 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs the MMI Criterion Necessary for Interpretability? Degenerating Non-causal Features to Plain Noise for Self-Rationalization
Oct 08, 2024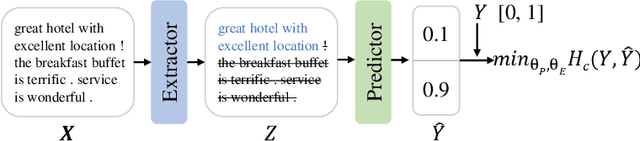
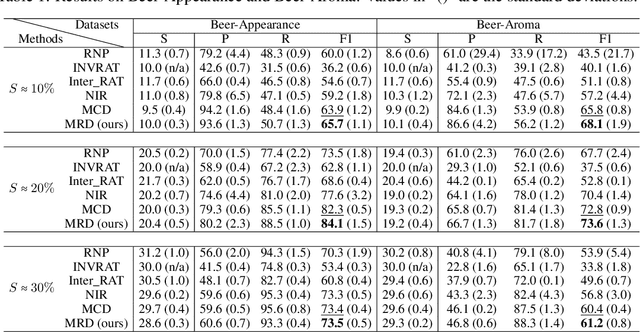
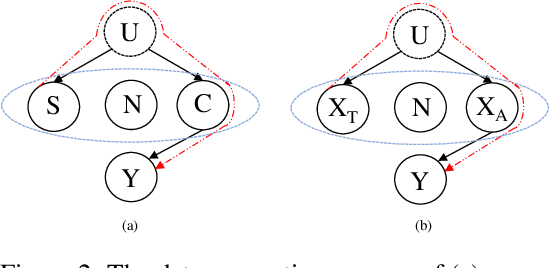
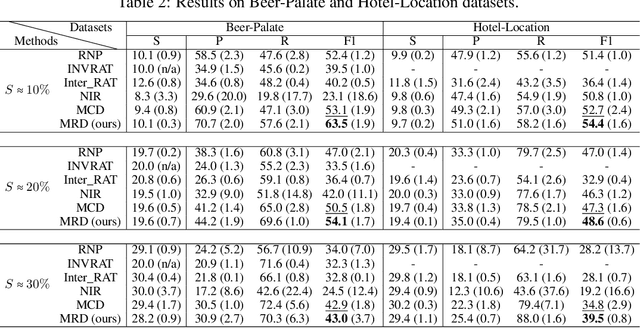
An important line of research in the field of explainability is to extract a small subset of crucial rationales from the full input. The most widely used criterion for rationale extraction is the maximum mutual information (MMI) criterion. However, in certain datasets, there are spurious features non-causally correlated with the label and also get high mutual information, complicating the loss landscape of MMI. Although some penalty-based methods have been developed to penalize the spurious features (e.g., invariance penalty, intervention penalty, etc) to help MMI work better, these are merely remedial measures. In the optimization objectives of these methods, spurious features are still distinguished from plain noise, which hinders the discovery of causal rationales. This paper aims to develop a new criterion that treats spurious features as plain noise, allowing the model to work on datasets rich in spurious features as if it were working on clean datasets, thereby making rationale extraction easier. We theoretically observe that removing either plain noise or spurious features from the input does not alter the conditional distribution of the remaining components relative to the task label. However, significant changes in the conditional distribution occur only when causal features are eliminated. Based on this discovery, the paper proposes a criterion for \textbf{M}aximizing the \textbf{R}emaining \textbf{D}iscrepancy (MRD). Experiments on six widely used datasets show that our MRD criterion improves rationale quality (measured by the overlap with human-annotated rationales) by up to $10.4\%$ as compared to several recent competitive MMI variants. Code: \url{https://github.com/jugechengzi/Rationalization-MRD}.
