 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs the MMI Criterion Necessary for Interpretability? Degenerating Non-causal Features to Plain Noise for Self-Rationalization
Paper and Code
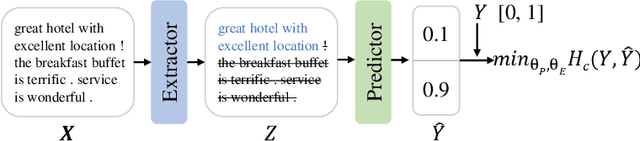
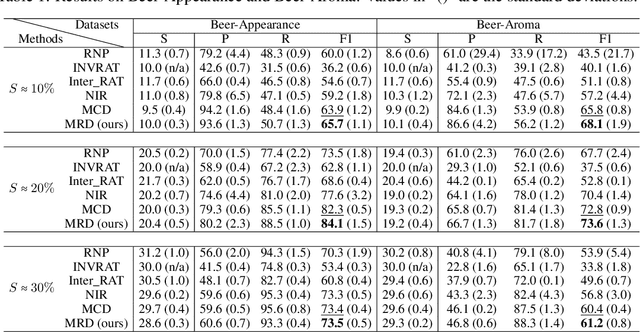
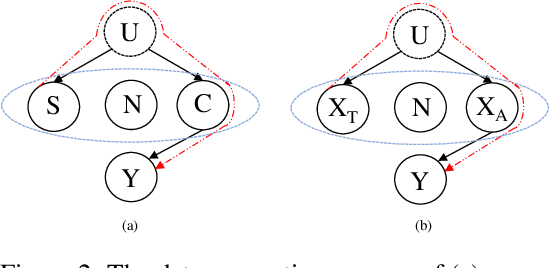
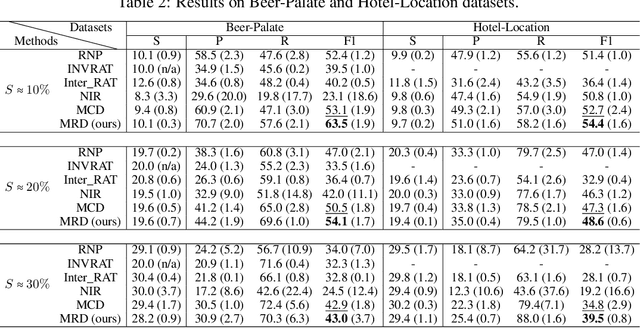
An important line of research in the field of explainability is to extract a small subset of crucial rationales from the full input. The most widely used criterion for rationale extraction is the maximum mutual information (MMI) criterion. However, in certain datasets, there are spurious features non-causally correlated with the label and also get high mutual information, complicating the loss landscape of MMI. Although some penalty-based methods have been developed to penalize the spurious features (e.g., invariance penalty, intervention penalty, etc) to help MMI work better, these are merely remedial measures. In the optimization objectives of these methods, spurious features are still distinguished from plain noise, which hinders the discovery of causal rationales. This paper aims to develop a new criterion that treats spurious features as plain noise, allowing the model to work on datasets rich in spurious features as if it were working on clean datasets, thereby making rationale extraction easier. We theoretically observe that removing either plain noise or spurious features from the input does not alter the conditional distribution of the remaining components relative to the task label. However, significant changes in the conditional distribution occur only when causal features are eliminated. Based on this discovery, the paper proposes a criterion for \textbf{M}aximizing the \textbf{R}emaining \textbf{D}iscrepancy (MRD). Experiments on six widely used datasets show that our MRD criterion improves rationale quality (measured by the overlap with human-annotated rationales) by up to $10.4\%$ as compared to several recent competitive MMI variants. Code: \url{https://github.com/jugechengzi/Rationalization-MRD}.