 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Open-Weight LLMs Ready for Social Media Moderation? A Comparative Study on Bluesky
Feb 05, 2026As internet access expands, so does exposure to harmful content, increasing the need for effective moderation. Research has demonstrated that large language models (LLMs) can be effectively utilized for social media moderation tasks, including harmful content detection. While proprietary LLMs have been shown to zero-shot outperform traditional machine learning models, the out-of-the-box capability of open-weight LLMs remains an open question. Motivated by recent developments of reasoning LLMs, we evaluate seven state-of-the-art models: four proprietary and three open-weight. Testing with real-world posts on Bluesky, moderation decisions by Bluesky Moderation Service, and annotations by two authors, we find a considerable degree of overlap between the sensitivity (81%--97%) and specificity (91%--100%) of the open-weight LLMs and those (72%--98%, and 93%--99%) of the proprietary ones. Additionally, our analysis reveals that specificity exceeds sensitivity for rudeness detection, but the opposite holds for intolerance and threats. Lastly, we identify inter-rater agreement across human moderators and the LLMs, highlighting considerations for deploying LLMs in both platform-scale and personalized moderation contexts. These findings show open-weight LLMs can support privacy-preserving moderation on consumer-grade hardware and suggest new directions for designing moderation systems that balance community values with individual user preferences.
Image Denoising Using Global and Local Circulant Representation
Dec 29, 2025The proliferation of imaging devices and countless image data generated every day impose an increasingly high demand on efficient and effective image denoising. In this paper, we establish a theoretical connection between principal component analysis (PCA) and the Haar transform under circulant representation, and present a computationally simple denoising algorithm. The proposed method, termed Haar-tSVD, exploits a unified tensor singular value decomposition (t-SVD) projection combined with Haar transform to efficiently capture global and local patch correlations. Haar-tSVD operates as a one-step, parallelizable plug-and-play denoiser that eliminates the need for learning local bases, thereby striking a balance between denoising speed and performance. Besides, an adaptive noise estimation scheme is introduced to improve robustness according to eigenvalue analysis of the circulant structure. To further enhance the performance under severe noise conditions, we integrate deep neural networks with Haar-tSVD based on the established Haar-PCA relationship. Experimental results on various denoising datasets demonstrate the efficiency and effectiveness of proposed method for noise removal. Our code is publicly available at https://github.com/ZhaomingKong/Haar-tSVD.
Efficient Image Denoising Using Global and Local Circulant Representation
Aug 14, 2025



The advancement of imaging devices and countless image data generated everyday impose an increasingly high demand on efficient and effective image denoising. In this paper, we present a computationally simple denoising algorithm, termed Haar-tSVD, aiming to explore the nonlocal self-similarity prior and leverage the connection between principal component analysis (PCA) and the Haar transform under circulant representation. We show that global and local patch correlations can be effectively captured through a unified tensor-singular value decomposition (t-SVD) projection with the Haar transform. This results in a one-step, highly parallelizable filtering method that eliminates the need for learning local bases to represent image patches, striking a balance between denoising speed and performance. Furthermore, we introduce an adaptive noise estimation scheme based on a CNN estimator and eigenvalue analysis to enhance the robustness and adaptability of the proposed method. Experiments on different real-world denoising tasks validate the efficiency and effectiveness of Haar-tSVD for noise removal and detail preservation. Datasets, code and results are publicly available at https://github.com/ZhaomingKong/Haar-tSVD.
TelApart: Differentiating Network Faults from Customer-Premise Faults in Cable Broadband Networks
Dec 12, 2024Two types of radio frequency (RF) impairments frequently occur in a cable broadband network: impairments that occur inside a cable network and impairments occur at the edge of the broadband network, i.e., in a subscriber's premise. Differentiating these two types of faults is important, as different faults require different types of technical personnel to repair them. Presently, the cable industry lacks publicly available tools to automatically diagnose the type of fault. In this work, we present TelApart, a fault diagnosis system for cable broadband networks. TelApart uses telemetry data collected by the Proactive Network Maintenance (PNM) infrastructure in cable networks to effectively differentiate the type of fault. Integral to TelApart's design is an unsupervised machine learning model that groups cable devices sharing similar anomalous patterns together. We use metrics derived from an ISP's customer trouble tickets to programmatically tune the model's hyper-parameters so that an ISP can deploy TelApart in various conditions without hand-tuning its hyper-parameters. We also address the data challenge that the telemetry data collected by the PNM system contain numerous missing, duplicated, and unaligned data points. Using real-world data contributed by a cable ISP, we show that TelApart can effectively identify different types of faults.
