 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Imaging
Aug 11, 2025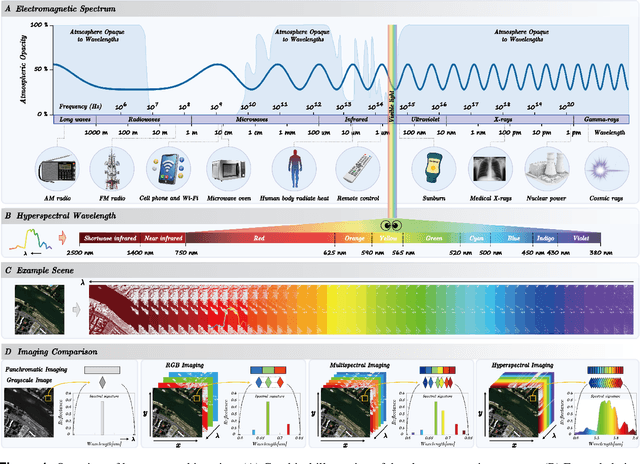
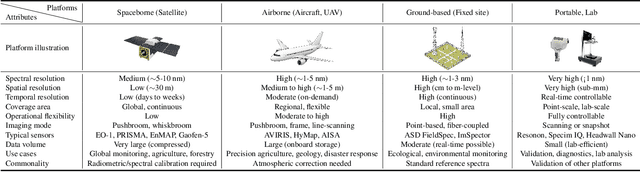
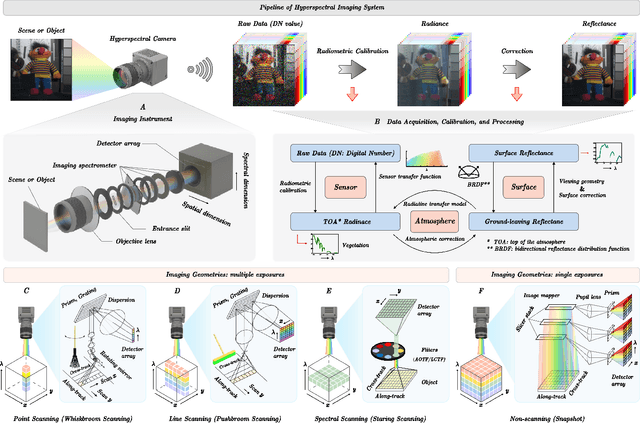

Hyperspectral imaging (HSI) is an advanced sensing modality that simultaneously captures spatial and spectral information, enabling non-invasive, label-free analysis of material, chemical, and biological properties. This Primer presents a comprehensive overview of HSI, from the underlying physical principles and sensor architectures to key steps in data acquisition, calibration, and correction. We summarize common data structures and highlight classical and modern analysis methods, including dimensionality reduction, classification, spectral unmixing, and AI-driven techniques such as deep learning. Representative applications across Earth observation, precision agriculture, biomedicine, industrial inspection, cultural heritage, and security are also discussed, emphasizing HSI's ability to uncover sub-visual features for advanced monitoring, diagnostics, and decision-making. Persistent challenges, such as hardware trade-offs, acquisition variability, and the complexity of high-dimensional data, are examined alongside emerging solutions, including computational imaging, physics-informed modeling, cross-modal fusion, and self-supervised learning. Best practices for dataset sharing, reproducibility, and metadata documentation are further highlighted to support transparency and reuse. Looking ahead, we explore future directions toward scalable, real-time, and embedded HSI systems, driven by sensor miniaturization, self-supervised learning, and foundation models. As HSI evolves into a general-purpose, cross-disciplinary platform, it holds promise for transformative applications in science, technology, and society.
