 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Prototype Potential: An Efficient Tuning Framework for Few-Shot Class-Incremental Learning
Feb 05, 2026Few-shot class-incremental learning (FSCIL) seeks to continuously learn new classes from very limited samples while preserving previously acquired knowledge. Traditional methods often utilize a frozen pre-trained feature extractor to generate static class prototypes, which suffer from the inherent representation bias of the backbone. While recent prompt-based tuning methods attempt to adapt the backbone via minimal parameter updates, given the constraint of extreme data scarcity, the model's capacity to assimilate novel information and substantively enhance its global discriminative power is inherently limited. In this paper, we propose a novel shift in perspective: freezing the feature extractor while fine-tuning the prototypes. We argue that the primary challenge in FSCIL is not feature acquisition, but rather the optimization of decision regions within a static, high-quality feature space. To this end, we introduce an efficient prototype fine-tuning framework that evolves static centroids into dynamic, learnable components. The framework employs a dual-calibration method consisting of class-specific and task-aware offsets. These components function synergistically to improve the discriminative capacity of prototypes for ongoing incremental classes. Extensive results demonstrate that our method attains superior performance across multiple benchmarks while requiring minimal learnable parameters.
Hyperspectral Image Classification with Attention Aided CNNs
Jun 12, 2020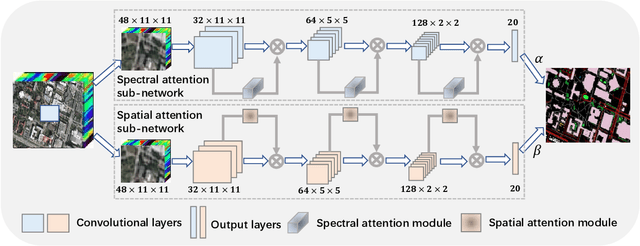
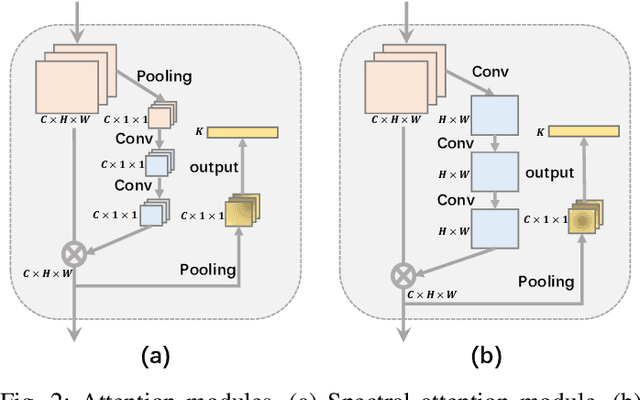

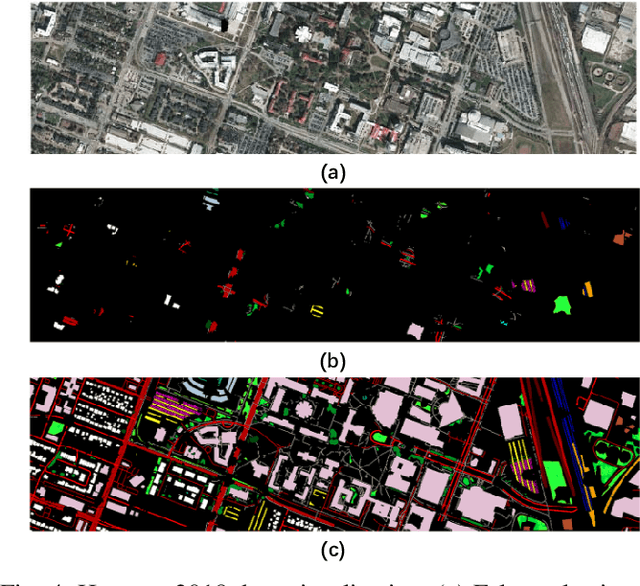
Convolutional neural networks (CNNs) have been widely used for hyperspectral image classification. As a common process, small cubes are firstly cropped from the hyperspectral image and then fed into CNNs to extract spectral and spatial features. It is well known that different spectral bands and spatial positions in the cubes have different discriminative abilities. If fully explored, this prior information will help improve the learning capacity of CNNs. Along this direction, we propose an attention aided CNN model for spectral-spatial classification of hyperspectral images. Specifically, a spectral attention sub-network and a spatial attention sub-network are proposed for spectral and spatial classification, respectively. Both of them are based on the traditional CNN model, and incorporate attention modules to aid networks focus on more discriminative channels or positions. In the final classification phase, the spectral classification result and the spatial classification result are combined together via an adaptively weighted summation method. To evaluate the effectiveness of the proposed model, we conduct experiments on three standard hyperspectral datasets. The experimental results show that the proposed model can achieve superior performance compared to several state-of-the-art CNN-related models.
