (llama-3.1-8b-instruct) and find that our simple method gets comparable results to it and can sometimes even outperform it.
Is the MMI Criterion Necessary for Interpretability? Degenerating Non-causal Features to Plain Noise for Self-Rationalization
Oct 08, 2024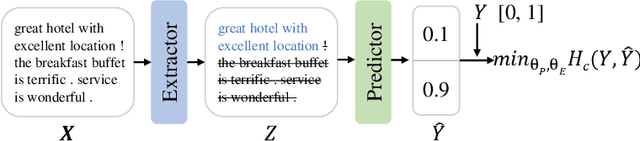
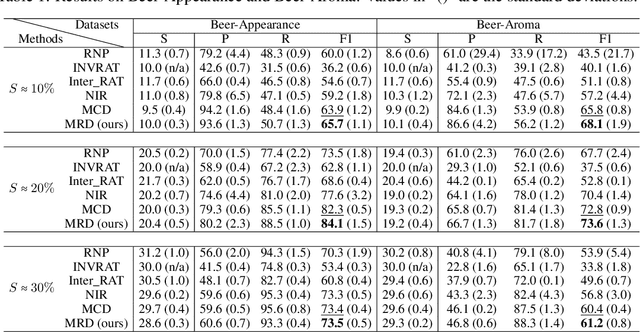
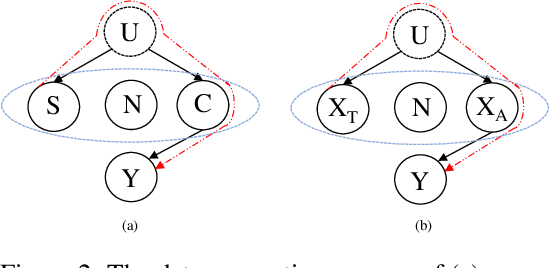
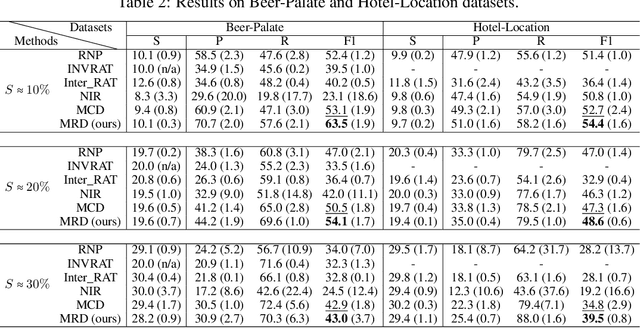
An important line of research in the field of explainability is to extract a small subset of crucial rationales from the full input. The most widely used criterion for rationale extraction is the maximum mutual information (MMI) criterion. However, in certain datasets, there are spurious features non-causally correlated with the label and also get high mutual information, complicating the loss landscape of MMI. Although some penalty-based methods have been developed to penalize the spurious features (e.g., invariance penalty, intervention penalty, etc) to help MMI work better, these are merely remedial measures. In the optimization objectives of these methods, spurious features are still distinguished from plain noise, which hinders the discovery of causal rationales. This paper aims to develop a new criterion that treats spurious features as plain noise, allowing the model to work on datasets rich in spurious features as if it were working on clean datasets, thereby making rationale extraction easier. We theoretically observe that removing either plain noise or spurious features from the input does not alter the conditional distribution of the remaining components relative to the task label. However, significant changes in the conditional distribution occur only when causal features are eliminated. Based on this discovery, the paper proposes a criterion for \textbf{M}aximizing the \textbf{R}emaining \textbf{D}iscrepancy (MRD). Experiments on six widely used datasets show that our MRD criterion improves rationale quality (measured by the overlap with human-annotated rationales) by up to $10.4\%$ as compared to several recent competitive MMI variants. Code: \url{https://github.com/jugechengzi/Rationalization-MRD}.
Enhancing the Rationale-Input Alignment for Self-explaining Rationalization
Dec 15, 2023
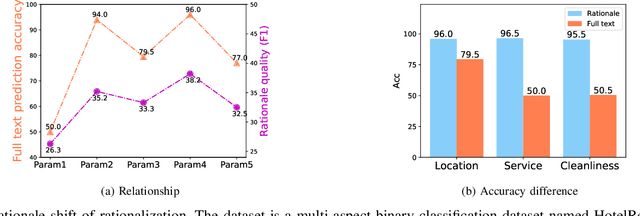
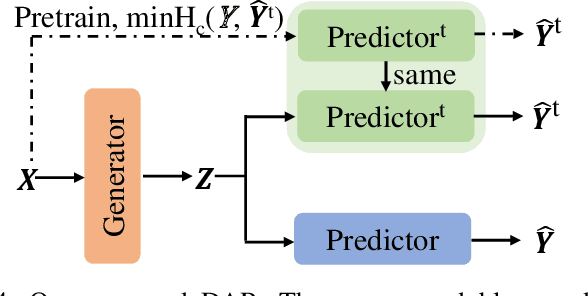
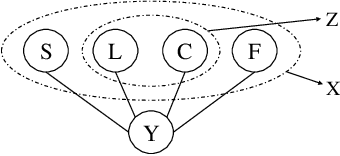
Rationalization empowers deep learning models with self-explaining capabilities through a cooperative game, where a generator selects a semantically consistent subset of the input as a rationale, and a subsequent predictor makes predictions based on the selected rationale. In this paper, we discover that rationalization is prone to a problem named \emph{rationale shift}, which arises from the algorithmic bias of the cooperative game. Rationale shift refers to a situation where the semantics of the selected rationale may deviate from the original input, but the predictor still produces accurate predictions based on the deviation, resulting in a compromised generator with misleading feedback. To address this issue, we first demonstrate the importance of the alignment between the rationale and the full input through both empirical observations and theoretical analysis. Subsequently, we introduce a novel approach called DAR (\textbf{D}iscriminatively \textbf{A}ligned \textbf{R}ationalization), which utilizes an auxiliary module pretrained on the full input to discriminatively align the selected rationale and the original input. We theoretically illustrate how DAR accomplishes the desired alignment, thereby overcoming the rationale shift problem. The experiments on two widely used real-world benchmarks show that the proposed method significantly improves the explanation quality (measured by the overlap between the model-selected explanation and the human-annotated rationale) as compared to state-of-the-art techniques. Additionally, results on two synthetic settings further validate the effectiveness of DAR in addressing the rationale shift problem.
D-Separation for Causal Self-Explanation
Sep 23, 2023Rationalization is a self-explaining framework for NLP models. Conventional work typically uses the maximum mutual information (MMI) criterion to find the rationale that is most indicative of the target label. However, this criterion can be influenced by spurious features that correlate with the causal rationale or the target label. Instead of attempting to rectify the issues of the MMI criterion, we propose a novel criterion to uncover the causal rationale, termed the Minimum Conditional Dependence (MCD) criterion, which is grounded on our finding that the non-causal features and the target label are \emph{d-separated} by the causal rationale. By minimizing the dependence between the unselected parts of the input and the target label conditioned on the selected rationale candidate, all the causes of the label are compelled to be selected. In this study, we employ a simple and practical measure of dependence, specifically the KL-divergence, to validate our proposed MCD criterion. Empirically, we demonstrate that MCD improves the F1 score by up to $13.7\%$ compared to previous state-of-the-art MMI-based methods. Our code is available at: \url{https://github.com/jugechengzi/Rationalization-MCD}.