 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Logical Reasoning in LLMs: A Fine-Grained Evaluation and Supervision Study
Jun 05, 2025Logical reasoning is a core capability for many applications of large language models (LLMs), yet existing benchmarks often rely solely on final-answer accuracy, failing to capture the quality and structure of the reasoning process. We propose FineLogic, a fine-grained evaluation framework that assesses logical reasoning across three dimensions: overall benchmark accuracy, stepwise soundness, and representation-level alignment. In addition, to better understand how reasoning capabilities emerge, we conduct a comprehensive study on the effects of supervision format during fine-tuning. We construct four supervision styles (one natural language and three symbolic variants) and train LLMs under each. Our findings reveal that natural language supervision yields strong generalization even on out-of-distribution and long-context tasks, while symbolic reasoning styles promote more structurally sound and atomic inference chains. Further, our representation-level probing shows that fine-tuning primarily improves reasoning behaviors through step-by-step generation, rather than enhancing shortcut prediction or internalized correctness. Together, our framework and analysis provide a more rigorous and interpretable lens for evaluating and improving logical reasoning in LLMs.
Seeing the Invisible: Machine learning-Based QPI Kernel Extraction via Latent Alignment
Jun 05, 2025Quasiparticle interference (QPI) imaging is a powerful tool for probing electronic structures in quantum materials, but extracting the single-scatterer QPI pattern (i.e., the kernel) from a multi-scatterer image remains a fundamentally ill-posed inverse problem. In this work, we propose the first AI-based framework for QPI kernel extraction. We introduce a two-step learning strategy that decouples kernel representation learning from observation-to-kernel inference. In the first step, we train a variational autoencoder to learn a compact latent space of scattering kernels. In the second step, we align the latent representation of QPI observations with those of the pre-learned kernels using a dedicated encoder. This design enables the model to infer kernels robustly even under complex, entangled scattering conditions. We construct a diverse and physically realistic QPI dataset comprising 100 unique kernels and evaluate our method against a direct one-step baseline. Experimental results demonstrate that our approach achieves significantly higher extraction accuracy, and improved generalization to unseen kernels.
SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
May 29, 2025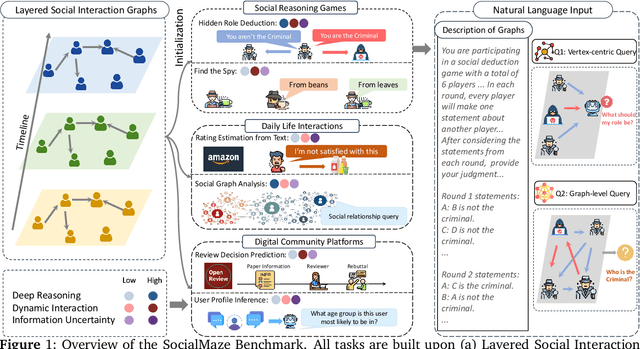
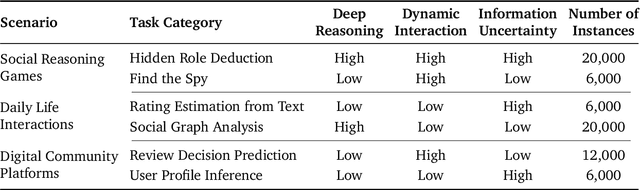
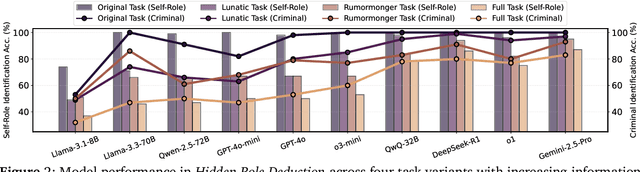
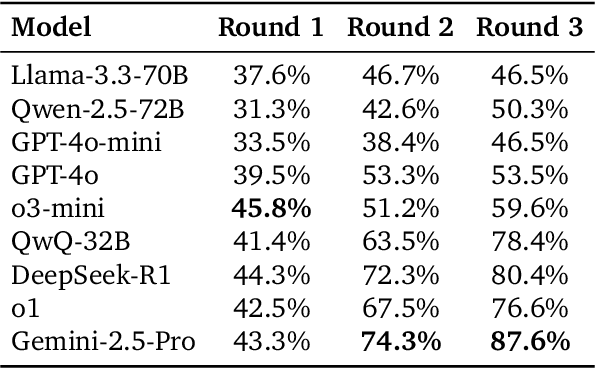
Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model's social reasoning ability - the capacity to interpret social contexts, infer others' mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze
Beyond Single-Value Metrics: Evaluating and Enhancing LLM Unlearning with Cognitive Diagnosis