Feature Extraction for Hyperspectral Imagery: The Evolution from Shallow to Deep
Mar 06, 2020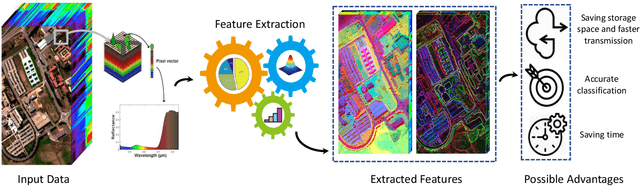
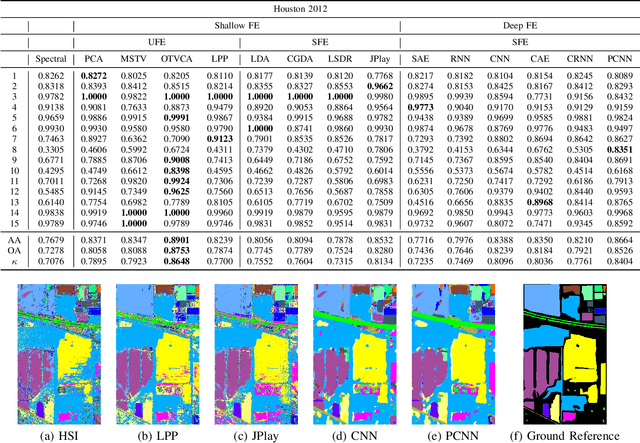
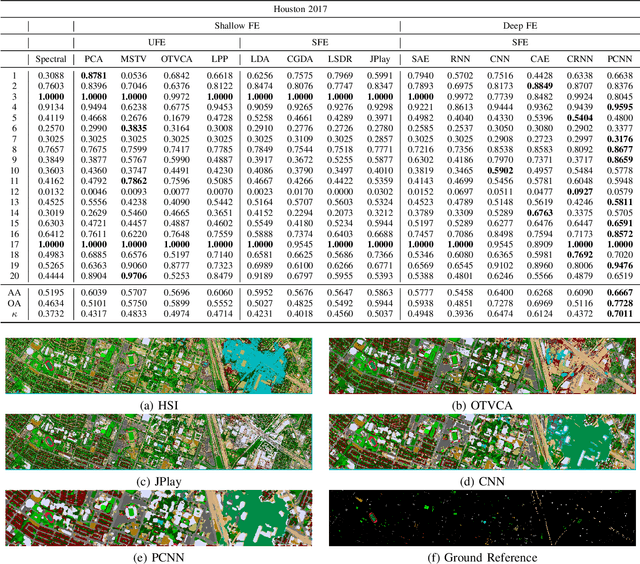

Hyperspectral images provide detailed spectral information through hundreds of (narrow) spectral channels (also known as dimensionality or bands) with continuous spectral information that can accurately classify diverse materials of interest. The increased dimensionality of such data makes it possible to significantly improve data information content but provides a challenge to the conventional techniques (the so-called curse of dimensionality) for accurate analysis of hyperspectral images. Feature extraction, as a vibrant field of research in the hyperspectral community, evolved through decades of research to address this issue and extract informative features suitable for data representation and classification. The advances in feature extraction have been inspired by two fields of research, including the popularization of image and signal processing as well as machine (deep) learning, leading to two types of feature extraction approaches named shallow and deep techniques. This article outlines the advances in feature extraction approaches for hyperspectral imagery by providing a technical overview of the state-of-the-art techniques, providing useful entry points for researchers at different levels, including students, researchers, and senior researchers, willing to explore novel investigations on this challenging topic. In more detail, this paper provides a bird's eye view over shallow (both supervised and unsupervised) and deep feature extraction approaches specifically dedicated to the topic of hyperspectral feature extraction and its application on hyperspectral image classification. Additionally, this paper compares 15 advanced techniques with an emphasis on their methodological foundations in terms of classification accuracies. Furthermore, the codes and libraries are shared at https://github.com/BehnoodRasti/HyFTech-Hyperspectral-Shallow-Deep-Feature-Extraction-Toolbox.
