 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Retail Video Annotation: A Robust Key Frame Generation Approach for Product and Customer Interaction Analysis
Jun 17, 2025Accurate video annotation plays a vital role in modern retail applications, including customer behavior analysis, product interaction detection, and in-store activity recognition. However, conventional annotation methods heavily rely on time-consuming manual labeling by human annotators, introducing non-robust frame selection and increasing operational costs. To address these challenges in the retail domain, we propose a deep learning-based approach that automates key-frame identification in retail videos and provides automatic annotations of products and customers. Our method leverages deep neural networks to learn discriminative features by embedding video frames and incorporating object detection-based techniques tailored for retail environments. Experimental results showcase the superiority of our approach over traditional methods, achieving accuracy comparable to human annotator labeling while enhancing the overall efficiency of retail video annotation. Remarkably, our approach leads to an average of 2 times cost savings in video annotation. By allowing human annotators to verify/adjust less than 5% of detected frames in the video dataset, while automating the annotation process for the remaining frames without reducing annotation quality, retailers can significantly reduce operational costs. The automation of key-frame detection enables substantial time and effort savings in retail video labeling tasks, proving highly valuable for diverse retail applications such as shopper journey analysis, product interaction detection, and in-store security monitoring.
Knowledge Graph Enhanced Language Agents for Recommendation
Oct 25, 2024



Language agents have recently been used to simulate human behavior and user-item interactions for recommendation systems. However, current language agent simulations do not understand the relationships between users and items, leading to inaccurate user profiles and ineffective recommendations. In this work, we explore the utility of Knowledge Graphs (KGs), which contain extensive and reliable relationships between users and items, for recommendation. Our key insight is that the paths in a KG can capture complex relationships between users and items, eliciting the underlying reasons for user preferences and enriching user profiles. Leveraging this insight, we propose Knowledge Graph Enhanced Language Agents(KGLA), a framework that unifies language agents and KG for recommendation systems. In the simulated recommendation scenario, we position the user and item within the KG and integrate KG paths as natural language descriptions into the simulation. This allows language agents to interact with each other and discover sufficient rationale behind their interactions, making the simulation more accurate and aligned with real-world cases, thus improving recommendation performance. Our experimental results show that KGLA significantly improves recommendation performance (with a 33%-95% boost in NDCG@1 among three widely used benchmarks) compared to the previous best baseline method.
Low-Energy Convolutional Neural Networks (CNNs) using Hadamard Method
Sep 06, 2022
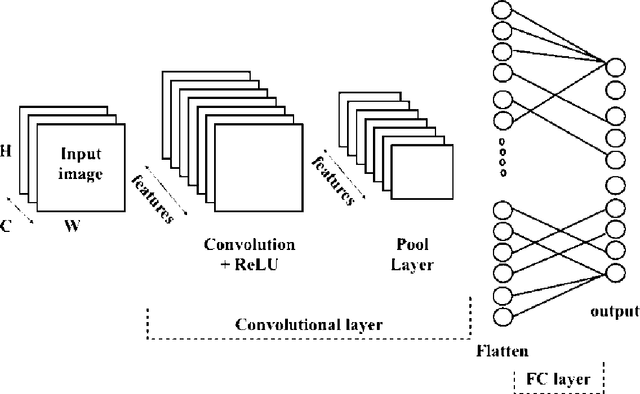
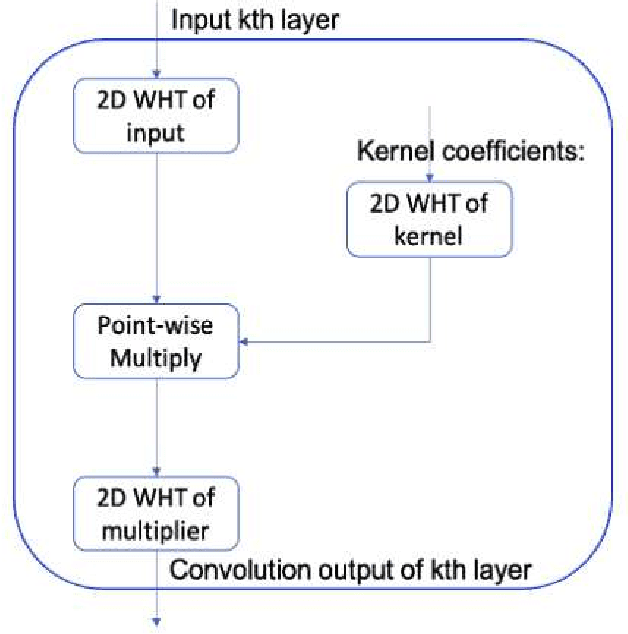
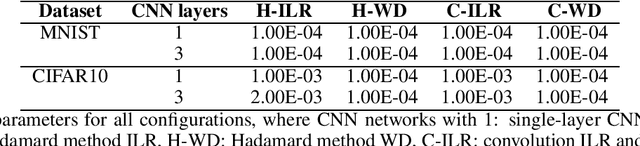
