 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Search Agent with One Line of Code
Mar 10, 2026Tool-based Agentic Reinforcement Learning (TARL) has emerged as a promising paradigm for training search agents to interact with external tools for a multi-turn information-seeking process autonomously. However, we identify a critical training instability that leads to catastrophic model collapse: Importance Sampling Distribution Drift(ISDD). In Group Relative Policy Optimization(GRPO), a widely adopted TARL algorithm, ISDD manifests as a precipitous decline in the importance sampling ratios, which nullifies gradient updates and triggers irreversible training failure. To address this, we propose \textbf{S}earch \textbf{A}gent \textbf{P}olicy \textbf{O}ptimization (\textbf{SAPO}), which stabilizes training via a conditional token-level KL constraint. Unlike hard clipping, which ignores distributional divergence, SAPO selectively penalizes the KL divergence between the current and old policies. Crucially, this penalty is applied only to positive tokens with low probabilities where the policy has shifted excessively, thereby preventing distribution drift while preserving gradient flow. Remarkably, SAPO requires only one-line code modification to standard GRPO, ensuring immediate deployability. Extensive experiments across seven QA benchmarks demonstrate that SAPO achieves \textbf{+10.6\% absolute improvement} (+31.5\% relative) over Search-R1, yielding consistent gains across varying model scales (1.5B, 14B) and families (Qwen, LLaMA).
Deconvolution in Fluorescence Lifetime imaging microscopy (FLIM)
Jan 16, 2022


Fluorescence lifetime imaging microscopy (FLIM) is an important technique to understand the chemical micro-environment in cells and tissues since it provides additional contrast compared to conventional fluorescence imaging. When two fluorophores within a diffraction limit are excited, the resulting emission leads to non-linear spatial distortion and localization effects in intensity (magnitude) and lifetime (phase) components. To address this issue, in this work, we provide a theoretical model for convolution in FLIM to describe how the resulting behavior differs from conventional fluorescence microscopy. We then present a Richardson-Lucy (RL) based deconvolution including total variation (TV) regularization method to correct for the distortions in FLIM measurements due to optical convolution, and experimentally demonstrate this FLIM deconvolution method on a multi-photon microscopy (MPM)-FLIM images of fluorescent-labeled fixed bovine pulmonary arterial endothelial (BPAE) cells.
Convolutional Neural Network Denoising in Fluorescence Lifetime Imaging Microscopy (FLIM)
Mar 07, 2021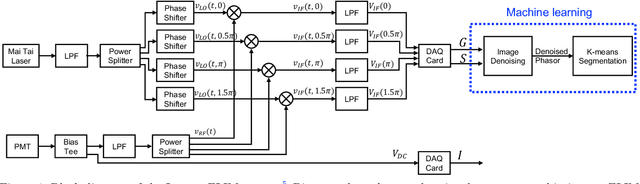



Fluorescence lifetime imaging microscopy (FLIM) systems are limited by their slow processing speed, low signal-to-noise ratio (SNR), and expensive and challenging hardware setups. In this work, we demonstrate applying a denoising convolutional network to improve FLIM SNR. The network will be integrated with an instant FLIM system with fast data acquisition based on analog signal processing, high SNR using high-efficiency pulse-modulation, and cost-effective implementation utilizing off-the-shelf radio-frequency components. Our instant FLIM system simultaneously provides the intensity, lifetime, and phasor plots \textit{in vivo} and \textit{ex vivo}. By integrating image denoising using the trained deep learning model on the FLIM data, provide accurate FLIM phasor measurements are obtained. The enhanced phasor is then passed through the K-means clustering segmentation method, an unbiased and unsupervised machine learning technique to separate different fluorophores accurately. Our experimental \textit{in vivo} mouse kidney results indicate that introducing the deep learning image denoising model before the segmentation effectively removes the noise in the phasor compared to existing methods and provides clearer segments. Hence, the proposed deep learning-based workflow provides fast and accurate automatic segmentation of fluorescence images using instant FLIM. The denoising operation is effective for the segmentation if the FLIM measurements are noisy. The clustering can effectively enhance the detection of biological structures of interest in biomedical imaging applications.