Classification of Hyperspectral and LiDAR Data Using Coupled CNNs
Feb 04, 2020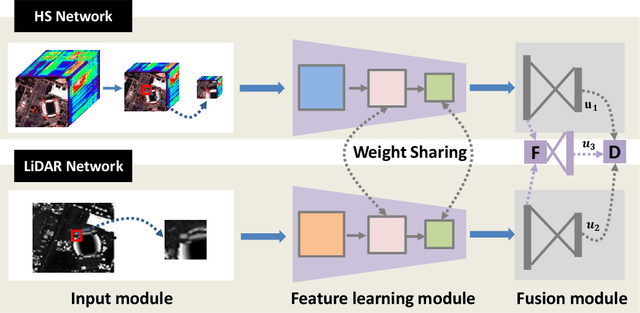
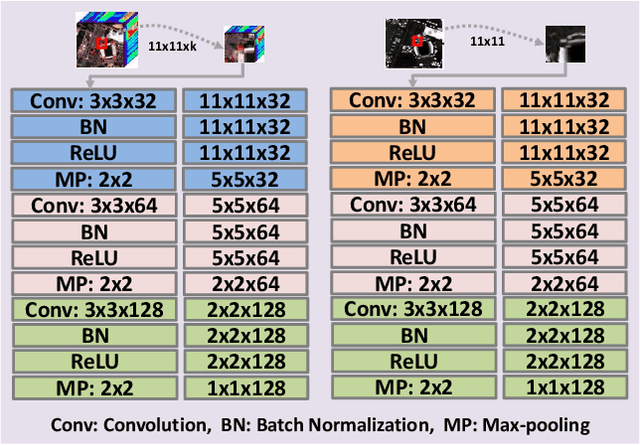
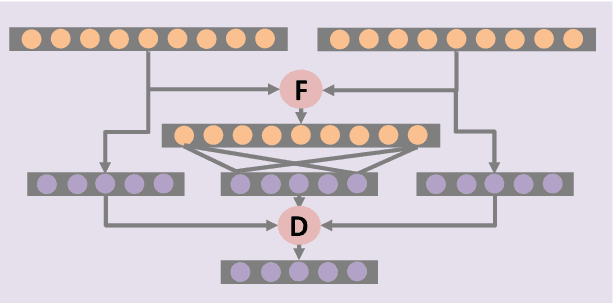
In this paper, we propose an efficient and effective framework to fuse hyperspectral and Light Detection And Ranging (LiDAR) data using two coupled convolutional neural networks (CNNs). One CNN is designed to learn spectral-spatial features from hyperspectral data, and the other one is used to capture the elevation information from LiDAR data. Both of them consist of three convolutional layers, and the last two convolutional layers are coupled together via a parameter sharing strategy. In the fusion phase, feature-level and decision-level fusion methods are simultaneously used to integrate these heterogeneous features sufficiently. For the feature-level fusion, three different fusion strategies are evaluated, including the concatenation strategy, the maximization strategy, and the summation strategy. For the decision-level fusion, a weighted summation strategy is adopted, where the weights are determined by the classification accuracy of each output. The proposed model is evaluated on an urban data set acquired over Houston, USA, and a rural one captured over Trento, Italy. On the Houston data, our model can achieve a new record overall accuracy of 96.03%. On the Trento data, it achieves an overall accuracy of 99.12%. These results sufficiently certify the effectiveness of our proposed model.