Feb 19, 2025Due to the widespread use of LLMs and the rising critical ethical and safety concerns, LLM unlearning methods have been developed to remove harmful knowledge and undesirable capabilities. In this context, evaluations are mostly based on single-value metrics such as QA accuracy. However, these metrics often fail to capture the nuanced retention of harmful knowledge components, making it difficult to assess the true effectiveness of unlearning. To address this issue, we propose UNCD (UNlearning evaluation via Cognitive Diagnosis), a novel framework that leverages Cognitive Diagnosis Modeling for fine-grained evaluation of LLM unlearning. Our dedicated benchmark, UNCD-Cyber, provides a detailed assessment of the removal of dangerous capabilities. Moreover, we introduce UNCD-Agent, which refines unlearning by diagnosing knowledge remnants and generating targeted unlearning data. Extensive experiments across eight unlearning methods and two base models demonstrate that UNCD not only enhances evaluation but also effectively facilitates the removal of harmful LLM abilities.
UOE: Unlearning One Expert Is Enough For Mixture-of-experts LLMS
Nov 27, 2024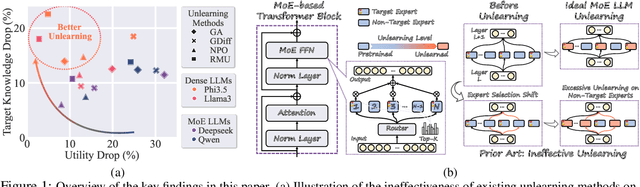

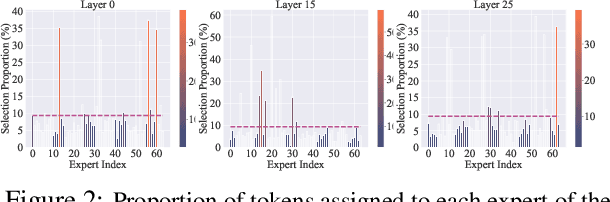
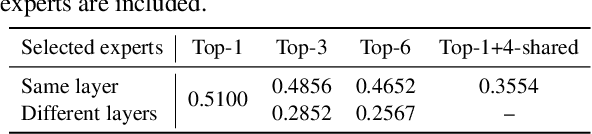
Recent advancements in large language model (LLM) unlearning have shown remarkable success in removing unwanted data-model influences while preserving the model's utility for legitimate knowledge. However, despite these strides, sparse Mixture-of-Experts (MoE) LLMs--a key subset of the LLM family--have received little attention and remain largely unexplored in the context of unlearning. As MoE LLMs are celebrated for their exceptional performance and highly efficient inference processes, we ask: How can unlearning be performed effectively and efficiently on MoE LLMs? And will traditional unlearning methods be applicable to MoE architectures? Our pilot study shows that the dynamic routing nature of MoE LLMs introduces unique challenges, leading to substantial utility drops when existing unlearning methods are applied. Specifically, unlearning disrupts the router's expert selection, causing significant selection shift from the most unlearning target-related experts to irrelevant ones. As a result, more experts than necessary are affected, leading to excessive forgetting and loss of control over which knowledge is erased. To address this, we propose a novel single-expert unlearning framework, referred to as UOE, for MoE LLMs. Through expert attribution, unlearning is concentrated on the most actively engaged expert for the specified knowledge. Concurrently, an anchor loss is applied to the router to stabilize the active state of this targeted expert, ensuring focused and controlled unlearning that preserves model utility. The proposed UOE framework is also compatible with various unlearning algorithms. Extensive experiments demonstrate that UOE enhances both forget quality up to 5% and model utility by 35% on MoE LLMs across various benchmarks, LLM architectures, while only unlearning 0.06% of the model parameters.