Improving the Reliability of Cable Broadband Networks via Proactive Network Maintenance
Dec 12, 2024Cable broadband networks are one of the few "last-mile" broadband technologies widely available in the U.S. Unfortunately, they have poor reliability after decades of deployment. The cable industry proposed a framework called Proactive Network Maintenance (PNM) to diagnose the cable networks. However, there is little public knowledge or systematic study on how to use these data to detect and localize cable network problems. Existing tools in the public domain have prohibitive high false-positive rates. In this paper, we propose CableMon, the first public-domain system that applies machine learning techniques to PNM data to improve the reliability of cable broadband networks. CableMon tackles two key challenges faced by cable ISPs: accurately detecting failures, and distinguishing whether a failure occurs within a network or at a subscriber's premise. CableMon uses statistical models to generate features from time series data and uses customer trouble tickets as hints to infer abnormal/failure thresholds for these generated features. Further, CableMon employs an unsupervised learning model to group cable devices sharing similar anomalous patterns and effectively identify impairments that occur inside a cable network and impairments occur at a subscriber's premise, as these two different faults require different types of technical personnel to repair them. We use eight months of PNM data and customer trouble tickets from an ISP and experimental deployment to evaluate CableMon's performance. Our evaluation results show that CableMon can effectively detect and distinguish failures from PNM data and outperforms existing public-domain tools.
Image Denoising Using Green Channel Prior
Aug 12, 2024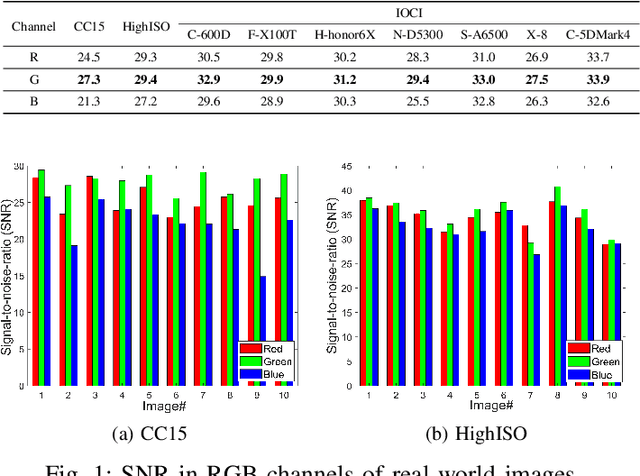



Image denoising is an appealing and challenging task, in that noise statistics of real-world observations may vary with local image contents and different image channels. Specifically, the green channel usually has twice the sampling rate in raw data. To handle noise variances and leverage such channel-wise prior information, we propose a simple and effective green channel prior-based image denoising (GCP-ID) method, which integrates GCP into the classic patch-based denoising framework. Briefly, we exploit the green channel to guide the search for similar patches, which aims to improve the patch grouping quality and encourage sparsity in the transform domain. The grouped image patches are then reformulated into RGGB arrays to explicitly characterize the density of green samples. Furthermore, to enhance the adaptivity of GCP-ID to various image contents, we cast the noise estimation problem into a classification task and train an effective estimator based on convolutional neural networks (CNNs). Experiments on real-world datasets demonstrate the competitive performance of the proposed GCP-ID method for image and video denoising applications in both raw and sRGB spaces. Our code is available at https://github.com/ZhaomingKong/GCP-ID.