The growing demand for the internet of things (IoT) makes it necessary to implement computer vision tasks such as object recognition in low-power devices. Convolutional neural networks (CNNs) are a potential approach for object recognition and detection. However, the convolutional layer in CNN consumes significant energy compared to the fully connected layers. To mitigate this problem, a new approach based on the Hadamard transformation as an alternative to the convolution operation is demonstrated using two fundamental datasets, MNIST and CIFAR10. The mathematical expression of the Hadamard method shows the clear potential to save energy consumption compared to convolutional layers, which are helpful with BigData applications. In addition, to the test accuracy of the MNIST dataset, the Hadamard method performs similarly to the convolution method. In contrast, with the CIFAR10 dataset, test data accuracy is dropped (due to complex data and multiple channels) compared to the convolution method. Finally, the demonstrated method is helpful for other computer vision tasks when the kernel size is smaller than the input image size.
Deconvolution in Fluorescence Lifetime imaging microscopy (FLIM)
Jan 16, 2022


Fluorescence lifetime imaging microscopy (FLIM) is an important technique to understand the chemical micro-environment in cells and tissues since it provides additional contrast compared to conventional fluorescence imaging. When two fluorophores within a diffraction limit are excited, the resulting emission leads to non-linear spatial distortion and localization effects in intensity (magnitude) and lifetime (phase) components. To address this issue, in this work, we provide a theoretical model for convolution in FLIM to describe how the resulting behavior differs from conventional fluorescence microscopy. We then present a Richardson-Lucy (RL) based deconvolution including total variation (TV) regularization method to correct for the distortions in FLIM measurements due to optical convolution, and experimentally demonstrate this FLIM deconvolution method on a multi-photon microscopy (MPM)-FLIM images of fluorescent-labeled fixed bovine pulmonary arterial endothelial (BPAE) cells.
Low dosage 3D volume fluorescence microscopy imaging using compressive sensing
Jan 03, 2022
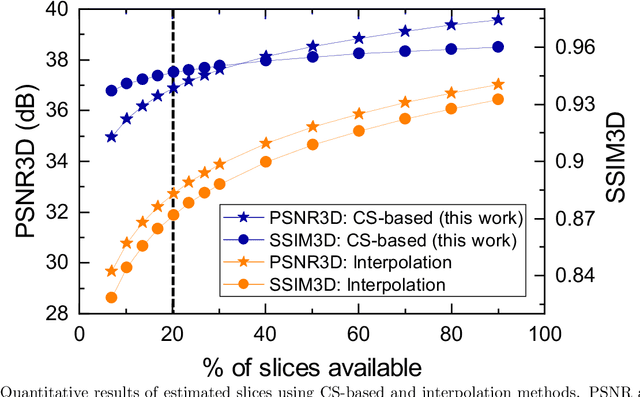

Fluorescence microscopy has been a significant tool to observe long-term imaging of embryos (in vivo) growth over time. However, cumulative exposure is phototoxic to such sensitive live samples. While techniques like light-sheet fluorescence microscopy (LSFM) allow for reduced exposure, it is not well suited for deep imaging models. Other computational techniques are computationally expensive and often lack restoration quality. To address this challenge, one can use various low-dosage imaging techniques that are developed to achieve the 3D volume reconstruction using a few slices in the axial direction (z-axis); however, they often lack restoration quality. Also, acquiring dense images (with small steps) in the axial direction is computationally expensive. To address this challenge, we present a compressive sensing (CS) based approach to fully reconstruct 3D volumes with the same signal-to-noise ratio (SNR) with less than half of the excitation dosage. We present the theory and experimentally validate the approach. To demonstrate our technique, we capture a 3D volume of the RFP labeled neurons in the zebrafish embryo spinal cord (30um thickness) with the axial sampling of 0.1um using a confocal microscope. From the results, we observe the CS-based approach achieves accurate 3D volume reconstruction from less than 20% of the entire stack optical sections. The developed CS-based methodology in this work can be easily applied to other deep imaging modalities such as two-photon and light-sheet microscopy, where reducing sample photo-toxicity is a critical challenge.