S$^2$Mamba: A Spatial-spectral State Space Model for Hyperspectral Image Classification
Apr 28, 2024



Land cover analysis using hyperspectral images (HSI) remains an open problem due to their low spatial resolution and complex spectral information. Recent studies are primarily dedicated to designing Transformer-based architectures for spatial-spectral long-range dependencies modeling, which is computationally expensive with quadratic complexity. Selective structured state space model (Mamba), which is efficient for modeling long-range dependencies with linear complexity, has recently shown promising progress. However, its potential in hyperspectral image processing that requires handling numerous spectral bands has not yet been explored. In this paper, we innovatively propose S$^2$Mamba, a spatial-spectral state space model for hyperspectral image classification, to excavate spatial-spectral contextual features, resulting in more efficient and accurate land cover analysis. In S$^2$Mamba, two selective structured state space models through different dimensions are designed for feature extraction, one for spatial, and the other for spectral, along with a spatial-spectral mixture gate for optimal fusion. More specifically, S$^2$Mamba first captures spatial contextual relations by interacting each pixel with its adjacent through a Patch Cross Scanning module and then explores semantic information from continuous spectral bands through a Bi-directional Spectral Scanning module. Considering the distinct expertise of the two attributes in homogenous and complicated texture scenes, we realize the Spatial-spectral Mixture Gate by a group of learnable matrices, allowing for the adaptive incorporation of representations learned across different dimensions. Extensive experiments conducted on HSI classification benchmarks demonstrate the superiority and prospect of S$^2$Mamba. The code will be available at: https://github.com/PURE-melo/S2Mamba.
SpectralGPT: Spectral Foundation Model
Nov 25, 2023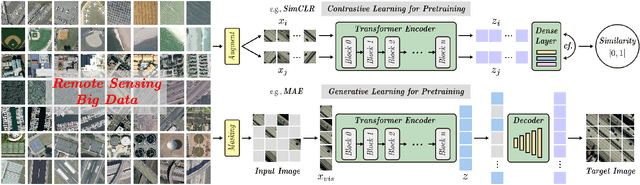

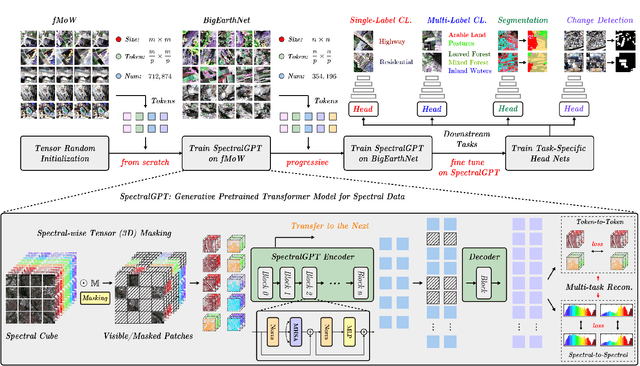
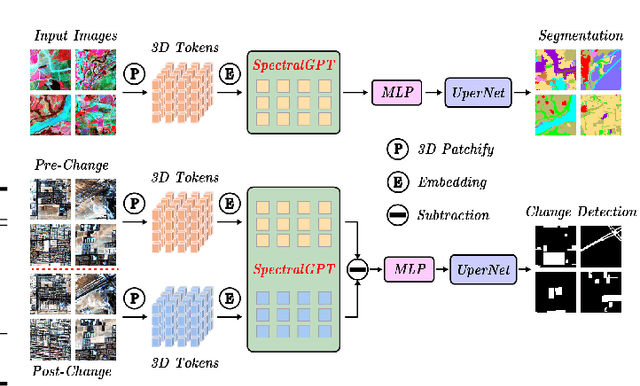
The foundation model has recently garnered significant attention due to its potential to revolutionize the field of visual representation learning in a self-supervised manner. While most foundation models are tailored to effectively process RGB images for various visual tasks, there is a noticeable gap in research focused on spectral data, which offers valuable information for scene understanding, especially in remote sensing (RS) applications. To fill this gap, we created for the first time a universal RS foundation model, named SpectralGPT, which is purpose-built to handle spectral RS images using a novel 3D generative pretrained transformer (GPT). Compared to existing foundation models, SpectralGPT 1) accommodates input images with varying sizes, resolutions, time series, and regions in a progressive training fashion, enabling full utilization of extensive RS big data; 2) leverages 3D token generation for spatial-spectral coupling; 3) captures spectrally sequential patterns via multi-target reconstruction; 4) trains on one million spectral RS images, yielding models with over 600 million parameters. Our evaluation highlights significant performance improvements with pretrained SpectralGPT models, signifying substantial potential in advancing spectral RS big data applications within the field of geoscience across four downstream tasks: single/multi-label scene classification, semantic segmentation, and change detection.