Social Science Meets LLMs: How Reliable Are Large Language Models in Social Simulations?
Oct 30, 2024


Large Language Models (LLMs) are increasingly employed for simulations, enabling applications in role-playing agents and Computational Social Science (CSS). However, the reliability of these simulations is under-explored, which raises concerns about the trustworthiness of LLMs in these applications. In this paper, we aim to answer ``How reliable is LLM-based simulation?'' To address this, we introduce TrustSim, an evaluation dataset covering 10 CSS-related topics, to systematically investigate the reliability of the LLM simulation. We conducted experiments on 14 LLMs and found that inconsistencies persist in the LLM-based simulated roles. In addition, the consistency level of LLMs does not strongly correlate with their general performance. To enhance the reliability of LLMs in simulation, we proposed Adaptive Learning Rate Based ORPO (AdaORPO), a reinforcement learning-based algorithm to improve the reliability in simulation across 7 LLMs. Our research provides a foundation for future studies to explore more robust and trustworthy LLM-based simulations.
Defending Jailbreak Prompts via In-Context Adversarial Game
Feb 20, 2024
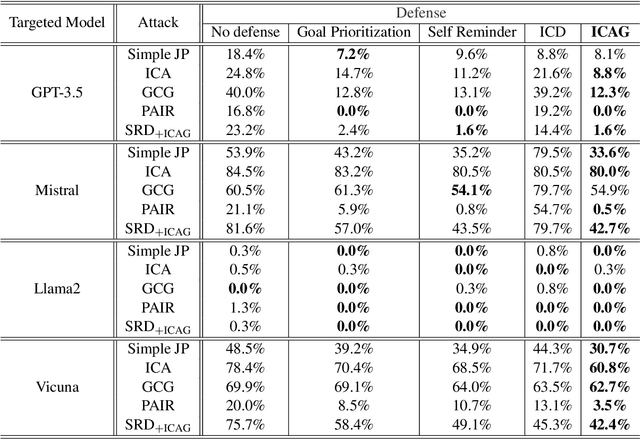

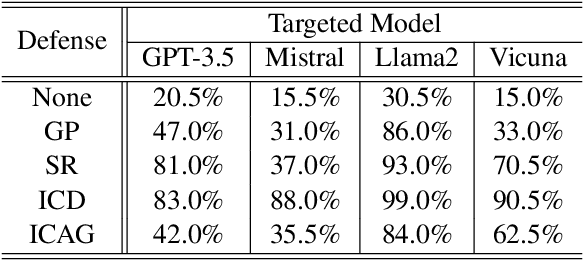
Large Language Models (LLMs) demonstrate remarkable capabilities across diverse applications. However, concerns regarding their security, particularly the vulnerability to jailbreak attacks, persist. Drawing inspiration from adversarial training in deep learning and LLM agent learning processes, we introduce the In-Context Adversarial Game (ICAG) for defending against jailbreaks without the need for fine-tuning. ICAG leverages agent learning to conduct an adversarial game, aiming to dynamically extend knowledge to defend against jailbreaks. Unlike traditional methods that rely on static datasets, ICAG employs an iterative process to enhance both the defense and attack agents. This continuous improvement process strengthens defenses against newly generated jailbreak prompts. Our empirical studies affirm ICAG's efficacy, where LLMs safeguarded by ICAG exhibit significantly reduced jailbreak success rates across various attack scenarios. Moreover, ICAG demonstrates remarkable transferability to other LLMs, indicating its potential as a versatile defense mechanism.
