 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Graph Pattern Machine
Jan 30, 2026Temporal graph learning is pivotal for deciphering dynamic systems, where the core challenge lies in explicitly modeling the underlying evolving patterns that govern network transformation. However, prevailing methods are predominantly task-centric and rely on restrictive assumptions -- such as short-term dependency modeling, static neighborhood semantics, and retrospective time usage. These constraints hinder the discovery of transferable temporal evolution mechanisms. To address this, we propose the Temporal Graph Pattern Machine (TGPM), a foundation framework that shifts the focus toward directly learning generalized evolving patterns. TGPM conceptualizes each interaction as an interaction patch synthesized via temporally-biased random walks, thereby capturing multi-scale structural semantics and long-range dependencies that extend beyond immediate neighborhoods. These patches are processed by a Transformer-based backbone designed to capture global temporal regularities while adapting to context-specific interaction dynamics. To further empower the model, we introduce a suite of self-supervised pre-training tasks -- specifically masked token modeling and next-time prediction -- to explicitly encode the fundamental laws of network evolution. Extensive experiments show that TGPM consistently achieves state-of-the-art performance in both transductive and inductive link prediction, demonstrating exceptional cross-domain transferability.
Molecular Representations in Implicit Functional Space via Hyper-Networks
Jan 29, 2026Molecular representations fundamentally shape how machine learning systems reason about molecular structure and physical properties. Most existing approaches adopt a discrete pipeline: molecules are encoded as sequences, graphs, or point clouds, mapped to fixed-dimensional embeddings, and then used for task-specific prediction. This paradigm treats molecules as discrete objects, despite their intrinsically continuous and field-like physical nature. We argue that molecular learning can instead be formulated as learning in function space. Specifically, we model each molecule as a continuous function over three-dimensional (3D) space and treat this molecular field as the primary object of representation. From this perspective, conventional molecular representations arise as particular sampling schemes of an underlying continuous object. We instantiate this formulation with MolField, a hyper-network-based framework that learns distributions over molecular fields. To ensure physical consistency, these functions are defined over canonicalized coordinates, yielding invariance to global SE(3) transformations. To enable learning directly over functions, we introduce a structured weight tokenization and train a sequence-based hyper-network to model a shared prior over molecular fields. We evaluate MolField on molecular dynamics and property prediction. Our results show that treating molecules as continuous functions fundamentally changes how molecular representations generalize across tasks and yields downstream behavior that is stable to how molecules are discretized or queried.
Why Reasoning Fails to Plan: A Planning-Centric Analysis of Long-Horizon Decision Making in LLM Agents
Jan 29, 2026Large language model (LLM)-based agents exhibit strong step-by-step reasoning capabilities over short horizons, yet often fail to sustain coherent behavior over long planning horizons. We argue that this failure reflects a fundamental mismatch: step-wise reasoning induces a form of step-wise greedy policy that is adequate for short horizons but fails in long-horizon planning, where early actions must account for delayed consequences. From this planning-centric perspective, we study LLM-based agents in deterministic, fully structured environments with explicit state transitions and evaluation signals. Our analysis reveals a core failure mode of reasoning-based policies: locally optimal choices induced by step-wise scoring lead to early myopic commitments that are systematically amplified over time and difficult to recover from. We introduce FLARE (Future-aware Lookahead with Reward Estimation) as a minimal instantiation of future-aware planning to enforce explicit lookahead, value propagation, and limited commitment in a single model, allowing downstream outcomes to influence early decisions. Across multiple benchmarks, agent frameworks, and LLM backbones, FLARE consistently improves task performance and planning-level behavior, frequently allowing LLaMA-8B with FLARE to outperform GPT-4o with standard step-by-step reasoning. These results establish a clear distinction between reasoning and planning.
