 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-Hyperspectral Anomaly Detection: A First Study on Stealthy Lipschitz-Forcing Perturbations Against Unknown Detectors
Jun 03, 2026Hyperspectral imagery represents the best contemporary technology to remotely detect anomalous objects. Nevertheless, hyperspectral anomaly detection (HAD) technique makes ground facilities/situations completely exposed. For the first time, we develop the first anti-HAD (AHAD) technique rendering the key objects undetected, without perfect coordinate/position state information (CSI) of the detectors (e.g., reconnaissance aircraft). Our AHAD algorithm is generally applicable to defend against almost all the existing benchmark data-driven and model-driven HAD methods. AHAD is fundamentally different from conventional adversarial attacks, so novel theory is needed. We customize novel regularizers for assimilating real anomalies into the backgrounds (ARAB) and fooling the detectors with pseudo-anomalies, thereby optimizing an energy-efficient stealthy perturbation signal for AHAD. The ARAB regularization is mathematically interpretable as flattening the topology-enhanced anomaly/background structures in the feature space, hence termed Lipschitz-forcing perturbations. Considering the imperfect CSI, we further develop a robust AHAD criterion, where the uncertainty is mathematically described as matrix-shifting misalignment for statistically generating the robust perturbation. Comprehensive experiments demonstrate the effectiveness and robustness of our AHAD algorithm across diverse real-world datasets. Remarkably, our algorithm generates a single AHAD perturbation signal that can simultaneously evade almost all benchmark detectors, greatly enhancing its practicality, given that the reconnaissance detector type is usually unknown. To the best of our knowledge, this is the first formal AHAD study. As a side contribution, we propose a new quantitative performance index, ArmCBA, to evaluate the robustness of an HAD method against our AHAD signal.
Hyperspectral Imaging
Aug 11, 2025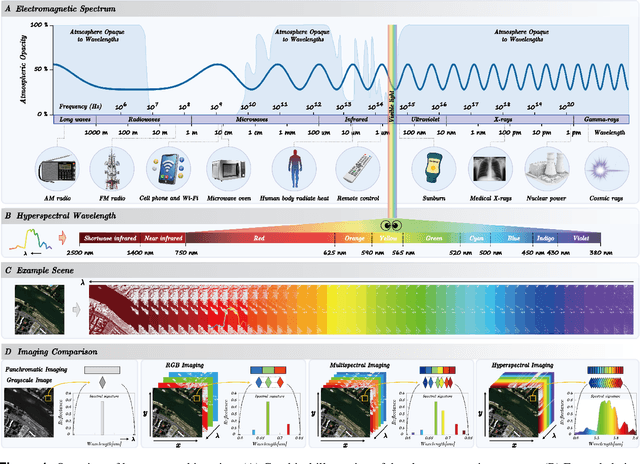
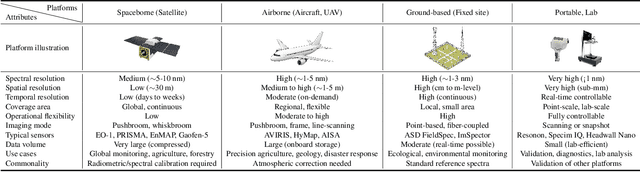
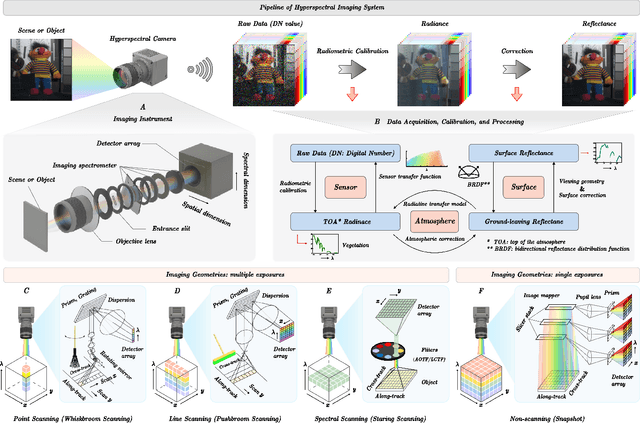