Cascaded Recurrent Neural Networks for Hyperspectral Image Classification
Feb 28, 2019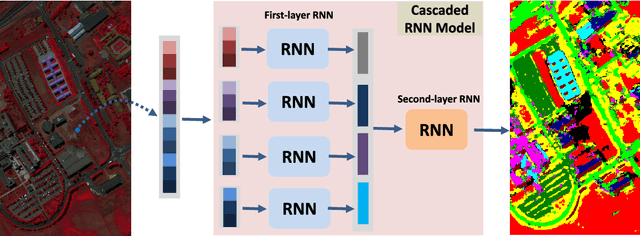
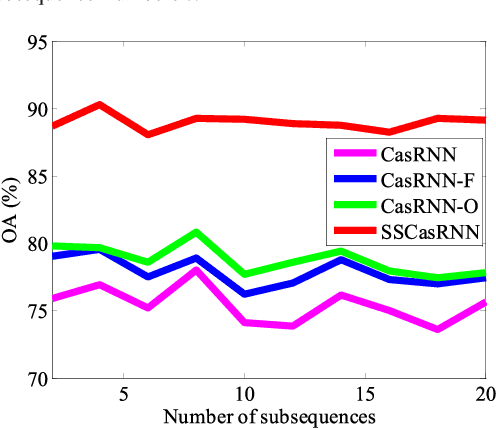
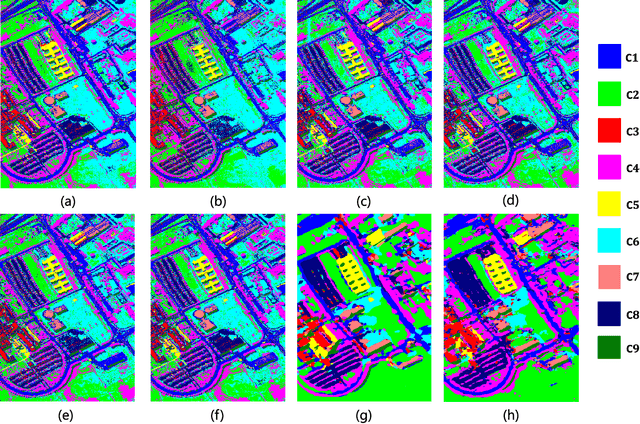
By considering the spectral signature as a sequence, recurrent neural networks (RNNs) have been successfully used to learn discriminative features from hyperspectral images (HSIs) recently. However, most of these models only input the whole spectral bands into RNNs directly, which may not fully explore the specific properties of HSIs. In this paper, we propose a cascaded RNN model using gated recurrent units (GRUs) to explore the redundant and complementary information of HSIs. It mainly consists of two RNN layers. The first RNN layer is used to eliminate redundant information between adjacent spectral bands, while the second RNN layer aims to learn the complementary information from non-adjacent spectral bands. To improve the discriminative ability of the learned features, we design two strategies for the proposed model. Besides, considering the rich spatial information contained in HSIs, we further extend the proposed model to its spectral-spatial counterpart by incorporating some convolutional layers. To test the effectiveness of our proposed models, we conduct experiments on two widely used HSIs. The experimental results show that our proposed models can achieve better results than the compared models.