Remote Sensing Object Detection Meets Deep Learning: A Meta-review of Challenges and Advances
Sep 13, 2023



Remote sensing object detection (RSOD), one of the most fundamental and challenging tasks in the remote sensing field, has received longstanding attention. In recent years, deep learning techniques have demonstrated robust feature representation capabilities and led to a big leap in the development of RSOD techniques. In this era of rapid technical evolution, this review aims to present a comprehensive review of the recent achievements in deep learning based RSOD methods. More than 300 papers are covered in this review. We identify five main challenges in RSOD, including multi-scale object detection, rotated object detection, weak object detection, tiny object detection, and object detection with limited supervision, and systematically review the corresponding methods developed in a hierarchical division manner. We also review the widely used benchmark datasets and evaluation metrics within the field of RSOD, as well as the application scenarios for RSOD. Future research directions are provided for further promoting the research in RSOD.
Guided Hybrid Quantization for Object detection in Multimodal Remote Sensing Imagery via One-to-one Self-teaching
Dec 31, 2022
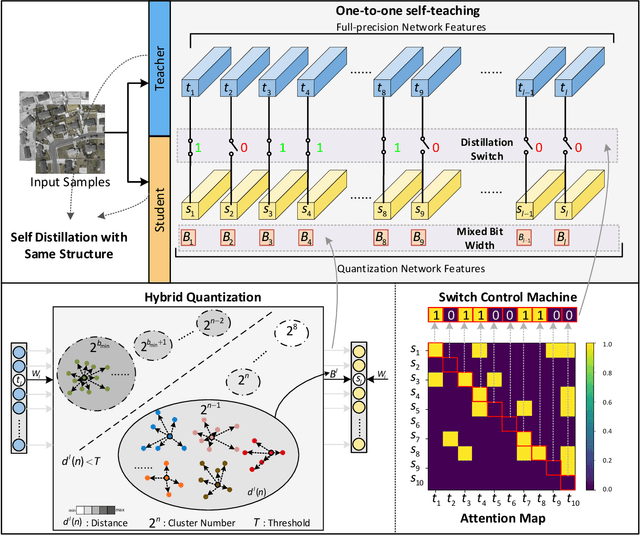
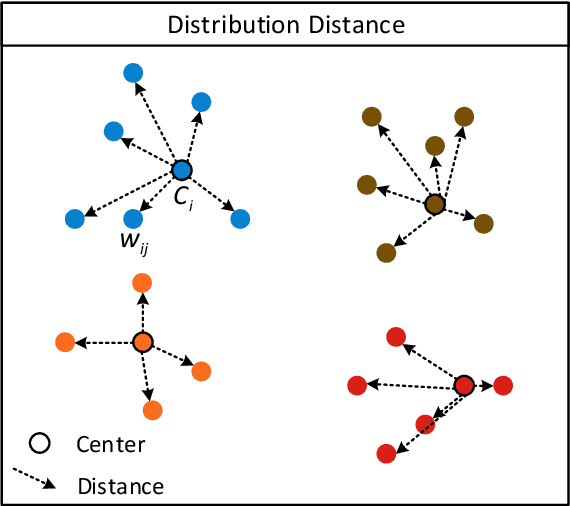
Considering the computation complexity, we propose a Guided Hybrid Quantization with One-to-one Self-Teaching (GHOST}) framework. More concretely, we first design a structure called guided quantization self-distillation (GQSD), which is an innovative idea for realizing lightweight through the synergy of quantization and distillation. The training process of the quantization model is guided by its full-precision model, which is time-saving and cost-saving without preparing a huge pre-trained model in advance. Second, we put forward a hybrid quantization (HQ) module to obtain the optimal bit width automatically under a constrained condition where a threshold for distribution distance between the center and samples is applied in the weight value search space. Third, in order to improve information transformation, we propose a one-to-one self-teaching (OST) module to give the student network a ability of self-judgment. A switch control machine (SCM) builds a bridge between the student network and teacher network in the same location to help the teacher to reduce wrong guidance and impart vital knowledge to the student. This distillation method allows a model to learn from itself and gain substantial improvement without any additional supervision. Extensive experiments on a multimodal dataset (VEDAI) and single-modality datasets (DOTA, NWPU, and DIOR) show that object detection based on GHOST outperforms the existing detectors. The tiny parameters (<9.7 MB) and Bit-Operations (BOPs) (<2158 G) compared with any remote sensing-based, lightweight or distillation-based algorithms demonstrate the superiority in the lightweight design domain. Our code and model will be released at https://github.com/icey-zhang/GHOST.