Backdoor Federated Learning by Poisoning Backdoor-Critical Layers
Aug 08, 2023
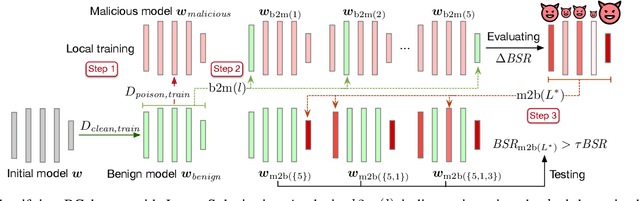
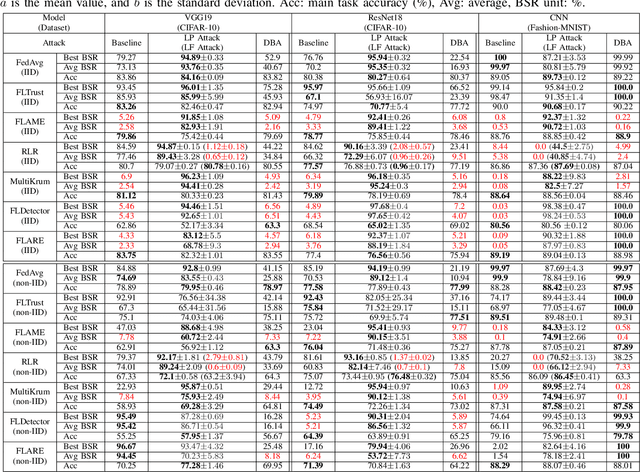
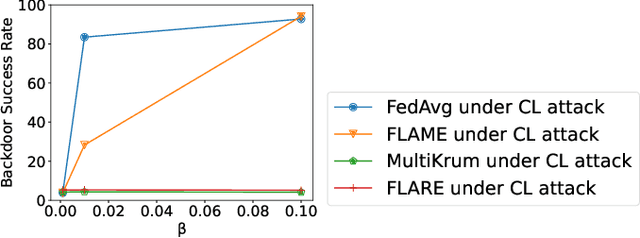
Federated learning (FL) has been widely deployed to enable machine learning training on sensitive data across distributed devices. However, the decentralized learning paradigm and heterogeneity of FL further extend the attack surface for backdoor attacks. Existing FL attack and defense methodologies typically focus on the whole model. None of them recognizes the existence of backdoor-critical (BC) layers-a small subset of layers that dominate the model vulnerabilities. Attacking the BC layers achieves equivalent effects as attacking the whole model but at a far smaller chance of being detected by state-of-the-art (SOTA) defenses. This paper proposes a general in-situ approach that identifies and verifies BC layers from the perspective of attackers. Based on the identified BC layers, we carefully craft a new backdoor attack methodology that adaptively seeks a fundamental balance between attacking effects and stealthiness under various defense strategies. Extensive experiments show that our BC layer-aware backdoor attacks can successfully backdoor FL under seven SOTA defenses with only 10% malicious clients and outperform the latest backdoor attack methods.
A Comparison of Image Denoising Methods
Apr 18, 2023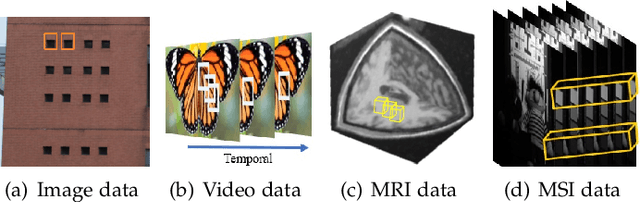
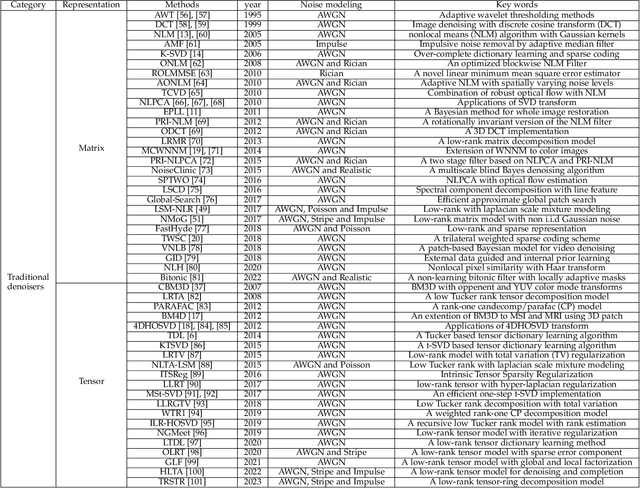
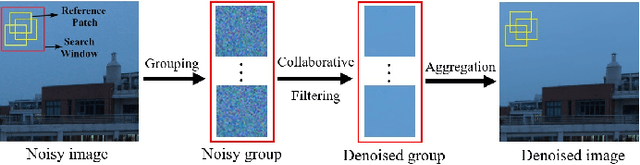
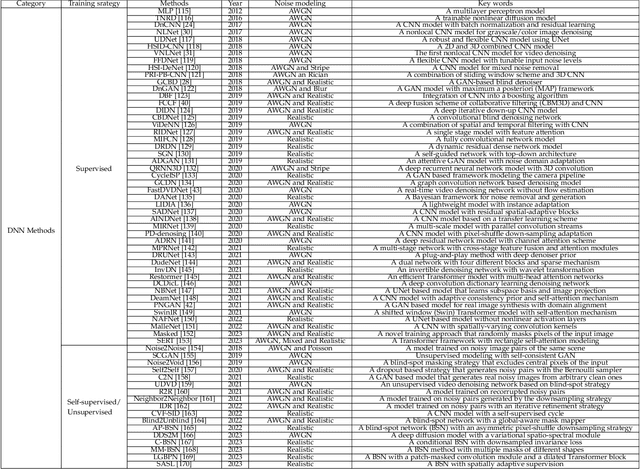
The advancement of imaging devices and countless images generated everyday pose an increasingly high demand on image denoising, which still remains a challenging task in terms of both effectiveness and efficiency. To improve denoising quality, numerous denoising techniques and approaches have been proposed in the past decades, including different transforms, regularization terms, algebraic representations and especially advanced deep neural network (DNN) architectures. Despite their sophistication, many methods may fail to achieve desirable results for simultaneous noise removal and fine detail preservation. In this paper, to investigate the applicability of existing denoising techniques, we compare a variety of