 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending Jailbreak Prompts via In-Context Adversarial Game
Paper and Code

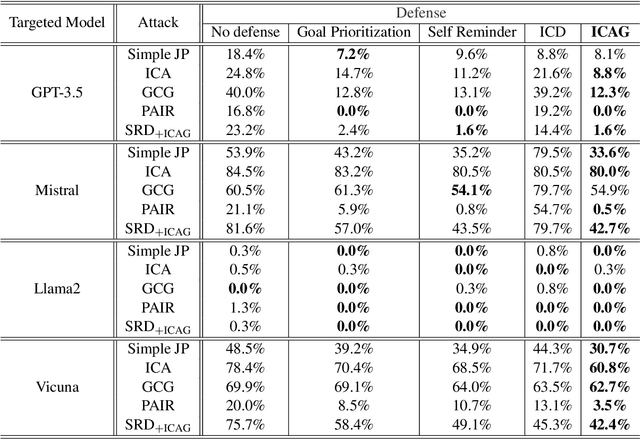

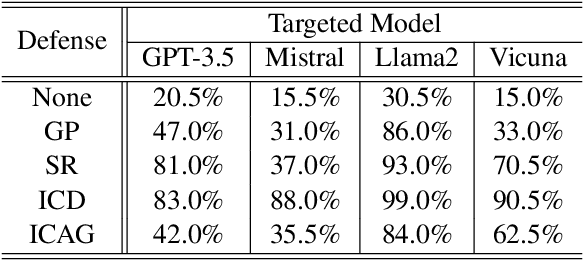
Large Language Models (LLMs) demonstrate remarkable capabilities across diverse applications. However, concerns regarding their security, particularly the vulnerability to jailbreak attacks, persist. Drawing inspiration from adversarial training in deep learning and LLM agent learning processes, we introduce the In-Context Adversarial Game (ICAG) for defending against jailbreaks without the need for fine-tuning. ICAG leverages agent learning to conduct an adversarial game, aiming to dynamically extend knowledge to defend against jailbreaks. Unlike traditional methods that rely on static datasets, ICAG employs an iterative process to enhance both the defense and attack agents. This continuous improvement process strengthens defenses against newly generated jailbreak prompts. Our empirical studies affirm ICAG's efficacy, where LLMs safeguarded by ICAG exhibit significantly reduced jailbreak success rates across various attack scenarios. Moreover, ICAG demonstrates remarkable transferability to other LLMs, indicating its potential as a versatile defense mechanism.