IQE-CLIP: Instance-aware Query Embedding for Zero-/Few-shot Anomaly Detection in Medical Domain
Jun 12, 2025Recent advances in vision-language models, such as CLIP, have significantly improved performance in zero- and few-shot anomaly detection (ZFSAD) tasks. However, most existing CLIP-based methods assume prior knowledge of categories and rely on carefully designed prompts tailored to specific scenarios. While these text prompts capture semantic information in the textual space, they often fail to distinguish normal and anomalous instances in the joint embedding space. Moreover, most ZFSAD approaches focus on industrial domains, with limited exploration in medical tasks. To address these limitations, we propose IQE-CLIP, a novel framework for ZFSAD in the medical domain. We show that query embeddings integrating both textual and instance-aware visual information serve as more effective indicators of anomalies. Specifically, we introduce class-based and learnable prompting tokens to better adapt CLIP to the medical setting. Furthermore, we design an instance-aware query module that extracts region-level contextual information from both modalities, enabling the generation of anomaly-sensitive embeddings. Extensive experiments on six medical datasets demonstrate that IQE-CLIP achieves state-of-the-art performance in both zero-shot and few-shot settings. Code and data are available at \href{https://github.com/hongh0/IQE-CLIP/}{this https URL}.
EfficientLLM: Efficiency in Large Language Models
May 20, 2025Large Language Models (LLMs) have driven significant progress, yet their growing parameter counts and context windows incur prohibitive compute, energy, and monetary costs. We introduce EfficientLLM, a novel benchmark and the first comprehensive empirical study evaluating efficiency techniques for LLMs at scale. Conducted on a production-class cluster (48xGH200, 8xH200 GPUs), our study systematically explores three key axes: (1) architecture pretraining (efficient attention variants: MQA, GQA, MLA, NSA; sparse Mixture-of-Experts (MoE)), (2) fine-tuning (parameter-efficient methods: LoRA, RSLoRA, DoRA), and (3) inference (quantization methods: int4, float16). We define six fine-grained metrics (Memory Utilization, Compute Utilization, Latency, Throughput, Energy Consumption, Compression Rate) to capture hardware saturation, latency-throughput balance, and carbon cost. Evaluating over 100 model-technique pairs (0.5B-72B parameters), we derive three core insights: (i) Efficiency involves quantifiable trade-offs: no single method is universally optimal; e.g., MoE reduces FLOPs and improves accuracy but increases VRAM by 40%, while int4 quantization cuts memory/energy by up to 3.9x at a 3-5% accuracy drop. (ii) Optima are task- and scale-dependent: MQA offers optimal memory-latency trade-offs for constrained devices, MLA achieves lowest perplexity for quality-critical tasks, and RSLoRA surpasses LoRA efficiency only beyond 14B parameters. (iii) Techniques generalize across modalities: we extend evaluations to Large Vision Models (Stable Diffusion 3.5, Wan 2.1) and Vision-Language Models (Qwen2.5-VL), confirming effective transferability. By open-sourcing datasets, evaluation pipelines, and leaderboards, EfficientLLM provides essential guidance for researchers and engineers navigating the efficiency-performance landscape of next-generation foundation models.
Social Science Meets LLMs: How Reliable Are Large Language Models in Social Simulations?
Oct 30, 2024


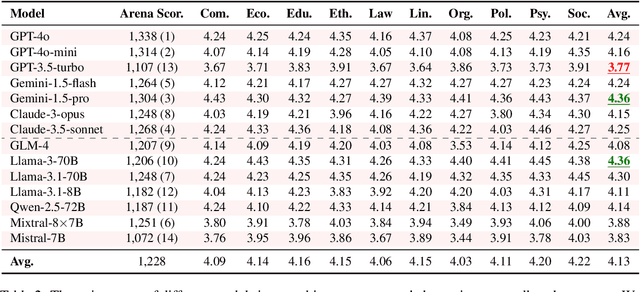
Large Language Models (LLMs) are increasingly employed for simulations, enabling applications in role-playing agents and Computational Social Science (CSS). However, the reliability of these simulations is under-explored, which raises concerns about the trustworthiness of LLMs in these applications. In this paper, we aim to answer ``How reliable is LLM-based simulation?'' To address this, we introduce TrustSim, an evaluation dataset covering 10 CSS-related topics, to systematically investigate the reliability of the LLM simulation. We conducted experiments on 14 LLMs and found that inconsistencies persist in the LLM-based simulated roles. In addition, the consistency level of LLMs does not strongly correlate with their general performance. To enhance the reliability of LLMs in simulation, we proposed Adaptive Learning Rate Based ORPO (AdaORPO), a reinforcement learning-based algorithm to improve the reliability in simulation across 7 LLMs. Our research provides a foundation for future studies to explore more robust and trustworthy LLM-based simulations.
