 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Pretraining Encourages Moderate-Sparseness
Paper and Code
Jun 09, 2014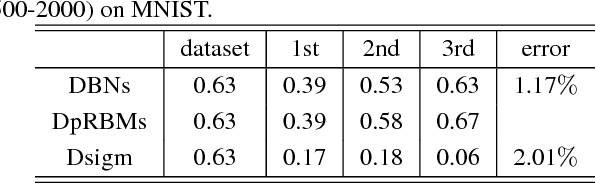
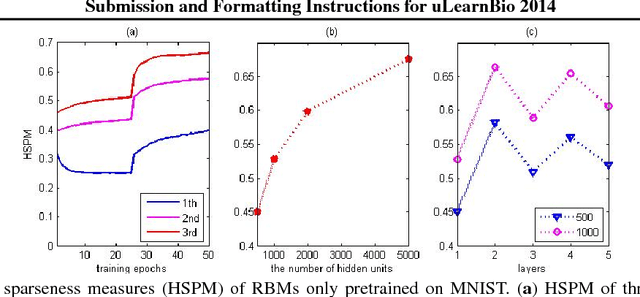
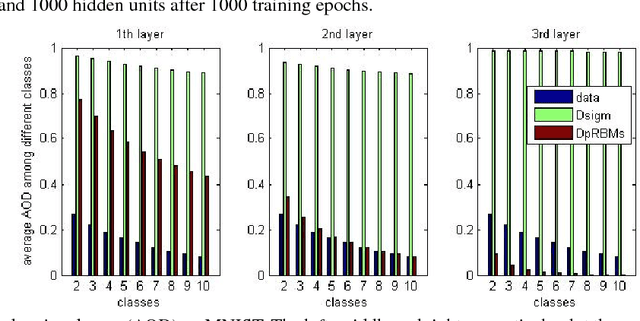
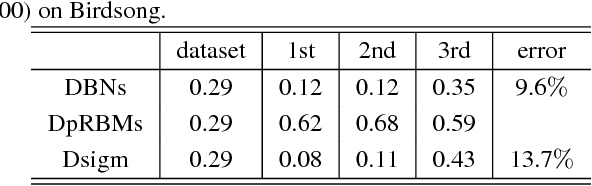
It is well known that direct training of deep neural networks will generally lead to poor results. A major progress in recent years is the invention of various pretraining methods to initialize network parameters and it was shown that such methods lead to good prediction performance. However, the reason for the success of pretraining has not been fully understood, although it was argued that regularization and better optimization play certain roles. This paper provides another explanation for the effectiveness of pretraining, where we show pretraining leads to a sparseness of hidden unit activation in the resulting neural networks. The main reason is that the pretraining models can be interpreted as an adaptive sparse coding. Compared to deep neural network with sigmoid function, our experimental results on MNIST and Birdsong further support this sparseness observation.