 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoLLMResearch: Training Research Agents for Automating LLM Experiment Configuration -- Learning from Cheap, Optimizing Expensive
May 12, 2026Effectively configuring scalable large language model (LLM) experiments, spanning architecture design, hyperparameter tuning, and beyond, is crucial for advancing LLM research, as poor configuration choices can waste substantial computational resources and prevent models from realizing their full potential. Prior automated methods are designed for low-cost settings where repeated trial and error is feasible, but scalable LLM experiments are too expensive for such extensive iteration. To our knowledge, no work has addressed the automation of high-cost LLM experiment configurations, leaving this problem labor-intensive and dependent on expert intuition. Motivated by this gap, we propose AutoLLMResearch, an agentic framework that mimics how human researchers learn generalizable principles from low-fidelity experiments and extrapolate to efficiently identify promising configurations in expensive LLM settings. The core challenge is how to enable an agent to learn, through interaction with a multi-fidelity experimental environment that captures the structure of the LLM configuration landscape. To achieve this, we propose a systematic framework with two key components: 1) LLMConfig-Gym, a multi-fidelity environment encompassing four critical LLM experiment tasks, supported by over one million GPU hours of verifiable experiment outcomes; 2) A structured training pipeline that formulates configuration research as a long-horizon Markov Decision Process and accordingly incentivizes cross-fidelity extrapolation reasoning. Extensive evaluation against diverse strong baselines on held-out experiments demonstrates the effectiveness, generalization, and interpretability of our framework, supporting its potential as a practical and general solution for scalable real-world LLM experiment automation.
Dissecting Logical Reasoning in LLMs: A Fine-Grained Evaluation and Supervision Study
Jun 05, 2025Logical reasoning is a core capability for many applications of large language models (LLMs), yet existing benchmarks often rely solely on final-answer accuracy, failing to capture the quality and structure of the reasoning process. We propose FineLogic, a fine-grained evaluation framework that assesses logical reasoning across three dimensions: overall benchmark accuracy, stepwise soundness, and representation-level alignment. In addition, to better understand how reasoning capabilities emerge, we conduct a comprehensive study on the effects of supervision format during fine-tuning. We construct four supervision styles (one natural language and three symbolic variants) and train LLMs under each. Our findings reveal that natural language supervision yields strong generalization even on out-of-distribution and long-context tasks, while symbolic reasoning styles promote more structurally sound and atomic inference chains. Further, our representation-level probing shows that fine-tuning primarily improves reasoning behaviors through step-by-step generation, rather than enhancing shortcut prediction or internalized correctness. Together, our framework and analysis provide a more rigorous and interpretable lens for evaluating and improving logical reasoning in LLMs.
Knowledge Graph Enhanced Language Agents for Recommendation
Oct 25, 2024



Language agents have recently been used to simulate human behavior and user-item interactions for recommendation systems. However, current language agent simulations do not understand the relationships between users and items, leading to inaccurate user profiles and ineffective recommendations. In this work, we explore the utility of Knowledge Graphs (KGs), which contain extensive and reliable relationships between users and items, for recommendation. Our key insight is that the paths in a KG can capture complex relationships between users and items, eliciting the underlying reasons for user preferences and enriching user profiles. Leveraging this insight, we propose Knowledge Graph Enhanced Language Agents(KGLA), a framework that unifies language agents and KG for recommendation systems. In the simulated recommendation scenario, we position the user and item within the KG and integrate KG paths as natural language descriptions into the simulation. This allows language agents to interact with each other and discover sufficient rationale behind their interactions, making the simulation more accurate and aligned with real-world cases, thus improving recommendation performance. Our experimental results show that KGLA significantly improves recommendation performance (with a 33%-95% boost in NDCG@1 among three widely used benchmarks) compared to the previous best baseline method.