Deep learning-based super-resolution fluorescence microscopy on small datasets
Mar 07, 2021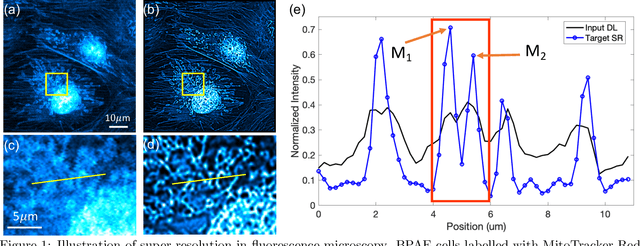
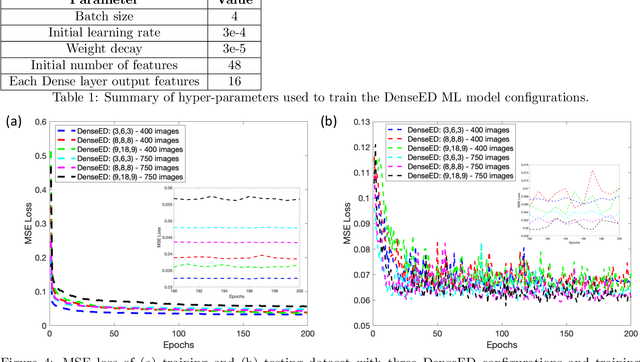
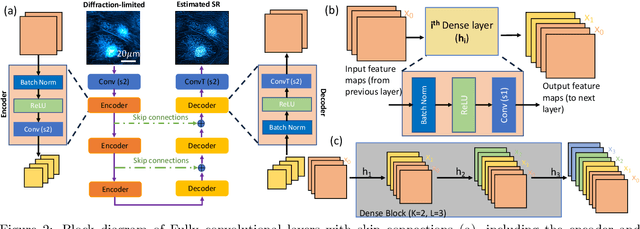
Fluorescence microscopy has enabled a dramatic development in modern biology by visualizing biological organisms with micrometer scale resolution. However, due to the diffraction limit, sub-micron/nanometer features are difficult to resolve. While various super-resolution techniques are developed to achieve nanometer-scale resolution, they often either require expensive optical setup or specialized fluorophores. In recent years, deep learning has shown the potentials to reduce the technical barrier and obtain super-resolution from diffraction-limited images. For accurate results, conventional deep learning techniques require thousands of images as a training dataset. Obtaining large datasets from biological samples is not often feasible due to the photobleaching of fluorophores, phototoxicity, and dynamic processes occurring within the organism. Therefore, achieving deep learning-based super-resolution using small datasets is challenging. We address this limitation with a new convolutional neural network-based approach that is successfully trained with small datasets and achieves super-resolution images. We captured 750 images in total from 15 different field-of-views as the training dataset to demonstrate the technique. In each FOV, a single target image is generated using the super-resolution radial fluctuation method. As expected, this small dataset failed to produce a usable model using traditional super-resolution architecture. However, using the new approach, a network can be trained to achieve super-resolution images from this small dataset. This deep learning model can be applied to other biomedical imaging modalities such as MRI and X-ray imaging, where obtaining large training datasets is challenging.
Hybrid Stochastic-Deterministic Minibatch Proximal Gradient: Less-Than-Single-Pass Optimization with Nearly Optimal Generalization
Sep 18, 2020
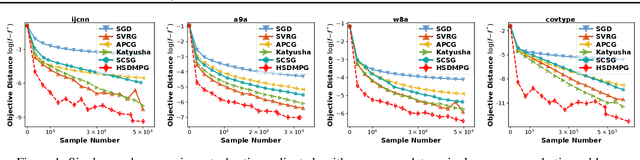
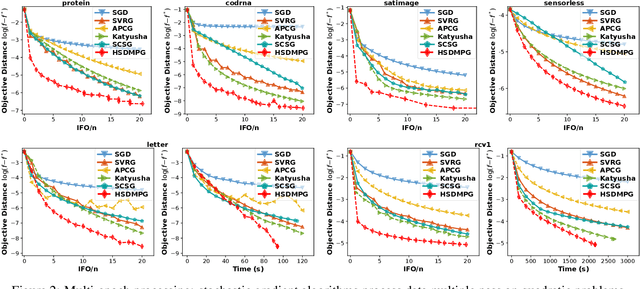

Stochastic variance-reduced gradient (SVRG) algorithms have been shown to work favorably in solving large-scale learning problems. Despite the remarkable success, the stochastic gradient complexity of SVRG-type algorithms usually scales linearly with data size and thus could still be expensive for huge data. To address this deficiency, we propose a hybrid stochastic-deterministic minibatch proximal gradient (HSDMPG) algorithm for