Convolutional Neural Network Denoising in Fluorescence Lifetime Imaging Microscopy (FLIM)
Mar 07, 2021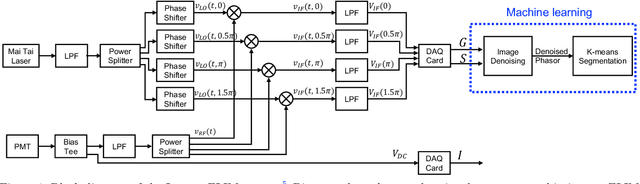



Fluorescence lifetime imaging microscopy (FLIM) systems are limited by their slow processing speed, low signal-to-noise ratio (SNR), and expensive and challenging hardware setups. In this work, we demonstrate applying a denoising convolutional network to improve FLIM SNR. The network will be integrated with an instant FLIM system with fast data acquisition based on analog signal processing, high SNR using high-efficiency pulse-modulation, and cost-effective implementation utilizing off-the-shelf radio-frequency components. Our instant FLIM system simultaneously provides the intensity, lifetime, and phasor plots \textit{in vivo} and \textit{ex vivo}. By integrating image denoising using the trained deep learning model on the FLIM data, provide accurate FLIM phasor measurements are obtained. The enhanced phasor is then passed through the K-means clustering segmentation method, an unbiased and unsupervised machine learning technique to separate different fluorophores accurately. Our experimental \textit{in vivo} mouse kidney results indicate that introducing the deep learning image denoising model before the segmentation effectively removes the noise in the phasor compared to existing methods and provides clearer segments. Hence, the proposed deep learning-based workflow provides fast and accurate automatic segmentation of fluorescence images using instant FLIM. The denoising operation is effective for the segmentation if the FLIM measurements are noisy. The clustering can effectively enhance the detection of biological structures of interest in biomedical imaging applications.
Deep learning-based super-resolution fluorescence microscopy on small datasets
Mar 07, 2021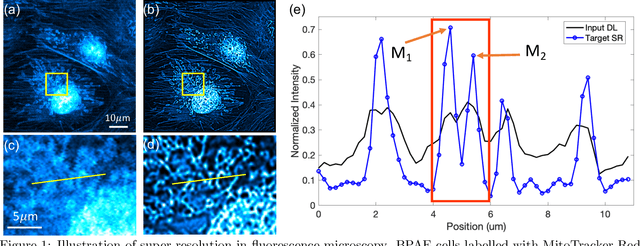
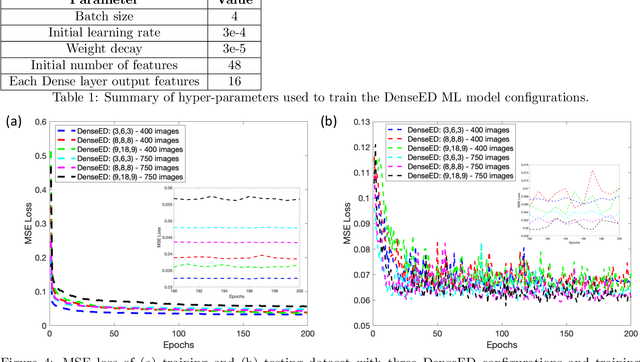
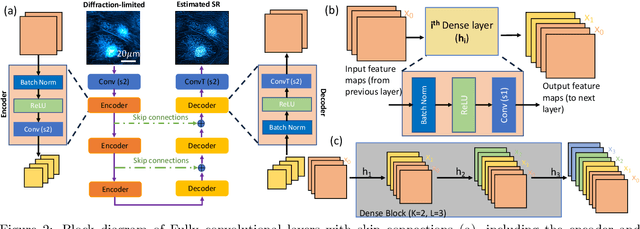
Fluorescence microscopy has enabled a dramatic development in modern biology by visualizing biological organisms with micrometer scale resolution. However, due to the diffraction limit, sub-micron/nanometer features are difficult to resolve. While various super-resolution techniques are developed to achieve nanometer-scale resolution, they often either require expensive optical setup or specialized fluorophores. In recent years, deep learning has shown the potentials to reduce the technical barrier and obtain super-resolution from diffraction-limited images. For accurate results, conventional deep learning techniques require thousands of images as a training dataset. Obtaining large datasets from biological samples is not often feasible due to the photobleaching of fluorophores, phototoxicity, and dynamic processes occurring within the organism. Therefore, achieving deep learning-based super-resolution using small datasets is challenging. We address this limitation with a new convolutional neural network-based approach that is successfully trained with small datasets and achieves super-resolution images. We captured 750 images in total from 15 different field-of-views as the training dataset to demonstrate the technique. In each FOV, a single target image is generated using the super-resolution radial fluctuation method. As expected, this small dataset failed to produce a usable model using traditional super-resolution architecture. However, using the new approach, a network can be trained to achieve super-resolution images from this small dataset. This deep learning model can be applied to other biomedical imaging modalities such as MRI and X-ray imaging, where obtaining large training datasets is challenging.