ScholarChemQA: Unveiling the Power of Language Models in Chemical Research Question Answering
Jul 24, 2024



Question Answering (QA) effectively evaluates language models' reasoning and knowledge depth. While QA datasets are plentiful in areas like general domain and biomedicine, academic chemistry is less explored. Chemical QA plays a crucial role in both education and research by effectively translating complex chemical information into readily understandable format. Addressing this gap, we introduce ScholarChemQA, a large-scale QA dataset constructed from chemical papers. This dataset reflects typical real-world challenges, including an imbalanced data distribution and a substantial amount of unlabeled data that can be potentially useful. Correspondingly, we introduce a QAMatch model, specifically designed to effectively answer chemical questions by fully leveraging our collected data. We first address the issue of imbalanced label distribution by re-weighting the instance-wise loss based on the inverse frequency of each class, ensuring minority classes are not dominated by majority ones during optimization. Next, we utilize the unlabeled data to enrich the learning process, generating a variety of augmentations based on a SoftMix operation and ensuring their predictions align with the same target, i.e., pseudo-labels. To ensure the quality of the pseudo-labels, we propose a calibration procedure aimed at closely aligning the pseudo-label estimates of individual samples with a desired ground truth distribution. Experiments show that our QAMatch significantly outperforms the recent similar-scale baselines and Large Language Models (LLMs) not only on our ScholarChemQA dataset but also on four benchmark datasets. We hope our benchmark and model can facilitate and promote more research on chemical QA.
Data Interpreter: An LLM Agent For Data Science
Mar 12, 2024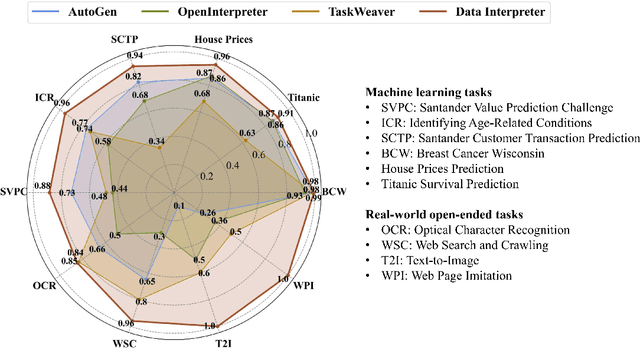
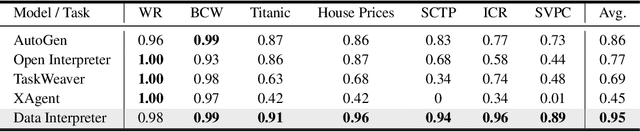
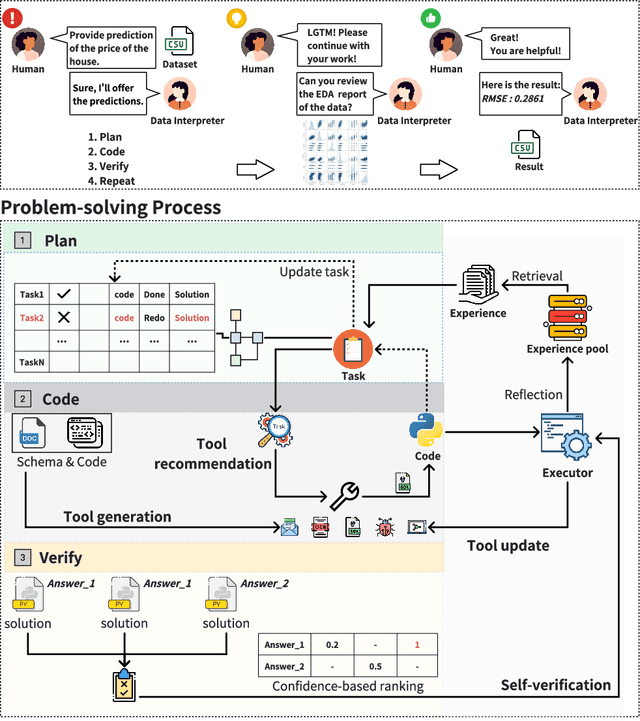

Large Language Model (LLM)-based agents have demonstrated remarkable effectiveness. However, their performance can be compromised in data science scenarios that require real-time data adjustment, expertise in optimization due to complex dependencies among various tasks, and the ability to identify logical errors for precise reasoning. In this study, we introduce the Data Interpreter, a solution designed to solve with code that emphasizes three pivotal techniques to augment problem-solving in data science: 1) dynamic planning with hierarchical graph structures for real-time data adaptability;2) tool integration dynamically to enhance code proficiency during execution, enriching the requisite expertise;3) logical inconsistency identification in feedback, and efficiency enhancement through experience recording. We evaluate the Data Interpreter on various data science and real-world tasks. Compared to open-source baselines, it demonstrated superior performance, exhibiting significant improvements in machine learning tasks, increasing from 0.86 to 0.95. Additionally, it showed a 26% increase in the MATH dataset and a remarkable 112% improvement in open-ended tasks. The solution will be released at https://github.com/geekan/MetaGPT.