strongly-convex problems that enjoys provably improved data-size-independent complexity guarantees. More precisely, for quadratic loss $F(\theta)$ of $n$ components, we prove that HSDMPG can attain an $\epsilon$-optimization-error $\mathbb{E}[F(\theta)-F(\theta^*)]\leq\epsilon$ within $\mathcal{O}\Big(\frac{\kappa^{1.5}\epsilon^{0.75}\log^{1.5}(\frac{1}{\epsilon})+1}{\epsilon}\wedge\Big(\kappa \sqrt{n}\log^{1.5}\big(\frac{1}{\epsilon}\big)+n\log\big(\frac{1}{\epsilon}\big)\Big)\Big)$ stochastic gradient evaluations, where $\kappa$ is condition number. For generic strongly convex loss functions, we prove a nearly identical complexity bound though at the cost of slightly increased logarithmic factors. For large-scale learning problems, our complexity bounds are superior to those of the prior state-of-the-art SVRG algorithms with or without dependence on data size. Particularly, in the case of $\epsilon=\mathcal{O}\big(1/\sqrt{n}\big)$ which is at the order of intrinsic excess error bound of a learning model and thus sufficient for generalization, the stochastic gradient complexity bounds of HSDMPG for quadratic and generic loss functions are respectively $\mathcal{O} (n^{0.875}\log^{1.5}(n))$ and $\mathcal{O} (n^{0.875}\log^{2.25}(n))$, which to our best knowledge, for the first time achieve optimal generalization in less than a single pass over data. Extensive numerical results demonstrate the computational advantages of our algorithm over the prior ones.
Machine learning for faster and smarter fluorescence lifetime imaging microscopy
Aug 05, 2020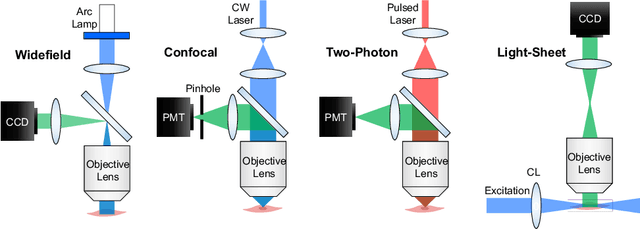
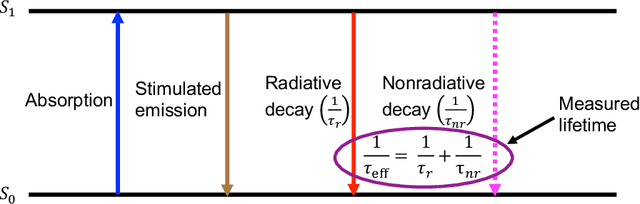
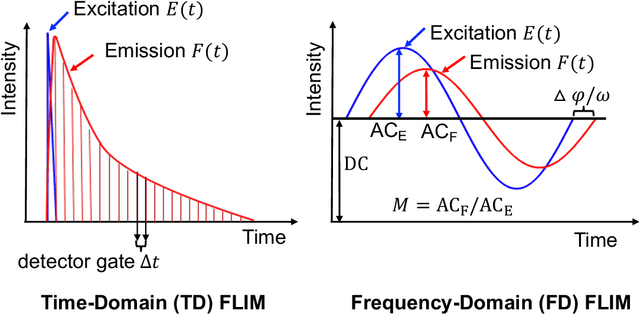
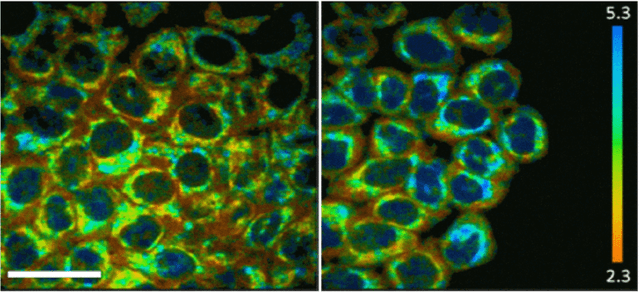
Fluorescence lifetime imaging microscopy (FLIM) is a powerful technique in biomedical research that uses the fluorophore decay rate to provide additional contrast in fluorescence microscopy. However, at present, the calculation, analysis, and interpretation of FLIM is a complex, slow, and computationally expensive process. Machine learning (ML) techniques are well suited to extract and interpret measurements from multi-dimensional FLIM data sets with substantial improvement in speed over conventional methods. In this topical review, we first discuss the basics of FILM and ML. Second, we provide a summary of lifetime extraction strategies using ML and its applications in classifying and segmenting FILM images with higher accuracy compared to conventional methods. Finally, we discuss two potential directions to improve FLIM with ML with proof of concept demonstrations.