TTT-Unet: Enhancing U-Net with Test-Time Training Layers for Biomedical Image Segmentation
Sep 18, 2024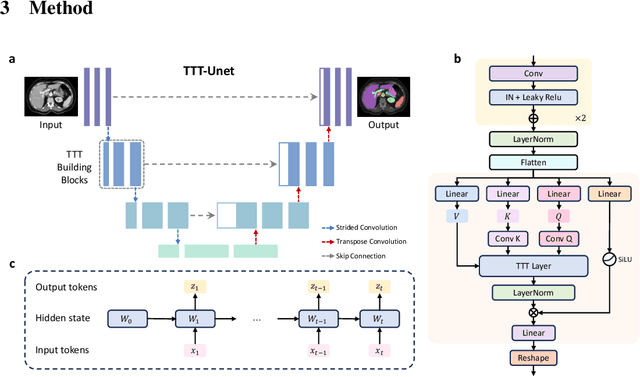

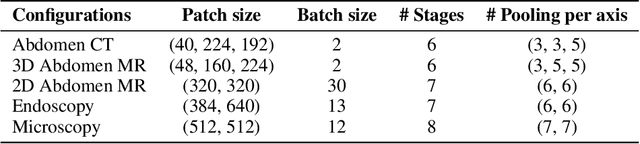
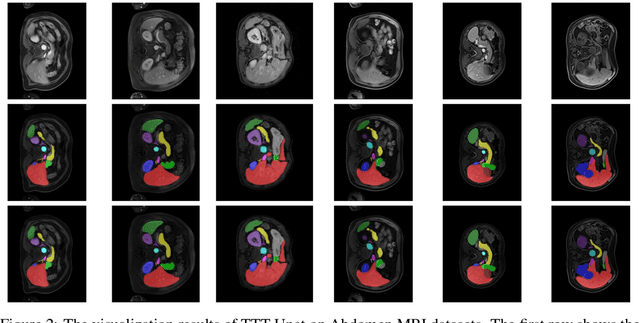
Biomedical image segmentation is crucial for accurately diagnosing and analyzing various diseases. However, Convolutional Neural Networks (CNNs) and Transformers, the most commonly used architectures for this task, struggle to effectively capture long-range dependencies due to the inherent locality of CNNs and the computational complexity of Transformers. To address this limitation, we introduce TTT-Unet, a novel framework that integrates Test-Time Training (TTT) layers into the traditional U-Net architecture for biomedical image segmentation. TTT-Unet dynamically adjusts model parameters during the testing time, enhancing the model's ability to capture both local and long-range features. We evaluate TTT-Unet on multiple medical imaging datasets, including 3D abdominal organ segmentation in CT and MR images, instrument segmentation in endoscopy images, and cell segmentation in microscopy images. The results demonstrate that TTT-Unet consistently outperforms state-of-the-art CNN-based and Transformer-based segmentation models across all tasks. The code is available at https://github.com/rongzhou7/TTT-Unet.
AdvLogo: Adversarial Patch Attack against Object Detectors based on Diffusion Models
Sep 11, 2024



With the rapid development of deep learning, object detectors have demonstrated impressive performance; however, vulnerabilities still exist in certain scenarios. Current research exploring the vulnerabilities using adversarial patches often struggles to balance the trade-off between attack effectiveness and visual quality. To address this problem, we propose a novel framework of patch attack from semantic perspective, which we refer to as AdvLogo. Based on the hypothesis that every semantic space contains an adversarial subspace where images can cause detectors to fail in recognizing objects, we leverage the semantic understanding of the diffusion denoising process and drive the process to adversarial subareas by perturbing the latent and unconditional embeddings at the last timestep. To mitigate the distribution shift that exposes a negative impact on image quality, we apply perturbation to the latent in frequency domain with the Fourier Transform. Experimental results demonstrate that AdvLogo achieves strong attack performance while maintaining high visual quality.