Destination-Constrained Linear Dynamical System Modeling in Set-Valued Frameworks
Mar 26, 2024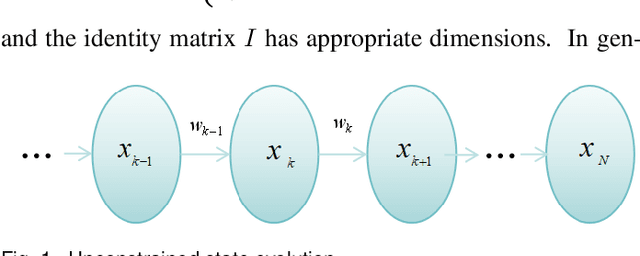
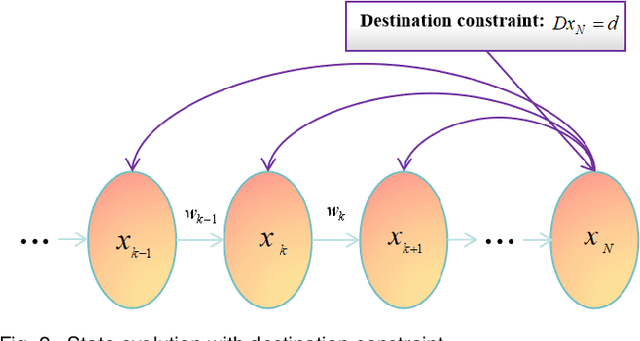
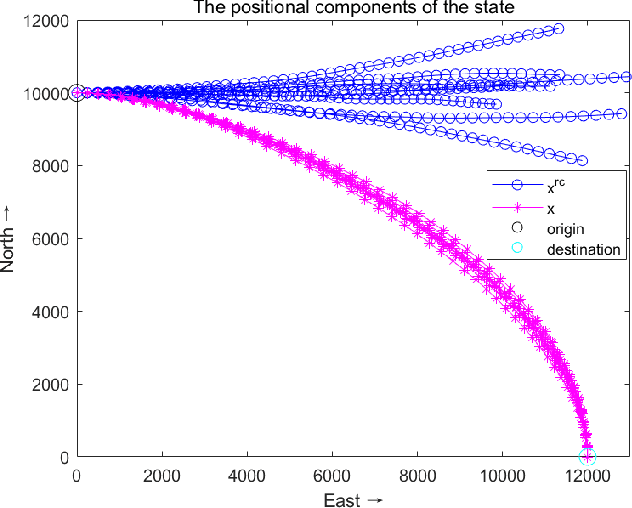
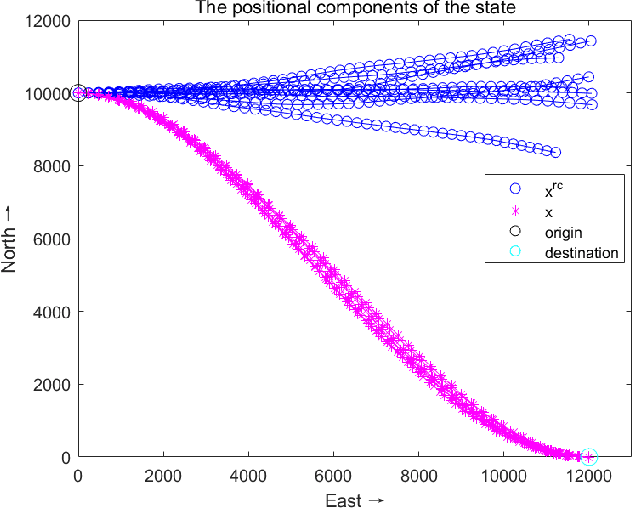
Directional motion towards a specified destination is a common occurrence in physical processes and human societal activities. Utilizing this prior information can significantly improve the control and predictive performance of system models. This paper primarily focuses on reconstructing linear dynamic system models based on destination constraints in the set-valued framework. We treat destination constraints as inherent information in the state evolution process and employ convex optimization techniques to construct a coherent and robust state model. This refined model effectively captures the impact of destination constraints on the state evolution at each time step. Furthermore, we design an optimal weight matrix for the reconstructed model to ensure smoother and more natural trajectories of state evolution. We also analyze the theoretical guarantee of optimality for this weight matrix and the properties of the reconstructed model. Finally, simulation experiments verify that the reconstructed model has significant advantages over the unconstrained and unoptimized weighted models and constrains the evolution of state trajectories with different starting and ending points.