Bidirectional-Convolutional LSTM Based Spectral-Spatial Feature Learning for Hyperspectral Image Classification
Mar 23, 2017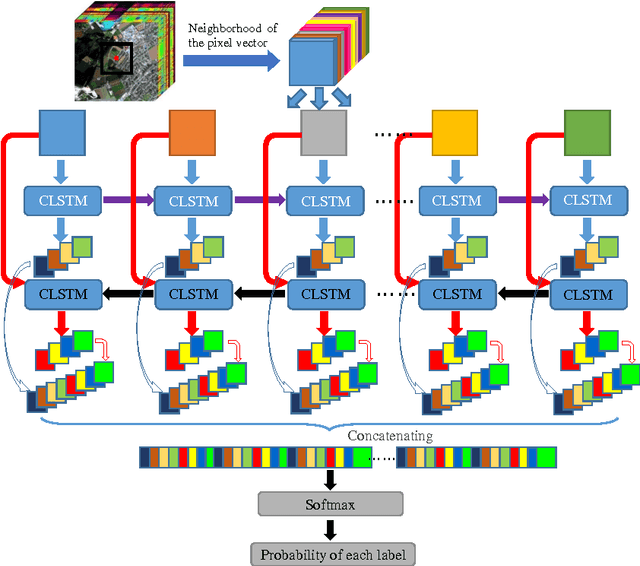
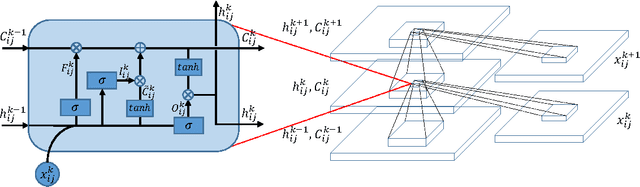

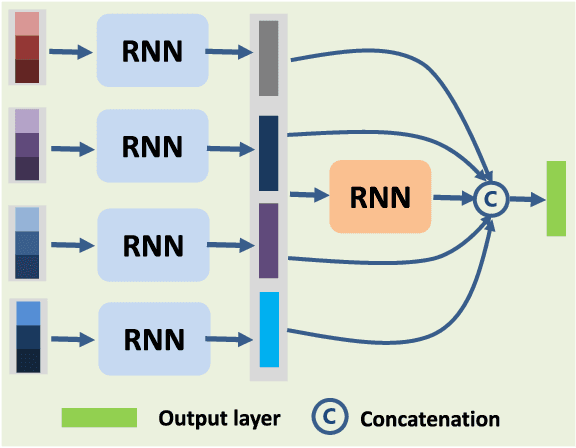
This paper proposes a novel deep learning framework named bidirectional-convolutional long short term memory (Bi-CLSTM) network to automatically learn the spectral-spatial feature from hyperspectral images (HSIs). In the network, the issue of spectral feature extraction is considered as a sequence learning problem, and a recurrent connection operator across the spectral domain is used to address it. Meanwhile, inspired from the widely used convolutional neural network (CNN), a convolution operator across the spatial domain is incorporated into the network to extract the spatial feature. Besides, to sufficiently capture the spectral information, a bidirectional recurrent connection is proposed. In the classification phase, the learned features are concatenated into a vector and fed to a softmax classifier via a fully-connected operator. To validate the effectiveness of the proposed Bi-CLSTM framework, we compare it with several state-of-the-art methods, including the CNN framework, on three widely used HSIs. The obtained results show that Bi-CLSTM can improve the classification performance as compared to other methods.