Rethinking Scientific Summarization Evaluation: Grounding Explainable Metrics on Facet-aware Benchmark
Feb 22, 2024



The summarization capabilities of pretrained and large language models (LLMs) have been widely validated in general areas, but their use in scientific corpus, which involves complex sentences and specialized knowledge, has been less assessed. This paper presents conceptual and experimental analyses of scientific summarization, highlighting the inadequacies of traditional evaluation methods, such as $n$-gram, embedding comparison, and QA, particularly in providing explanations, grasping scientific concepts, or identifying key content. Subsequently, we introduce the Facet-aware Metric (FM), employing LLMs for advanced semantic matching to evaluate summaries based on different aspects. This facet-aware approach offers a thorough evaluation of abstracts by decomposing the evaluation task into simpler subtasks.Recognizing the absence of an evaluation benchmark in this domain, we curate a Facet-based scientific summarization Dataset (FD) with facet-level annotations. Our findings confirm that FM offers a more logical approach to evaluating scientific summaries. In addition, fine-tuned smaller models can compete with LLMs in scientific contexts, while LLMs have limitations in learning from in-context information in scientific domains. This suggests an area for future enhancement of LLMs.
Defending Jailbreak Prompts via In-Context Adversarial Game
Feb 20, 2024
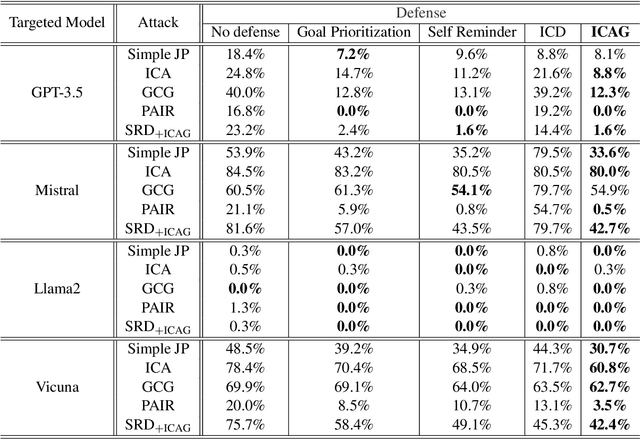

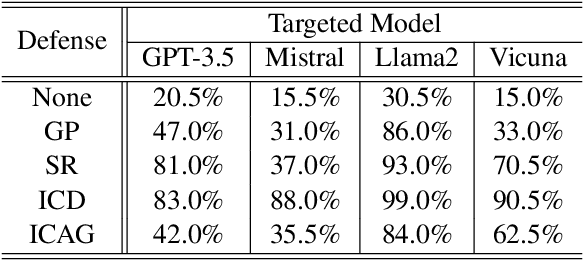
Large Language Models (LLMs) demonstrate remarkable capabilities across diverse applications. However, concerns regarding their security, particularly the vulnerability to jailbreak attacks, persist. Drawing inspiration from adversarial training in deep learning and LLM agent learning processes, we introduce the In-Context Adversarial Game (ICAG) for defending against jailbreaks without the need for fine-tuning. ICAG leverages agent learning to conduct an adversarial game, aiming to dynamically extend knowledge to defend against jailbreaks. Unlike traditional methods that rely on static datasets, ICAG employs an iterative process to enhance both the defense and attack agents. This continuous improvement process strengthens defenses against newly generated jailbreak prompts. Our empirical studies affirm ICAG's efficacy, where LLMs safeguarded by ICAG exhibit significantly reduced jailbreak success rates across various attack scenarios. Moreover, ICAG demonstrates remarkable transferability to other LLMs, indicating its potential as a versatile defense mechanism.
