 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4Brain: Training a Large Language Model for Brain Video Understanding
Sep 26, 2024



Decoding visual-semantic information from brain signals, such as functional MRI (fMRI), across different subjects poses significant challenges, including low signal-to-noise ratio, limited data availability, and cross-subject variability. Recent advancements in large language models (LLMs) show remarkable effectiveness in processing multimodal information. In this study, we introduce an LLM-based approach for reconstructing visual-semantic information from fMRI signals elicited by video stimuli. Specifically, we employ fine-tuning techniques on an fMRI encoder equipped with adaptors to transform brain responses into latent representations aligned with the video stimuli. Subsequently, these representations are mapped to textual modality by LLM. In particular, we integrate self-supervised domain adaptation methods to enhance the alignment between visual-semantic information and brain responses. Our proposed method achieves good results using various quantitative semantic metrics, while yielding similarity with ground-truth information.
Bora: Biomedical Generalist Video Generation Model
Jul 12, 2024



Generative models hold promise for revolutionizing medical education, robot-assisted surgery, and data augmentation for medical AI development. Diffusion models can now generate realistic images from text prompts, while recent advancements have demonstrated their ability to create diverse, high-quality videos. However, these models often struggle with generating accurate representations of medical procedures and detailed anatomical structures. This paper introduces Bora, the first spatio-temporal diffusion probabilistic model designed for text-guided biomedical video generation. Bora leverages Transformer architecture and is pre-trained on general-purpose video generation tasks. It is fine-tuned through model alignment and instruction tuning using a newly established medical video corpus, which includes paired text-video data from various biomedical fields. To the best of our knowledge, this is the first attempt to establish such a comprehensive annotated biomedical video dataset. Bora is capable of generating high-quality video data across four distinct biomedical domains, adhering to medical expert standards and demonstrating consistency and diversity. This generalist video generative model holds significant potential for enhancing medical consultation and decision-making, particularly in resource-limited settings. Additionally, Bora could pave the way for immersive medical training and procedure planning. Extensive experiments on distinct medical modalities such as endoscopy, ultrasound, MRI, and cell tracking validate the effectiveness of our model in understanding biomedical instructions and its superior performance across subjects compared to state-of-the-art generation models.
ScatterFormer: Locally-Invariant Scattering Transformer for Patient-Independent Multispectral Detection of Epileptiform Discharges
Apr 26, 2023



Patient-independent detection of epileptic activities based on visual spectral representation of continuous EEG (cEEG) has been widely used for diagnosing epilepsy. However, precise detection remains a considerable challenge due to subtle variabilities across subjects, channels and time points. Thus, capturing fine-grained, discriminative features of EEG patterns, which is associated with high-frequency textural information, is yet to be resolved. In this work, we propose Scattering Transformer (ScatterFormer), an invariant scattering transform-based hierarchical Transformer that specifically pays attention to subtle features. In particular, the disentangled frequency-aware attention (FAA) enables the Transformer to capture clinically informative high-frequency components, offering a novel clinical explainability based on visual encoding of multichannel EEG signals. Evaluations on two distinct tasks of epileptiform detection demonstrate the effectiveness our method. Our proposed model achieves median AUCROC and accuracy of 98.14%, 96.39% in patients with Rolandic epilepsy. On a neonatal seizure detection benchmark, it outperforms the state-of-the-art by 9% in terms of average AUCROC.
* 11 pages
TBI-GAN: An Adversarial Learning Approach for Data Synthesis on Traumatic Brain Segmentation
Aug 12, 2022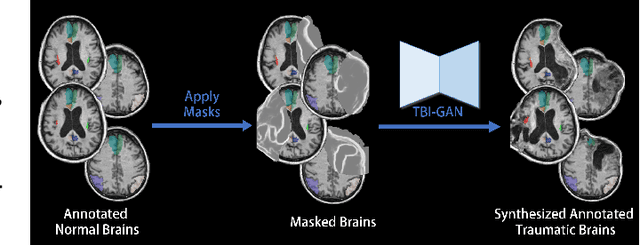
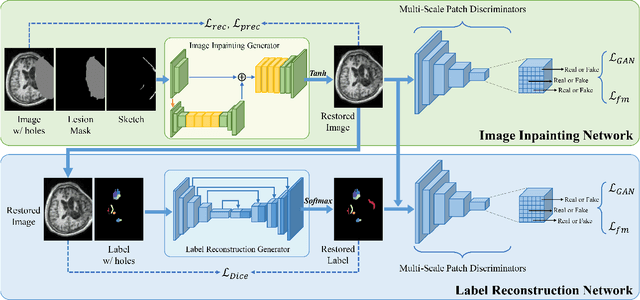
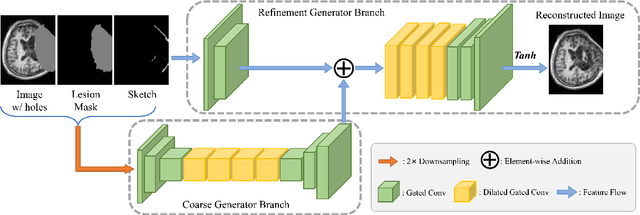
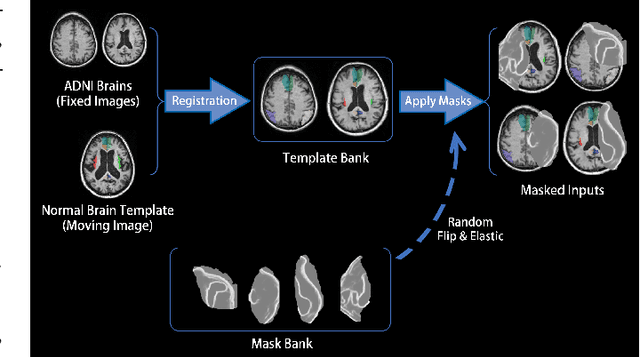
Brain network analysis for traumatic brain injury (TBI) patients is critical for its consciousness level assessment and prognosis evaluation, which requires the segmentation of certain consciousness-related brain regions. However, it is difficult to construct a TBI segmentation model as manually annotated MR scans of TBI patients are hard to collect. Data augmentation techniques can be applied to alleviate the issue of data scarcity. However, conventional data augmentation strategies such as spatial and intensity transformation are unable to mimic the deformation and lesions in traumatic brains, which limits the performance of the subsequent segmentation task. To address these issues, we propose a novel medical image inpainting model named TBI-GAN to synthesize TBI MR scans with paired brain label maps. The main strength of our TBI-GAN method is that it can generate TBI images and corresponding label maps simultaneously, which has not been achieved in the previous inpainting methods for medical images. We first generate the inpainted image under the guidance of edge information following a coarse-to-fine manner, and then the synthesized intensity image is used as the prior for label inpainting. Furthermore, we introduce a registration-based template augmentation pipeline to increase the diversity of the synthesized image pairs and enhance the capacity of data augmentation. Experimental results show that the proposed TBI-GAN method can produce sufficient synthesized TBI images with high quality and valid label maps, which can greatly improve the 2D and 3D traumatic brain segmentation performance compared with the alternatives.