 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Rationale-Input Alignment for Self-explaining Rationalization
Paper and Code

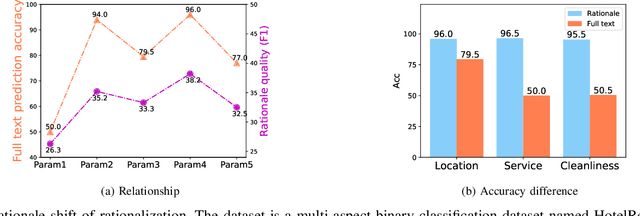
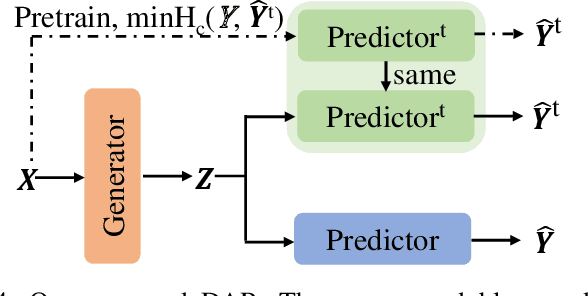
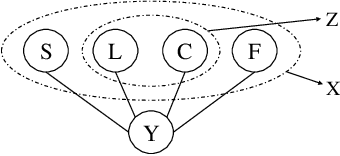
Rationalization empowers deep learning models with self-explaining capabilities through a cooperative game, where a generator selects a semantically consistent subset of the input as a rationale, and a subsequent predictor makes predictions based on the selected rationale. In this paper, we discover that rationalization is prone to a problem named \emph{rationale shift}, which arises from the algorithmic bias of the cooperative game. Rationale shift refers to a situation where the semantics of the selected rationale may deviate from the original input, but the predictor still produces accurate predictions based on the deviation, resulting in a compromised generator with misleading feedback. To address this issue, we first demonstrate the importance of the alignment between the rationale and the full input through both empirical observations and theoretical analysis. Subsequently, we introduce a novel approach called DAR (\textbf{D}iscriminatively \textbf{A}ligned \textbf{R}ationalization), which utilizes an auxiliary module pretrained on the full input to discriminatively align the selected rationale and the original input. We theoretically illustrate how DAR accomplishes the desired alignment, thereby overcoming the rationale shift problem. The experiments on two widely used real-world benchmarks show that the proposed method significantly improves the explanation quality (measured by the overlap between the model-selected explanation and the human-annotated rationale) as compared to state-of-the-art techniques. Additionally, results on two synthetic settings further validate the effectiveness of DAR in addressing the rationale shift problem.