Enhancing the Rationale-Input Alignment for Self-explaining Rationalization
Dec 15, 2023
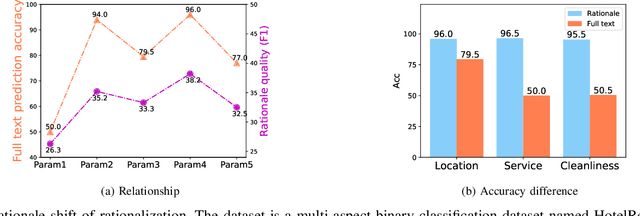
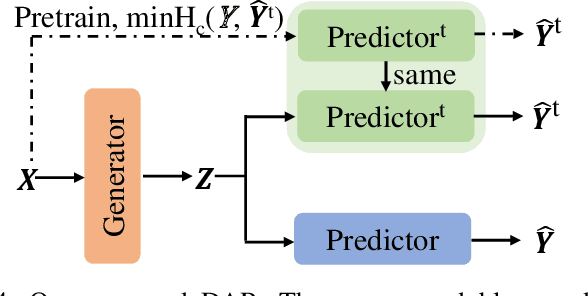
Rationalization empowers deep learning models with self-explaining capabilities through a cooperative game, where a generator selects a semantically consistent subset of the input as a rationale, and a subsequent predictor makes predictions based on the selected rationale. In this paper, we discover that rationalization is prone to a problem named \emph{rationale shift}, which arises from the algorithmic bias of the cooperative game. Rationale shift refers to a situation where the semantics of the selected rationale may deviate from the original input, but the predictor still produces accurate predictions based on the deviation, resulting in a compromised generator with misleading feedback. To address this issue, we first demonstrate the importance of the alignment between the rationale and the full input through both empirical observations and theoretical analysis. Subsequently, we introduce a novel approach called DAR (\textbf{D}iscriminatively \textbf{A}ligned \textbf{R}ationalization), which utilizes an auxiliary module pretrained on the full input to discriminatively align the selected rationale and the original input. We theoretically illustrate how DAR accomplishes the desired alignment, thereby overcoming the rationale shift problem. The experiments on two widely used real-world benchmarks show that the proposed method significantly improves the explanation quality (measured by the overlap between the model-selected explanation and the human-annotated rationale) as compared to state-of-the-art techniques. Additionally, results on two synthetic settings further validate the effectiveness of DAR in addressing the rationale shift problem.
D-Separation for Causal Self-Explanation
Sep 23, 2023

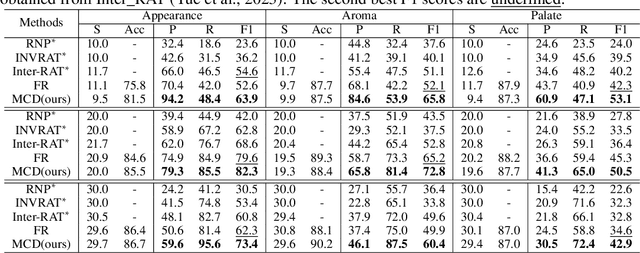

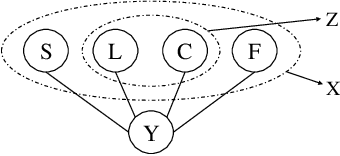
Rationalization is a self-explaining framework for NLP models. Conventional work typically uses the maximum mutual information (MMI) criterion to find the rationale that is most indicative of the target label. However, this criterion can be influenced by spurious features that correlate with the causal rationale or the target label. Instead of attempting to rectify the issues of the MMI criterion, we propose a novel criterion to uncover the causal rationale, termed the Minimum Conditional Dependence (MCD) criterion, which is grounded on our finding that the non-causal features and the target label are \emph{d-separated} by the causal rationale. By minimizing the dependence between the unselected parts of the input and the target label conditioned on the selected rationale candidate, all the causes of the label are compelled to be selected. In this study, we employ a simple and practical measure of dependence, specifically the KL-divergence, to validate our proposed MCD criterion. Empirically, we demonstrate that MCD improves the F1 score by up to $13.7\%$ compared to previous state-of-the-art MMI-based methods. Our code is available at: \url{https://github.com/jugechengzi/Rationalization-MCD}.
Decoupled Rationalization with Asymmetric Learning Rates: A Flexible Lipschitz Restraint
May 26, 2023A self-explaining rationalization model is generally constructed by a cooperative game where a generator selects the most human-intelligible pieces from the input text as rationales, followed by a predictor that makes predictions based on the selected rationales. However, such a cooperative game may incur the degeneration problem where the predictor overfits to the uninformative pieces generated by a not yet well-trained generator and in turn, leads the generator to converge to a sub-optimal model that tends to select senseless pieces. In this paper, we theoretically bridge degeneration with the predictor's Lipschitz continuity. Then, we empirically propose a simple but effective method named DR, which can naturally and flexibly restrain the Lipschitz constant of the predictor, to address the problem of degeneration. The main idea of DR is to decouple the generator and predictor to allocate them with asymmetric learning rates. A series of experiments conducted on two widely used benchmarks have verified the effectiveness of the proposed method. Codes: \href{https://github.com/jugechengzi/Rationalization-DR}{https://github.com/jugechengzi/Rationalization-DR}.