Learning Multi-Scale Deep Features for High-Resolution Satellite Image Classification
Nov 11, 2016

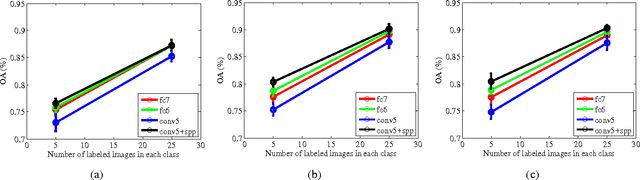
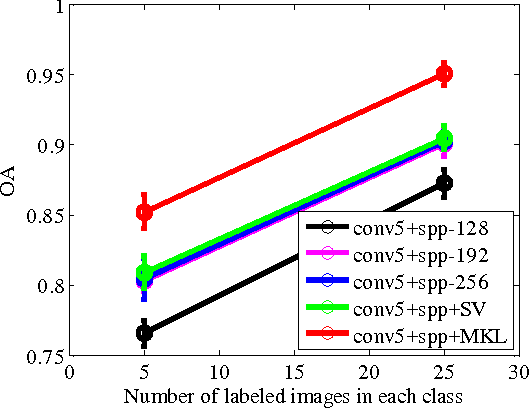
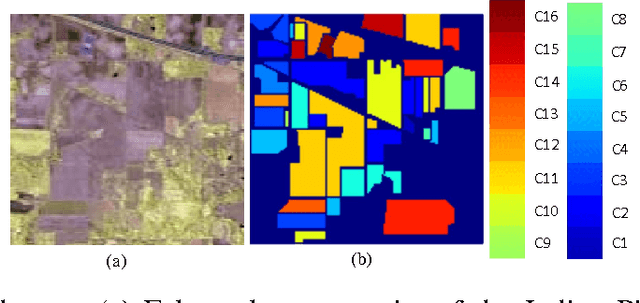
In this paper, we propose a multi-scale deep feature learning method for high-resolution satellite image classification. Specifically, we firstly warp the original satellite image into multiple different scales. The images in each scale are employed to train a deep convolutional neural network (DCNN). However, simultaneously training multiple DCNNs is time-consuming. To address this issue, we explore DCNN with spatial pyramid pooling (SPP-net). Since different SPP-nets have the same number of parameters, which share the identical initial values, and only fine-tuning the parameters in fully-connected layers ensures the effectiveness of each network, thereby greatly accelerating the training process. Then, the multi-scale satellite images are fed into their corresponding SPP-nets respectively to extract multi-scale deep features. Finally, a multiple kernel learning method is developed to automatically learn the optimal combination of such features. Experiments on two difficult datasets show that the proposed method achieves favorable performance compared to other state-of-the-art methods.
Adaptive Deep Pyramid Matching for Remote Sensing Scene Classification
Nov 11, 2016
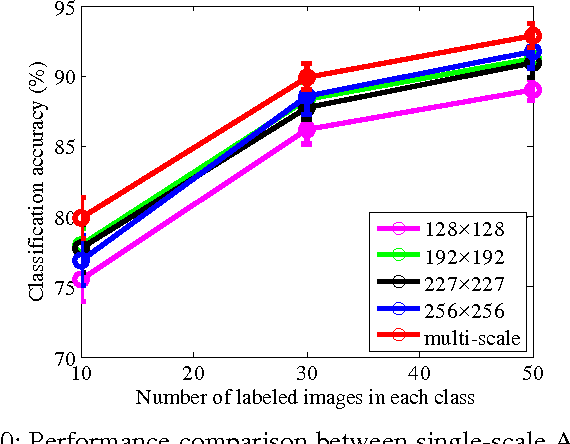
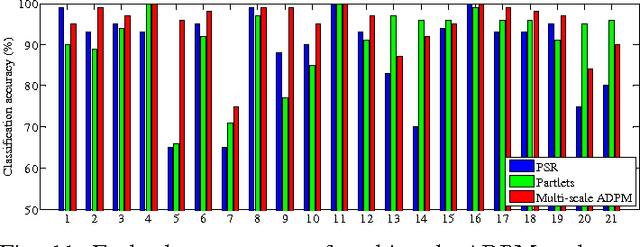

Convolutional neural networks (CNNs) have attracted increasing attention in the remote sensing community. Most CNNs only take the last fully-connected layers as features for the classification of remotely sensed images, discarding the other convolutional layer features which may also be helpful for classification purposes. In this paper, we propose a new adaptive deep pyramid matching (ADPM) model that takes advantage of the features from all of the convolutional layers for remote sensing image classification. To this end, the optimal fusing weights for different convolutional layers are learned from the data itself. In remotely sensed scenes, the objects of interest exhibit different scales in distinct scenes, and even a single scene may contain objects with different sizes. To address this issue, we select the CNN with spatial pyramid pooling (SPP-net) as the basic deep network, and further construct a multi-scale ADPM model to learn complementary information from multi-scale images. Our experiments have been conducted using two widely used remote sensing image databases, and the results show that the proposed method significantly improves the performance when compared to other state-of-the-art methods.