Pair-Relationship Modeling for Latent Fingerprint Recognition
Jul 02, 2022
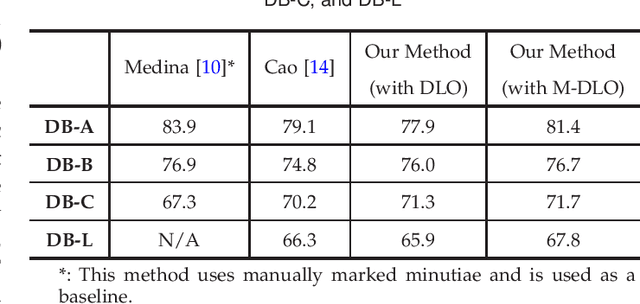
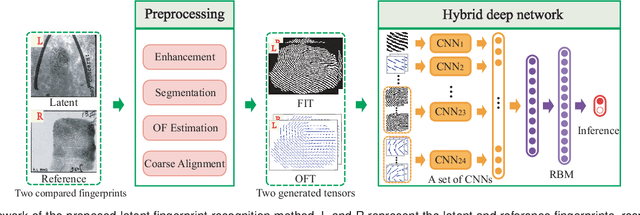
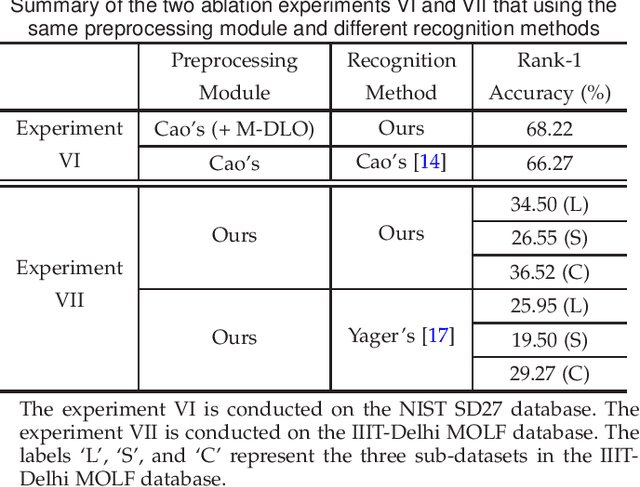
Latent fingerprints are important for identifying criminal suspects. However, recognizing a latent fingerprint in a collection of reference fingerprints remains a challenge. Most, if not all, of existing methods would extract representation features of each fingerprint independently and then compare the similarity of these representation features for recognition in a different process. Without the supervision of similarity for the feature extraction process, the extracted representation features are hard to optimally reflect the similarity of the two compared fingerprints which is the base for matching decision making. In this paper, we propose a new scheme that can model the pair-relationship of two fingerprints directly as the similarity feature for recognition. The pair-relationship is modeled by a hybrid deep network which can handle the difficulties of random sizes and corrupted areas of latent fingerprints. Experimental results on two databases show that the proposed method outperforms the state of the art.