Biomedical SAM 2: Segment Anything in Biomedical Images and Videos
Aug 06, 2024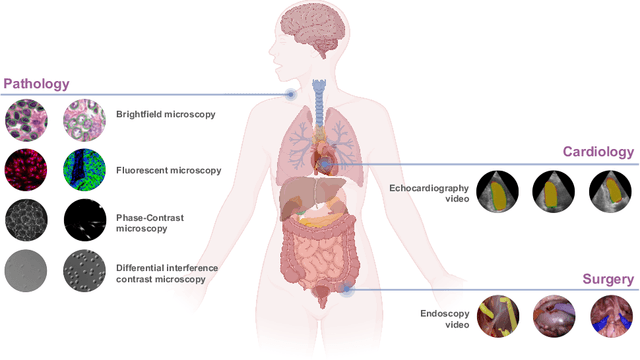
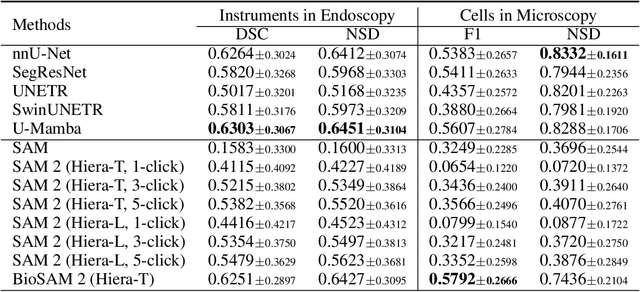
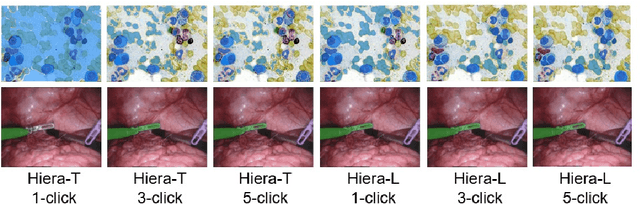

Medical image segmentation and video object segmentation are essential for diagnosing and analyzing diseases by identifying and measuring biological structures. Recent advances in natural domain have been driven by foundation models like the Segment Anything Model 2 (SAM 2). To explore the performance of SAM 2 in biomedical applications, we designed two evaluation pipelines for single-frame image segmentation and multi-frame video segmentation with varied prompt designs, revealing SAM 2's limitations in medical contexts. Consequently, we developed BioSAM 2, an enhanced foundation model optimized for biomedical data based on SAM 2. Our experiments show that BioSAM 2 not only surpasses the performance of existing state-of-the-art foundation models but also matches or even exceeds specialist models, demonstrating its efficacy and potential in the medical domain.
Bora: Biomedical Generalist Video Generation Model
Jul 12, 2024



Generative models hold promise for revolutionizing medical education, robot-assisted surgery, and data augmentation for medical AI development. Diffusion models can now generate realistic images from text prompts, while recent advancements have demonstrated their ability to create diverse, high-quality videos. However, these models often struggle with generating accurate representations of medical procedures and detailed anatomical structures. This paper introduces Bora, the first spatio-temporal diffusion probabilistic model designed for text-guided biomedical video generation. Bora leverages Transformer architecture and is pre-trained on general-purpose video generation tasks. It is fine-tuned through model alignment and instruction tuning using a newly established medical video corpus, which includes paired text-video data from various biomedical fields. To the best of our knowledge, this is the first attempt to establish such a comprehensive annotated biomedical video dataset. Bora is capable of generating high-quality video data across four distinct biomedical domains, adhering to medical expert standards and demonstrating consistency and diversity. This generalist video generative model holds significant potential for enhancing medical consultation and decision-making, particularly in resource-limited settings. Additionally, Bora could pave the way for immersive medical training and procedure planning. Extensive experiments on distinct medical modalities such as endoscopy, ultrasound, MRI, and cell tracking validate the effectiveness of our model in understanding biomedical instructions and its superior performance across subjects compared to state-of-the-art generation models.