Color Image Denoising Using The Green Channel Prior
Feb 13, 2024Noise removal in the standard RGB (sRGB) space remains a challenging task, in that the noise statistics of real-world images can be different in R, G and B channels. In fact, the green channel usually has twice the sampling rate in raw data and a higher signal-to-noise ratio than red/blue ones. However, the green channel prior (GCP) is often understated or ignored in color image denoising since many existing approaches mainly focus on modeling the relationship among image patches. In this paper, we propose a simple and effective one step GCP-based image denoising (GCP-ID) method, which aims to exploit the GCP for denoising in the sRGB space by integrating it into the classic nonlocal transform domain denoising framework. Briefly, we first take advantage of the green channel to guide the search of similar patches, which improves the patch search quality and encourages sparsity in the transform domain. Then we reformulate RGB patches into RGGB arrays to explicitly characterize the density of green samples. The block circulant representation is utilized to capture the cross-channel correlation and the channel redundancy. Experiments on both synthetic and real-world datasets demonstrate the competitive performance of the proposed GCP-ID method for the color image and video denoising tasks. The code is available at github.com/ZhaomingKong/GCP-ID.
A Comparison of Image Denoising Methods
Apr 18, 2023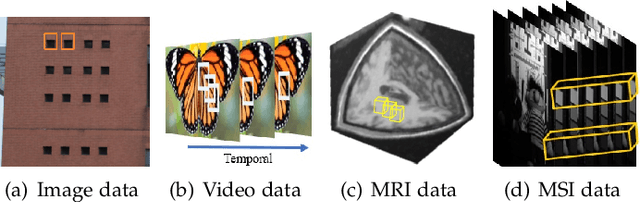
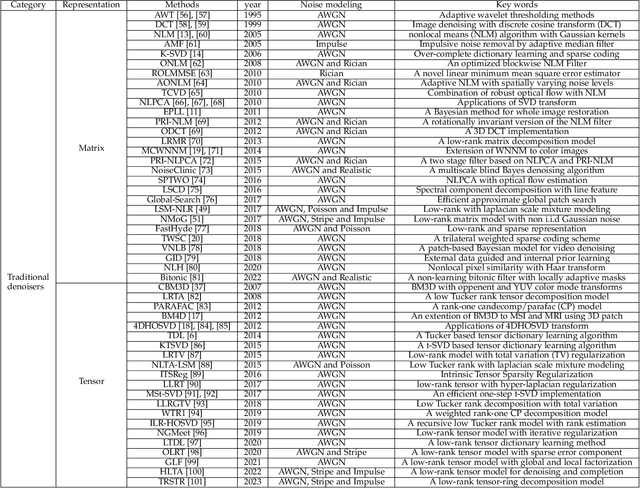
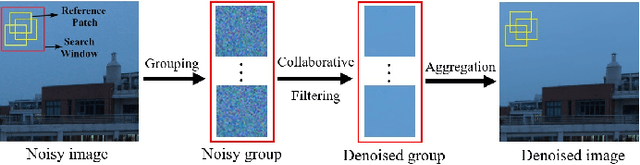
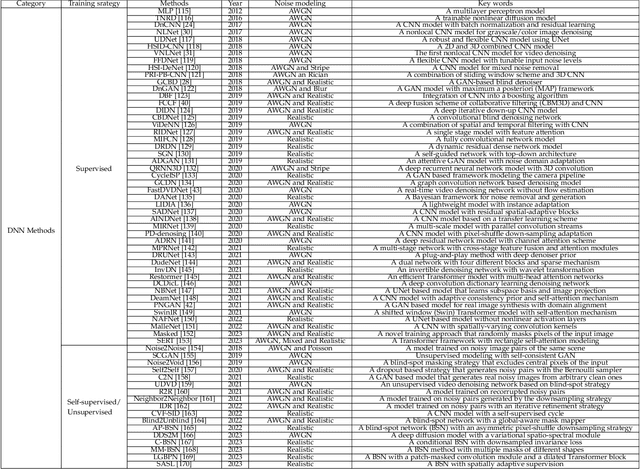
The advancement of imaging devices and countless images generated everyday pose an increasingly high demand on image denoising, which still remains a challenging task in terms of both effectiveness and efficiency. To improve denoising quality, numerous denoising techniques and approaches have been proposed in the past decades, including different transforms, regularization terms, algebraic representations and especially advanced deep neural network (DNN) architectures. Despite their sophistication, many methods may fail to achieve desirable results for simultaneous noise removal and fine detail preservation. In this paper, to investigate the applicability of existing denoising techniques, we compare a variety of denoising methods on both synthetic and real-world datasets for different applications. We also introduce a new dataset for benchmarking, and the evaluations are performed from four different perspectives including quantitative metrics, visual effects, human ratings and computational cost. Our experiments demonstrate: (i) the effectiveness and efficiency of representative traditional denoisers for various denoising tasks, (ii) a simple matrix-based algorithm may be able to produce similar results compared with its tensor counterparts, and (iii) the notable achievements of DNN models, which exhibit impressive generalization ability and show state-of-the-art performance on various datasets. In spite of the progress in recent years, we discuss shortcomings and possible extensions of existing techniques. Datasets, code and results are made publicly available and will be continuously updated at https://github.com/ZhaomingKong/Denoising-Comparison.