Graph Regularized Low Rank Representation for Aerosol Optical Depth Retrieval
Mar 07, 2016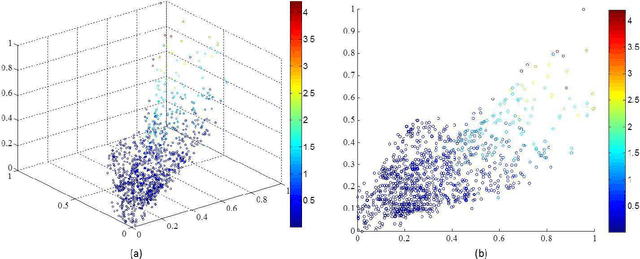
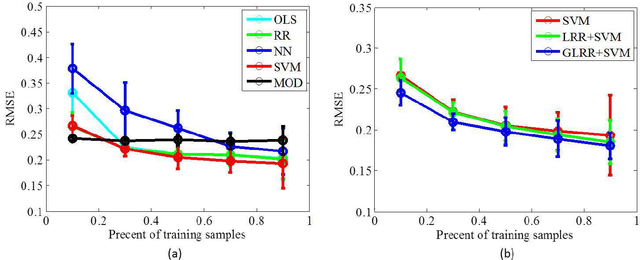
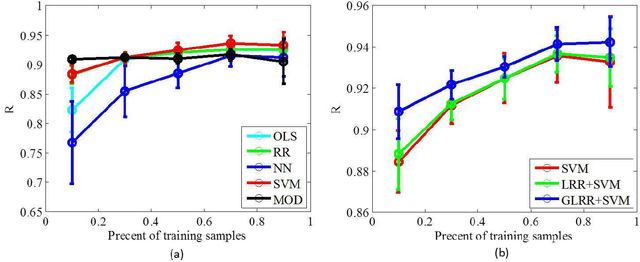
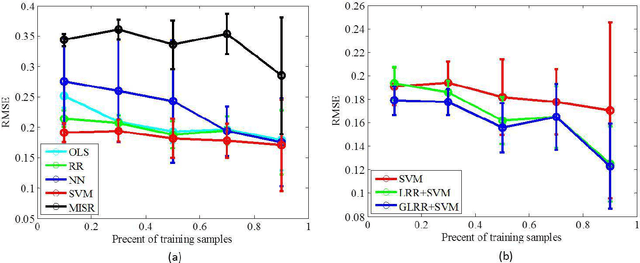
In this paper, we propose a novel data-driven regression model for aerosol optical depth (AOD) retrieval. First, we adopt a low rank representation (LRR) model to learn a powerful representation of the spectral response. Then, graph regularization is incorporated into the LRR model to capture the local structure information and the nonlinear property of the remote-sensing data. Since it is easy to acquire the rich satellite-retrieval results, we use them as a baseline to construct the graph. Finally, the learned feature representation is feeded into support vector machine (SVM) to retrieve AOD. Experiments are conducted on two widely used data sets acquired by different sensors, and the experimental results show that the proposed method can achieve superior performance compared to the physical models and other state-of-the-art empirical models.