Hyperspectral imaging (HSI) is an advanced sensing modality that simultaneously captures spatial and spectral information, enabling non-invasive, label-free analysis of material, chemical, and biological properties. This Primer presents a comprehensive overview of HSI, from the underlying physical principles and sensor architectures to key steps in data acquisition, calibration, and correction. We summarize common data structures and highlight classical and modern analysis methods, including dimensionality reduction, classification, spectral unmixing, and AI-driven techniques such as deep learning. Representative applications across Earth observation, precision agriculture, biomedicine, industrial inspection, cultural heritage, and security are also discussed, emphasizing HSI's ability to uncover sub-visual features for advanced monitoring, diagnostics, and decision-making. Persistent challenges, such as hardware trade-offs, acquisition variability, and the complexity of high-dimensional data, are examined alongside emerging solutions, including computational imaging, physics-informed modeling, cross-modal fusion, and self-supervised learning. Best practices for dataset sharing, reproducibility, and metadata documentation are further highlighted to support transparency and reuse. Looking ahead, we explore future directions toward scalable, real-time, and embedded HSI systems, driven by sensor miniaturization, self-supervised learning, and foundation models. As HSI evolves into a general-purpose, cross-disciplinary platform, it holds promise for transformative applications in science, technology, and society.
Effective Motion Modeling for UAV-platform Multiple Object Tracking with Re-Margin Loss
Jul 15, 2024

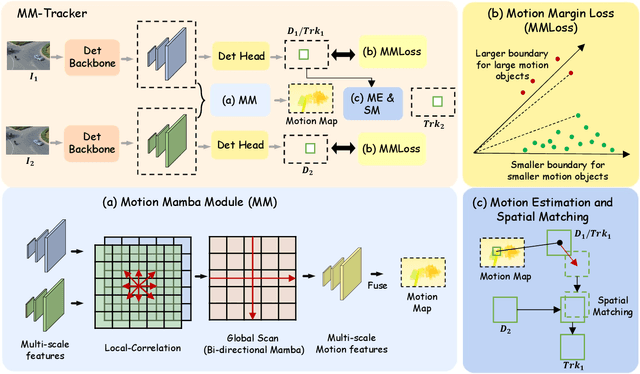
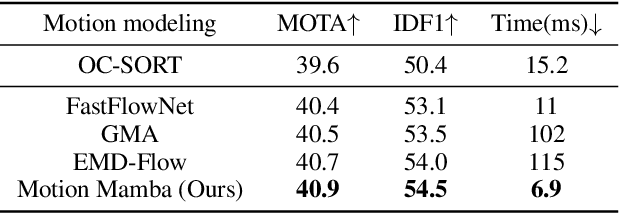
Multiple object tracking (MOT) from unmanned aerial vehicle (UAV) platforms requires efficient motion modeling. This is because UAV-MOT faces tracking difficulties caused by large and irregular motion, and insufficient training due to the motion long-tailed distribution of current UAV-MOT datasets. Previous UAV-MOT methods either extract motion and detection features redundantly or supervise motion model in a sparse scheme, which limited their tracking performance and speed. To this end, we propose a flowing-by-detection module to realize accurate motion modeling with a minimum cost. Focusing on the motion long-tailed problem that were ignored by previous works, the flow-guided margin loss is designed to enable more complete training of large moving objects. Experiments on two widely open-source datasets show that our proposed model can successfully track objects with large and irregular motion and outperform existing state-of-the-art methods in UAV-MOT tasks.