A Comprehensive Comparison of Multi-Dimensional Image Denoising Methods
Nov 06, 2020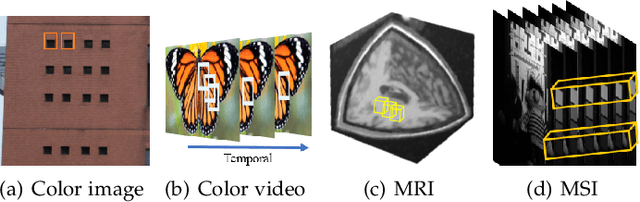
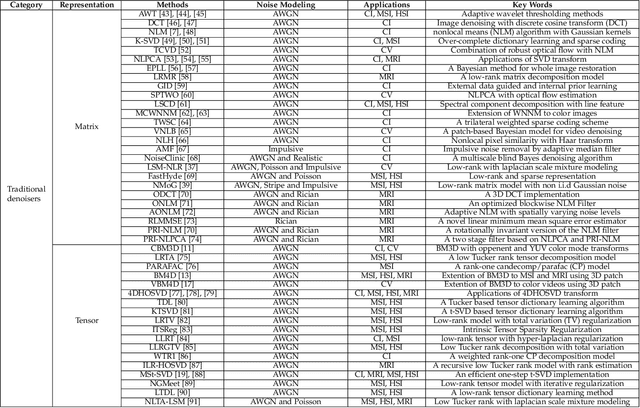
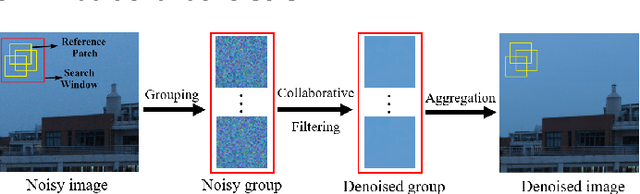
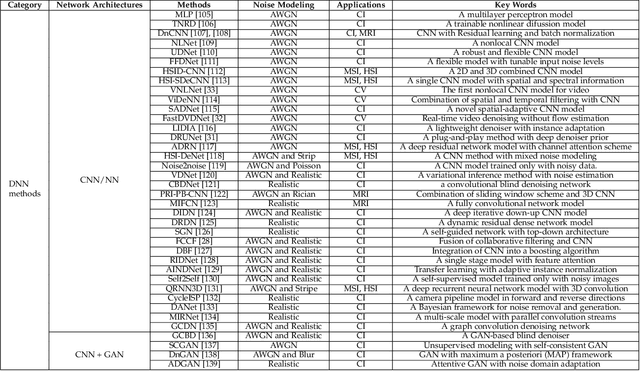
Filtering multi-dimensional images such as color images, color videos, multispectral images and magnetic resonance images is challenging in terms of both effectiveness and efficiency. Leveraging the nonlocal self-similarity (NLSS) characteristic of images and sparse representation in the transform domain, the block-matching and 3D filtering (BM3D) based methods show powerful denoising performance. Recently, numerous new approaches with different regularization terms, transforms and advanced deep neural network (DNN) architectures are proposed to improve denoising quality. In this paper, we extensively compare over 60 methods on both synthetic and real-world datasets. We also introduce a new color image and video dataset for benchmarking, and our evaluations are performed from four different perspectives including quantitative metrics, visual effects, human ratings and computational cost. Comprehensive experiments demonstrate: (i) the effectiveness and efficiency of the BM3D family for various denoising tasks, (ii) a simple matrix-based algorithm could produce similar results compared with its tensor counterparts, and (iii) several DNN models trained with synthetic Gaussian noise show state-of-the-art performance on real-world color image and video datasets. Despite the progress in recent years, we discuss shortcomings and possible extensions of existing techniques. Datasets and codes for evaluation are made publicly available at https://github.com/ZhaomingKong/Denoising-Comparison.