Bidirectional-Convolutional LSTM Based Spectral-Spatial Feature Learning for Hyperspectral Image Classification
Mar 23, 2017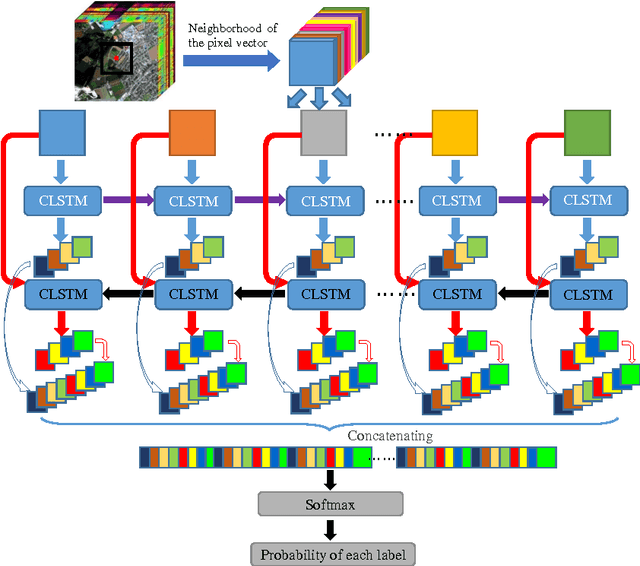
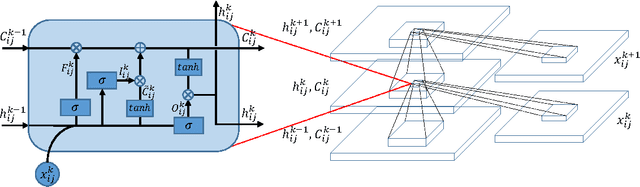
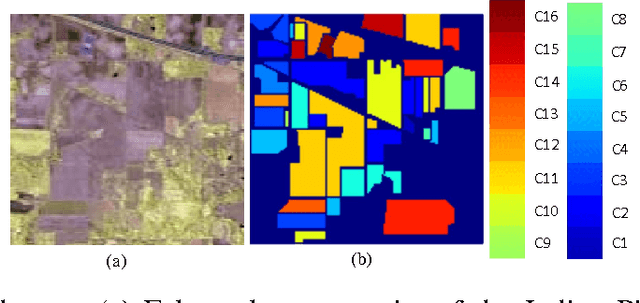

This paper proposes a novel deep learning framework named bidirectional-convolutional long short term memory (Bi-CLSTM) network to automatically learn the spectral-spatial feature from hyperspectral images (HSIs). In the network, the issue of spectral feature extraction is considered as a sequence learning problem, and a recurrent connection operator across the spectral domain is used to address it. Meanwhile, inspired from the widely used convolutional neural network (CNN), a convolution operator across the spatial domain is incorporated into the network to extract the spatial feature. Besides, to sufficiently capture the spectral information, a bidirectional recurrent connection is proposed. In the classification phase, the learned features are concatenated into a vector and fed to a softmax classifier via a fully-connected operator. To validate the effectiveness of the proposed Bi-CLSTM framework, we compare it with several state-of-the-art methods, including the CNN framework, on three widely used HSIs. The obtained results show that Bi-CLSTM can improve the classification performance as compared to other methods.