SceMQA: A Scientific College Entrance Level Multimodal Question Answering Benchmark
Feb 06, 2024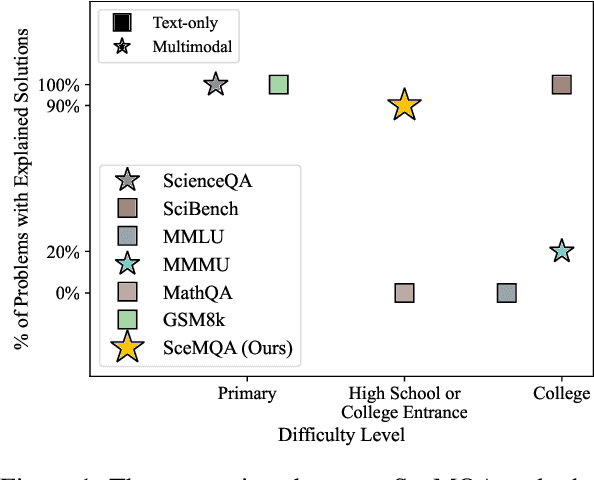

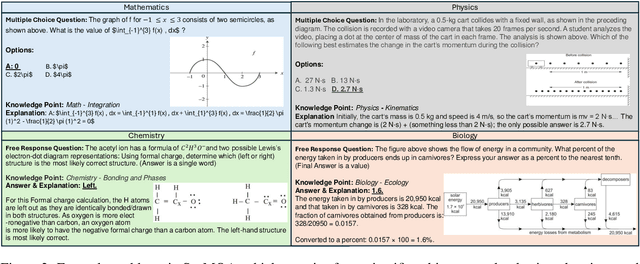
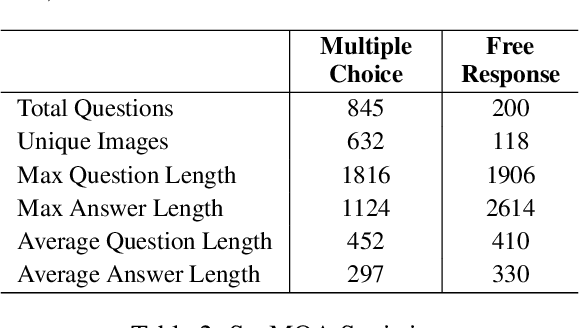
The paper introduces SceMQA, a novel benchmark for scientific multimodal question answering at the college entrance level. It addresses a critical educational phase often overlooked in existing benchmarks, spanning high school to pre-college levels. SceMQA focuses on core science subjects including Mathematics, Physics, Chemistry, and Biology. It features a blend of multiple-choice and free-response formats, ensuring a comprehensive evaluation of AI models' abilities. Additionally, our benchmark provides specific knowledge points for each problem and detailed explanations for each answer. SceMQA also uniquely presents problems with identical contexts but varied questions to facilitate a more thorough and accurate assessment of reasoning capabilities. In the experiment, we evaluate both open-source and close-source state-of-the-art Multimodal Large Language Models (MLLMs), across various experimental settings. The results show that further research and development are needed in developing more capable MLLM, as highlighted by only 50% to 60% accuracy achieved by the strongest models. Our benchmark and analysis will be available at https://scemqa.github.io/
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Jan 21, 2024



Large Language Models (LLMs) have achieved remarkable success across a wide array of tasks. Due to the impressive planning and reasoning abilities of LLMs, they have been used as autonomous agents to do many tasks automatically. Recently, based on the development of using one LLM as a single planning or decision-making agent, LLM-based multi-agent systems have achieved considerable progress in complex problem-solving and world simulation. To provide the community with an overview of this dynamic field, we present this survey to offer an in-depth discussion on the essential aspects of multi-agent systems based on LLMs, as well as the challenges. Our goal is for readers to gain substantial insights on the following questions: What domains and environments do LLM-based multi-agents simulate? How are these agents profiled and how do they communicate? What mechanisms contribute to the growth of agents' capacities? For those interested in delving into this field of study, we also summarize the commonly used datasets or benchmarks for them to have convenient access. To keep researchers updated on the latest studies, we maintain an open-source GitHub repository, dedicated to outlining the research on LLM-based multi-agent systems.