denoising methods on both synthetic and real-world datasets for different applications. We also introduce a new dataset for benchmarking, and the evaluations are performed from four different perspectives including quantitative metrics, visual effects, human ratings and computational cost. Our experiments demonstrate: (i) the effectiveness and efficiency of representative traditional denoisers for various denoising tasks, (ii) a simple matrix-based algorithm may be able to produce similar results compared with its tensor counterparts, and (iii) the notable achievements of DNN models, which exhibit impressive generalization ability and show state-of-the-art performance on various datasets. In spite of the progress in recent years, we discuss shortcomings and possible extensions of existing techniques. Datasets, code and results are made publicly available and will be continuously updated at https://github.com/ZhaomingKong/Denoising-Comparison.
A Pilot Study of Query-Free Adversarial Attack against Stable Diffusion
Apr 03, 2023



Despite the record-breaking performance in Text-to-Image (T2I) generation by Stable Diffusion, less research attention is paid to its adversarial robustness. In this work, we study the problem of adversarial attack generation for Stable Diffusion and ask if an adversarial text prompt can be obtained even in the absence of end-to-end model queries. We call the resulting problem 'query-free attack generation'. To resolve this problem, we show that the vulnerability of T2I models is rooted in the lack of robustness of text encoders, e.g., the CLIP text encoder used for attacking Stable Diffusion. Based on such insight, we propose both untargeted and targeted query-free attacks, where the former is built on the most influential dimensions in the text embedding space, which we call steerable key dimensions. By leveraging the proposed attacks, we empirically show that only a five-character perturbation to the text prompt is able to cause the significant content shift of synthesized images using Stable Diffusion. Moreover, we show that the proposed target attack can precisely steer the diffusion model to scrub the targeted image content without causing much change in untargeted image content. Our code is available at https://github.com/OPTML-Group/QF-Attack.