Training Skinny Deep Neural Networks with Iterative Hard Thresholding Methods
Jul 19, 2016
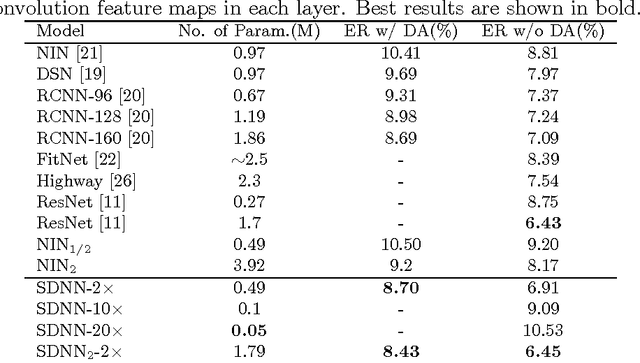
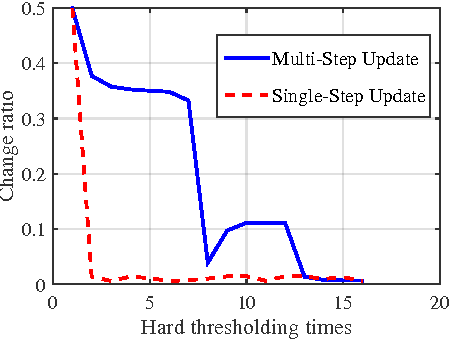
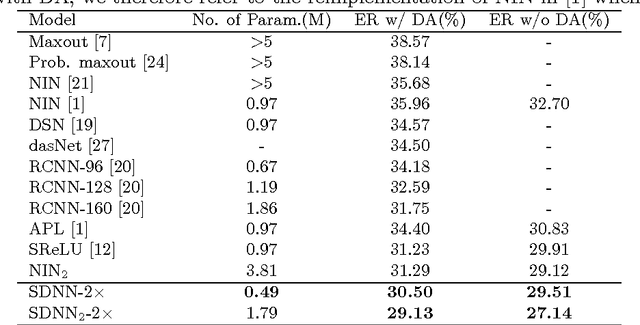
Deep neural networks have achieved remarkable success in a wide range of practical problems. However, due to the inherent large parameter space, deep models are notoriously prone to overfitting and difficult to be deployed in portable devices with limited memory. In this paper, we propose an iterative hard thresholding (IHT) approach to train Skinny Deep Neural Networks (SDNNs). An SDNN has much fewer parameters yet can achieve competitive or even better performance than its full CNN counterpart. More concretely, the IHT approach trains an SDNN through following two alternative phases: (I) perform hard thresholding to drop connections with small activations and fine-tune the other significant filters; (II)~re-activate the frozen connections and train the entire network to improve its overall discriminative capability. We verify the superiority of SDNNs in terms of efficiency and classification performance on four benchmark object recognition datasets, including CIFAR-10, CIFAR-100, MNIST and ImageNet. Experimental results clearly demonstrate that IHT can be applied for training SDNN based on various CNN architectures such as NIN and AlexNet.
Unsupervised Pretraining Encourages Moderate-Sparseness
Jun 09, 2014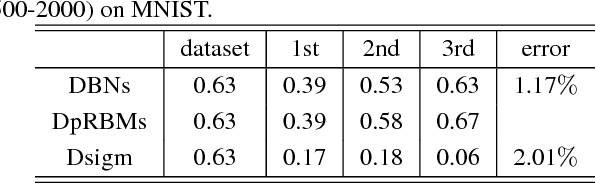
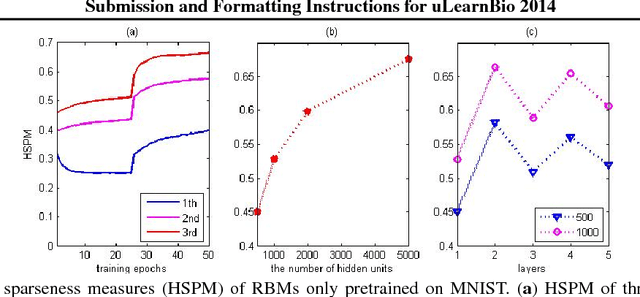
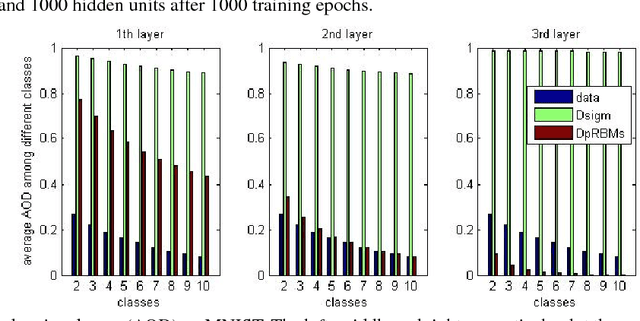
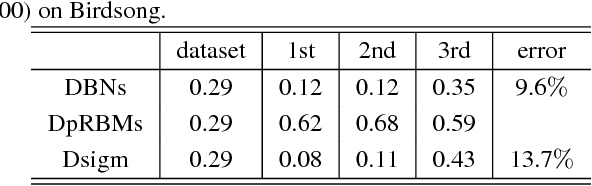
It is well known that direct training of deep neural networks will generally lead to poor results. A major progress in recent years is the invention of various pretraining methods to initialize network parameters and it was shown that such methods lead to good prediction performance. However, the reason for the success of pretraining has not been fully understood, although it was argued that regularization and better optimization play certain roles. This paper provides another explanation for the effectiveness of pretraining, where we show pretraining leads to a sparseness of hidden unit activation in the resulting neural networks. The main reason is that the pretraining models can be interpreted as an adaptive sparse coding. Compared to deep neural network with sigmoid function, our experimental results on MNIST and Birdsong further support this sparseness observation.