Machine learning for faster and smarter fluorescence lifetime imaging microscopy
Aug 05, 2020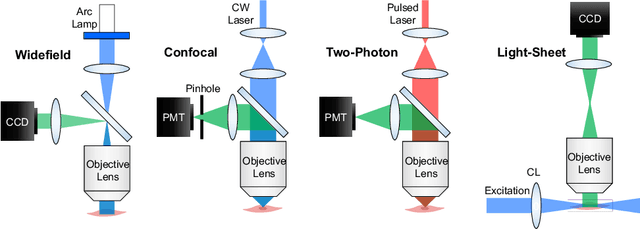
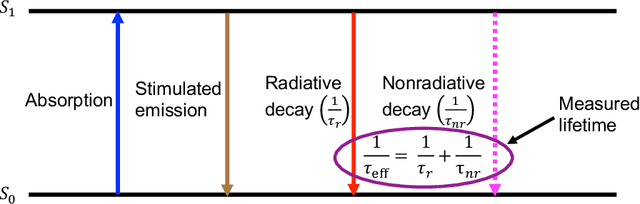
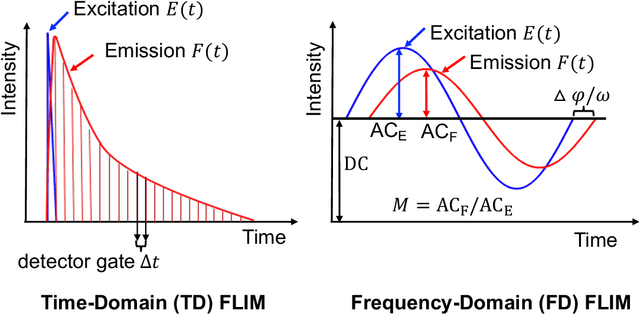
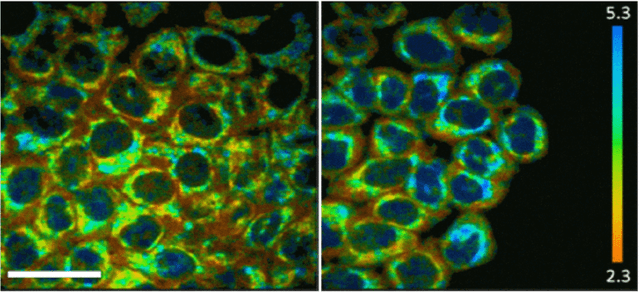
Fluorescence lifetime imaging microscopy (FLIM) is a powerful technique in biomedical research that uses the fluorophore decay rate to provide additional contrast in fluorescence microscopy. However, at present, the calculation, analysis, and interpretation of FLIM is a complex, slow, and computationally expensive process. Machine learning (ML) techniques are well suited to extract and interpret measurements from multi-dimensional FLIM data sets with substantial improvement in speed over conventional methods. In this topical review, we first discuss the basics of FILM and ML. Second, we provide a summary of lifetime extraction strategies using ML and its applications in classifying and segmenting FILM images with higher accuracy compared to conventional methods. Finally, we discuss two potential directions to improve FLIM with ML with proof of concept demonstrations.