Modeling non-uniform uncertainty in Reaction Prediction via Boosting and Dropout
Oct 07, 2023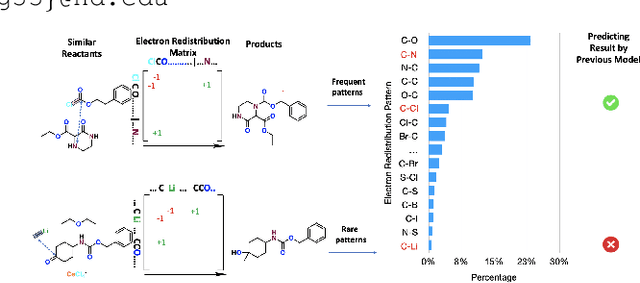
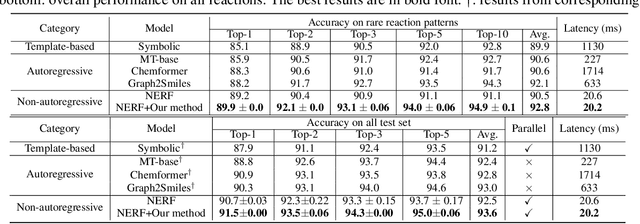
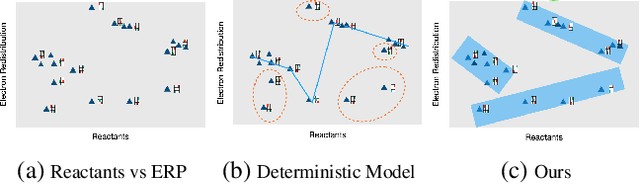
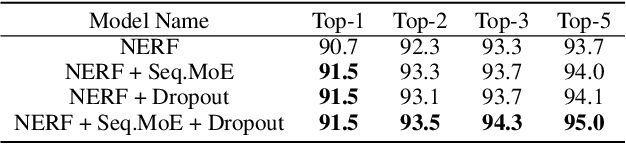
Reaction prediction has been recognized as a critical task in synthetic chemistry, where the goal is to predict the outcome of a reaction based on the given reactants. With the widespread adoption of generative models, the Variational Autoencoder(VAE) framework has typically been employed to tackle challenges in reaction prediction, where the reactants are encoded as a condition for the decoder, which then generates the product. Despite effectiveness, these conditional VAE (CVAE) models still fail to adequately account for the inherent uncertainty in reaction prediction, which primarily stems from the stochastic reaction process. The principal limitations are twofold. Firstly, in these CVAE models, the prior is independent of the reactants, leading to a default wide and assumed uniform distribution variance of the generated product. Secondly, reactants with analogous molecular representations are presumed to undergo similar electronic transition processes, thereby producing similar products. This hinders the ability to model diverse reaction mechanisms effectively. Since the variance in outcomes is inherently non-uniform, we are thus motivated to develop a framework that generates reaction products with non-uniform uncertainty. Firstly, we eliminate the latent variable in previous CVAE models to mitigate uncontrol-label noise. Instead, we introduce randomness into product generation via boosting to ensemble diverse models and cover the range of potential outcomes, and through dropout to secure models with minor variations. Additionally, we design a ranking method to union the predictions from boosting and dropout, prioritizing the most plausible products. Experimental results on the largest reaction prediction benchmark USPTO-MIT show the superior performance of our proposed method in modeling the non-uniform uncertainty compared to baselines.