SpectralGPT: Spectral Foundation Model
Nov 25, 2023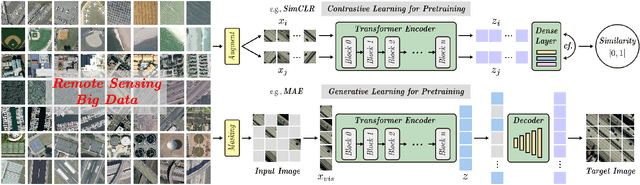

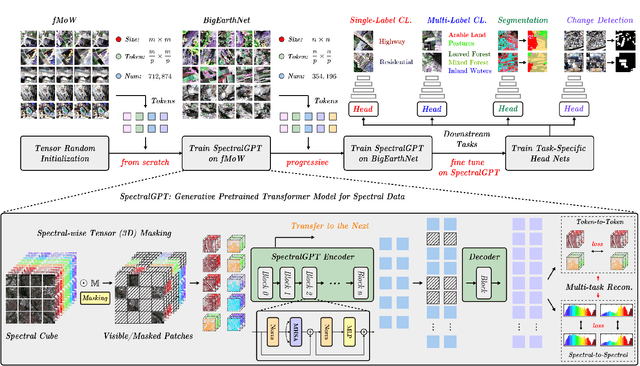
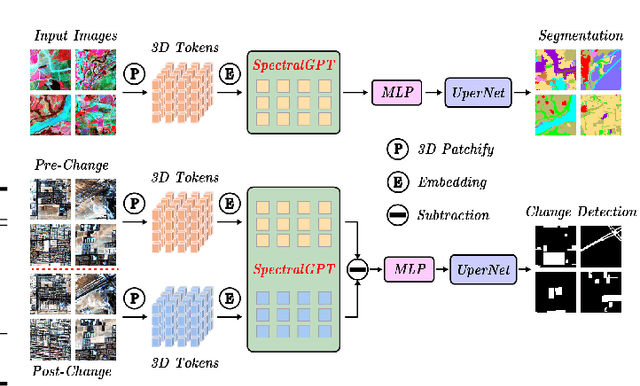
The foundation model has recently garnered significant attention due to its potential to revolutionize the field of visual representation learning in a self-supervised manner. While most foundation models are tailored to effectively process RGB images for various visual tasks, there is a noticeable gap in research focused on spectral data, which offers valuable information for scene understanding, especially in remote sensing (RS) applications. To fill this gap, we created for the first time a universal RS foundation model, named SpectralGPT, which is purpose-built to handle spectral RS images using a novel 3D generative pretrained transformer (GPT). Compared to existing foundation models, SpectralGPT 1) accommodates input images with varying sizes, resolutions, time series, and regions in a progressive training fashion, enabling full utilization of extensive RS big data; 2) leverages 3D token generation for spatial-spectral coupling; 3) captures spectrally sequential patterns via multi-target reconstruction; 4) trains on one million spectral RS images, yielding models with over 600 million parameters. Our evaluation highlights significant performance improvements with pretrained SpectralGPT models, signifying substantial potential in advancing spectral RS big data applications within the field of geoscience across four downstream tasks: single/multi-label scene classification, semantic segmentation, and change detection.
