 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Visual Search by Eye Movement and Low-Latency Spiking Neural Network
Oct 10, 2023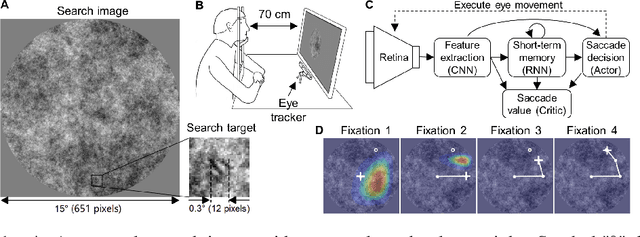
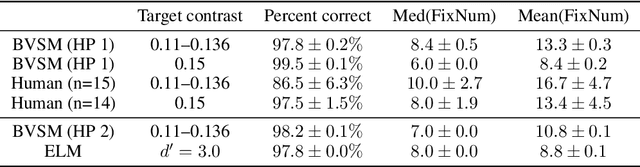
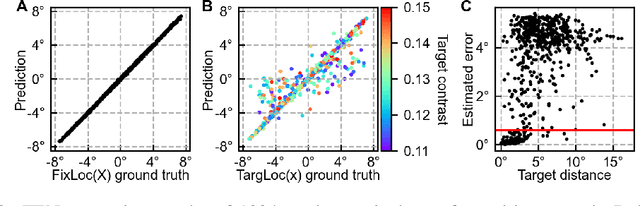
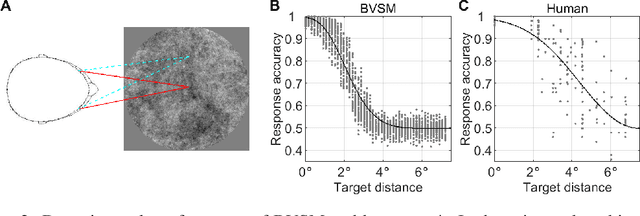
Human vision incorporates non-uniform resolution retina, efficient eye movement strategy, and spiking neural network (SNN) to balance the requirements in visual field size, visual resolution, energy cost, and inference latency. These properties have inspired interest in developing human-like computer vision. However, existing models haven't fully incorporated the three features of human vision, and their learned eye movement strategies haven't been compared with human's strategy, making the models' behavior difficult to interpret. Here, we carry out experiments to examine human visual search behaviors and establish the first SNN-based visual search model. The model combines an artificial retina with spiking feature extraction, memory, and saccade decision modules, and it employs population coding for fast and efficient saccade decisions. The model can learn either a human-like or a near-optimal fixation strategy, outperform humans in search speed and accuracy, and achieve high energy efficiency through short saccade decision latency and sparse activation. It also suggests that the human search strategy is suboptimal in terms of search speed. Our work connects modeling of vision in neuroscience and machine learning and sheds light on developing more energy-efficient computer vision algorithms.
ScatterFormer: Locally-Invariant Scattering Transformer for Patient-Independent Multispectral Detection of Epileptiform Discharges
Apr 26, 2023



Patient-independent detection of epileptic activities based on visual spectral representation of continuous EEG (cEEG) has been widely used for diagnosing epilepsy. However, precise detection remains a considerable challenge due to subtle variabilities across subjects, channels and time points. Thus, capturing fine-grained, discriminative features of EEG patterns, which is associated with high-frequency textural information, is yet to be resolved. In this work, we propose Scattering Transformer (ScatterFormer), an invariant scattering transform-based hierarchical Transformer that specifically pays attention to subtle features. In particular, the disentangled frequency-aware attention (FAA) enables the Transformer to capture clinically informative high-frequency components, offering a novel clinical explainability based on visual encoding of multichannel EEG signals. Evaluations on two distinct tasks of epileptiform detection demonstrate the effectiveness our method. Our proposed model achieves median AUCROC and accuracy of 98.14%, 96.39% in patients with Rolandic epilepsy. On a neonatal seizure detection benchmark, it outperforms the state-of-the-art by 9% in terms of average AUCROC.
* 11 pages