Performance Analysis of Semi-supervised Learning in the Small-data Regime using VAEs
Feb 26, 2020
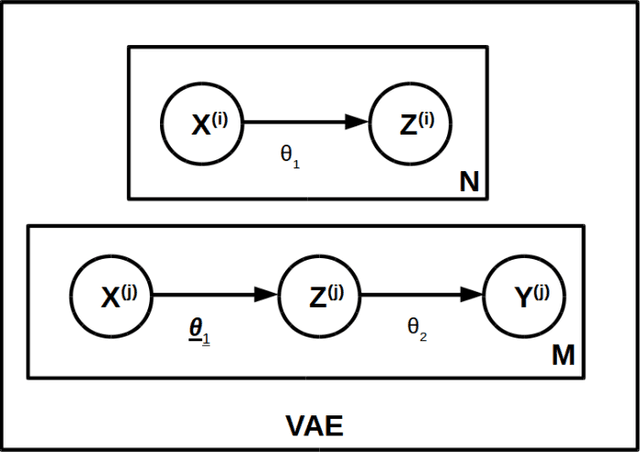
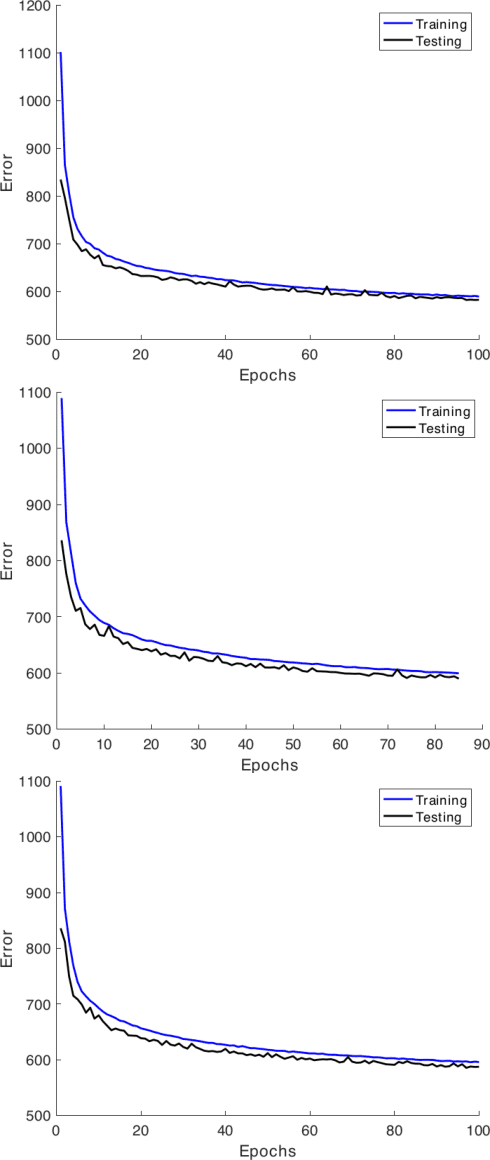
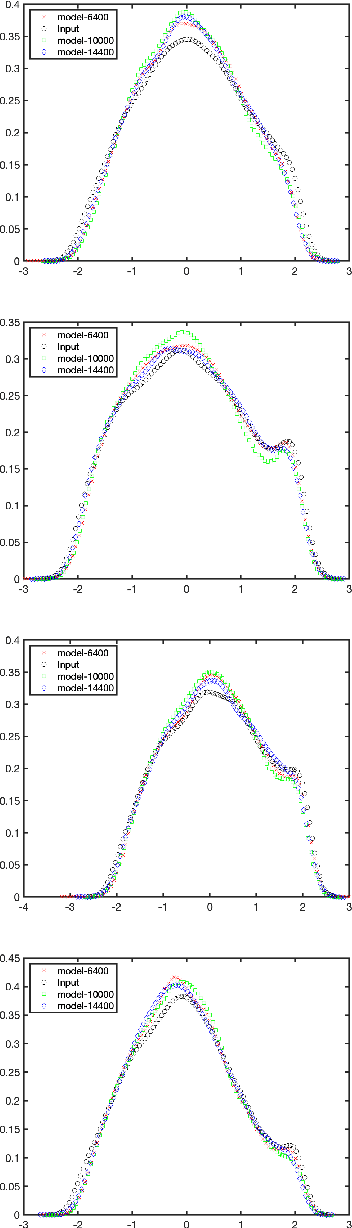
Extracting large amounts of data from biological samples is not feasible due to radiation issues, and image processing in the small-data regime is one of the critical challenges when working with a limited amount of data. In this work, we applied an existing algorithm named Variational Auto Encoder (VAE) that pre-trains a latent space representation of the data to capture the features in a lower-dimension for the small-data regime input. The fine-tuned latent space provides constant weights that are useful for classification. Here we will present the performance analysis of the VAE algorithm with different latent space sizes in the semi-supervised learning using the CIFAR-10 dataset.