Feature Extraction for Hyperspectral Imagery: The Evolution from Shallow to Deep
Mar 06, 2020
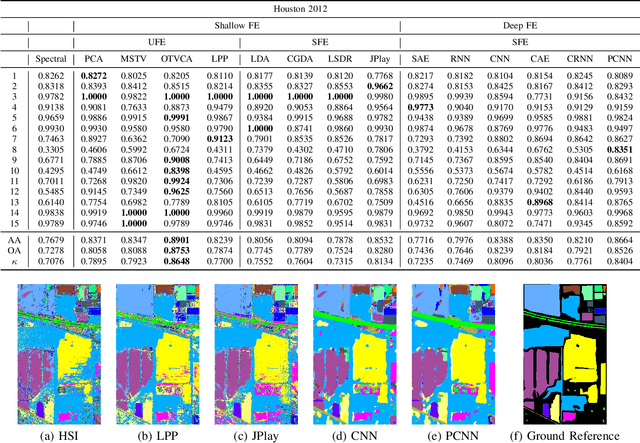
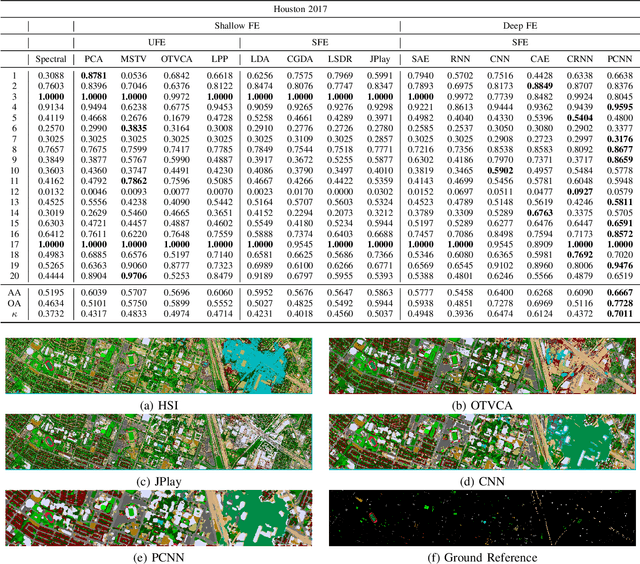

Hyperspectral images provide detailed spectral information through hundreds of (narrow) spectral channels (also known as dimensionality or bands) with continuous spectral information that can accurately classify diverse materials of interest. The increased dimensionality of such data makes it possible to significantly improve data information content but provides a challenge to the conventional techniques (the so-called curse of dimensionality) for accurate analysis of hyperspectral images. Feature extraction, as a vibrant field of research in the hyperspectral community, evolved through decades of research to address this issue and extract informative features suitable for data representation and classification. The advances in feature extraction have been inspired by two fields of research, including the popularization of image and signal processing as well as machine (deep) learning, leading to two types of feature extraction approaches named shallow and deep techniques. This article outlines the advances in feature extraction approaches for hyperspectral imagery by providing a technical overview of the state-of-the-art techniques, providing useful entry points for researchers at different levels, including students, researchers, and senior researchers, willing to explore novel investigations on this challenging topic. In more detail, this paper provides a bird's eye view over shallow (both supervised and unsupervised) and deep feature extraction approaches specifically dedicated to the topic of hyperspectral feature extraction and its application on hyperspectral image classification. Additionally, this paper compares 15 advanced techniques with an emphasis on their methodological foundations in terms of classification accuracies. Furthermore, the codes and libraries are shared at https://github.com/BehnoodRasti/HyFTech-Hyperspectral-Shallow-Deep-Feature-Extraction-Toolbox.
Deep Hashing Learning for Visual and Semantic Retrieval of Remote Sensing Images
Sep 10, 2019
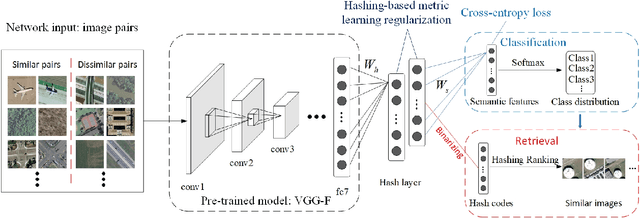


Driven by the urgent demand for managing remote sensing big data, large-scale remote sensing image retrieval (RSIR) attracts increasing attention in the remote sensing field. In general, existing retrieval methods can be regarded as visual-based retrieval approaches which search and return a set of similar images from a database to a given query image. Although retrieval methods have achieved great success, there is still a question that needs to be responded to: Can we obtain the accurate semantic labels of the returned similar images to further help analyzing and processing imagery? Inspired by the above question, in this paper, we redefine the image retrieval problem as visual and semantic retrieval of images. Specifically, we propose a novel deep hashing convolutional neural network (DHCNN) to simultaneously retrieve the similar images and classify their semantic labels in a unified framework. In more detail, a convolutional neural network (CNN) is used to extract high-dimensional deep features. Then, a hash layer is perfectly inserted into the network to transfer the deep features into compact hash codes. In addition, a fully connected layer with a softmax function is performed on hash layer to generate class distribution. Finally, a loss function is elaborately designed to simultaneously consider the label loss of each image and similarity loss of pairs of images. Experimental results on two remote sensing datasets demonstrate that the proposed method achieves the state-of-art retrieval and classification performance.