Robust Low-Rank Subspace Segmentation with Semidefinite Guarantees
Oct 08, 2010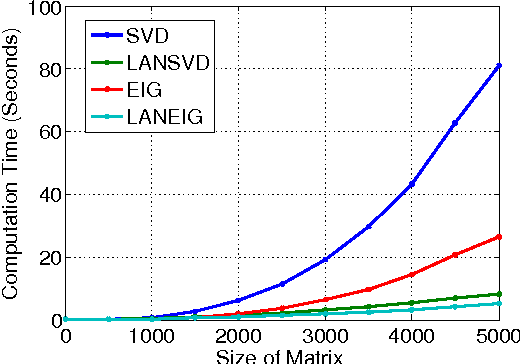
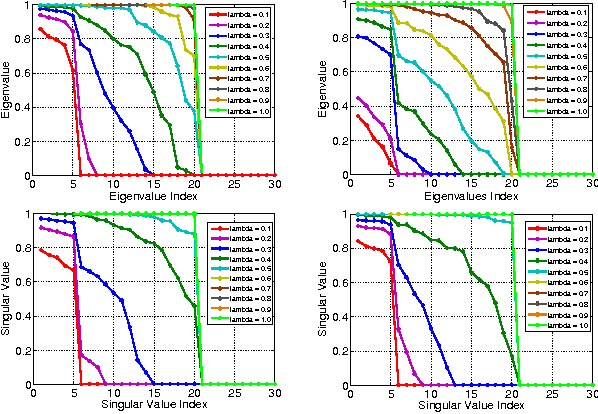

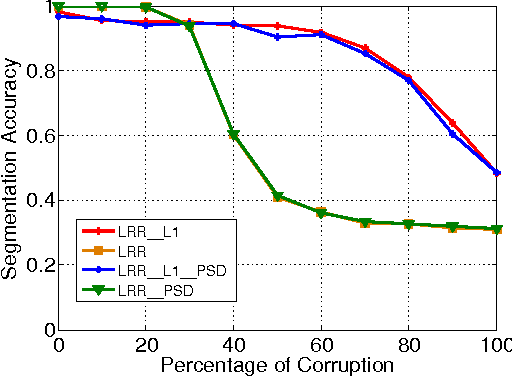
Recently there is a line of research work proposing to employ Spectral Clustering (SC) to segment (group){Throughout the paper, we use segmentation, clustering, and grouping, and their verb forms, interchangeably.} high-dimensional structural data such as those (approximately) lying on subspaces {We follow {liu2010robust} and use the term "subspace" to denote both linear subspaces and affine subspaces. There is a trivial conversion between linear subspaces and affine subspaces as mentioned therein.} or low-dimensional manifolds. By learning the affinity matrix in the form of sparse reconstruction, techniques proposed in this vein often considerably boost the performance in subspace settings where traditional SC can fail. Despite the success, there are fundamental problems that have been left unsolved: the spectrum property of the learned affinity matrix cannot be gauged in advance, and there is often one ugly symmetrization step that post-processes the affinity for SC input. Hence we advocate to enforce the symmetric positive semidefinite constraint explicitly during learning (Low-Rank Representation with Positive SemiDefinite constraint, or LRR-PSD), and show that factually it can be solved in an exquisite scheme efficiently instead of general-purpose SDP solvers that usually scale up poorly. We provide rigorous mathematical derivations to show that, in its canonical form, LRR-PSD is equivalent to the recently proposed Low-Rank Representation (LRR) scheme {liu2010robust}, and hence offer theoretic and practical insights to both LRR-PSD and LRR, inviting future research. As per the computational cost, our proposal is at most comparable to that of LRR, if not less. We validate our theoretic analysis and optimization scheme by experiments on both synthetic and real data sets.