Multisource and Multitemporal Data Fusion in Remote Sensing
Dec 19, 2018
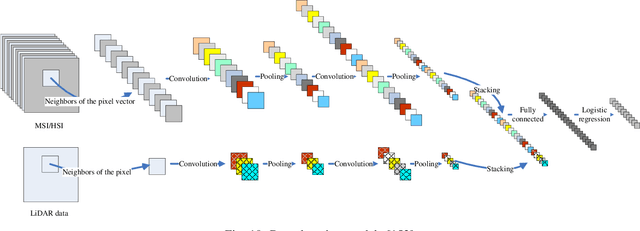
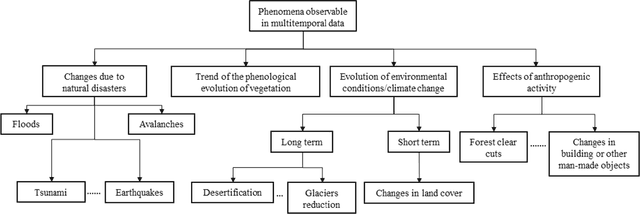
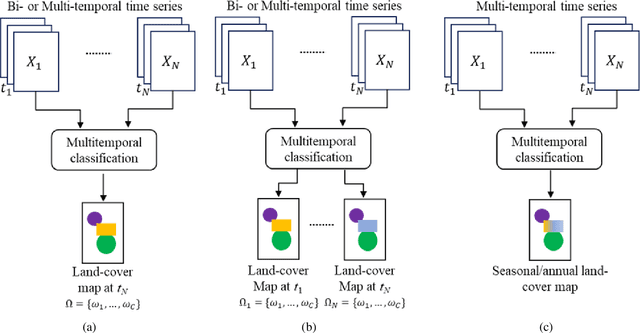
The sharp and recent increase in the availability of data captured by different sensors combined with their considerably heterogeneous natures poses a serious challenge for the effective and efficient processing of remotely sensed data. Such an increase in remote sensing and ancillary datasets, however, opens up the possibility of utilizing multimodal datasets in a joint manner to further improve the performance of the processing approaches with respect to the application at hand. Multisource data fusion has, therefore, received enormous attention from researchers worldwide for a wide variety of applications. Moreover, thanks to the revisit capability of several spaceborne sensors, the integration of the temporal information with the spatial and/or spectral/backscattering information of the remotely sensed data is possible and helps to move from a representation of 2D/3D data to 4D data structures, where the time variable adds new information as well as challenges for the information extraction algorithms. There are a huge number of research works dedicated to multisource and multitemporal data fusion, but the methods for the fusion of different modalities have expanded in different paths according to each research community. This paper brings together the advances of multisource and multitemporal data fusion approaches with respect to different research communities and provides a thorough and discipline-specific starting point for researchers at different levels (i.e., students, researchers, and senior researchers) willing to conduct novel investigations on this challenging topic by supplying sufficient detail and references.
Integration of LiDAR and Hyperspectral Data for Land-cover Classification: A Case Study
Jul 09, 2017



In this paper, an approach is proposed to fuse LiDAR and hyperspectral data, which considers both spectral and spatial information in a single framework. Here, an extended self-dual attribute profile (ESDAP) is investigated to extract spatial information from a hyperspectral data set. To extract spectral information, a few well-known classifiers have been used such as support vector machines (SVMs), random forests (RFs), and artificial neural networks (ANNs). The proposed method accurately classify the relatively volumetric data set in a few CPU processing time in a real ill-posed situation where there is no balance between the number of training samples and the number of features. The classification part of the proposed approach is fully-automatic.