Hyperspectral Unmixing Based on Nonnegative Matrix Factorization: A Comprehensive Review
May 20, 2022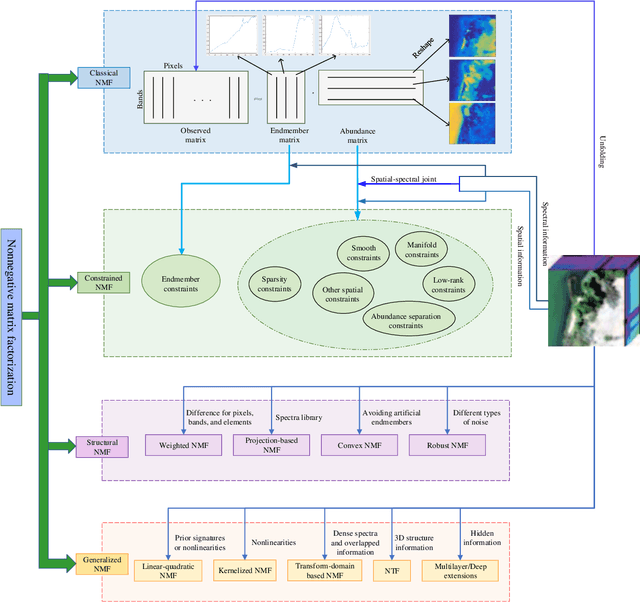
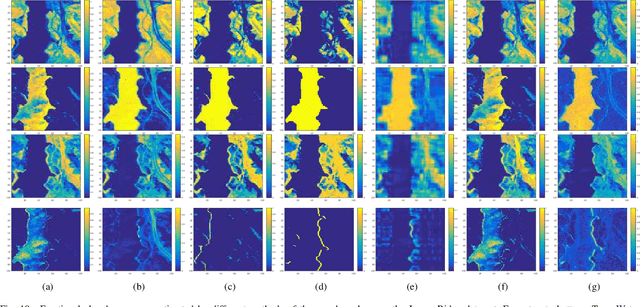
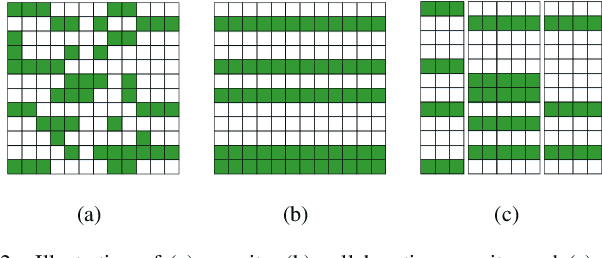
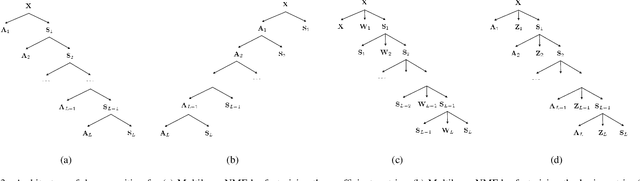
Hyperspectral unmixing has been an important technique that estimates a set of endmembers and their corresponding abundances from a hyperspectral image (HSI). Nonnegative matrix factorization (NMF) plays an increasingly significant role in solving this problem. In this article, we present a comprehensive survey of the NMF-based methods proposed for hyperspectral unmixing. Taking the NMF model as a baseline, we show how to improve NMF by utilizing the main properties of HSIs (e.g., spectral, spatial, and structural information). We categorize three important development directions including constrained NMF, structured NMF, and generalized NMF. Furthermore, several experiments are conducted to illustrate the effectiveness of associated algorithms. Finally, we conclude the article with possible future directions with the purposes of providing guidelines and inspiration to promote the development of hyperspectral unmixing.
Dual-Stage Approach Toward Hyperspectral Image Super-Resolution
Apr 09, 2022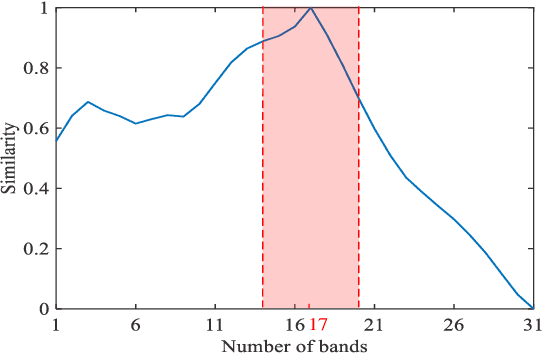


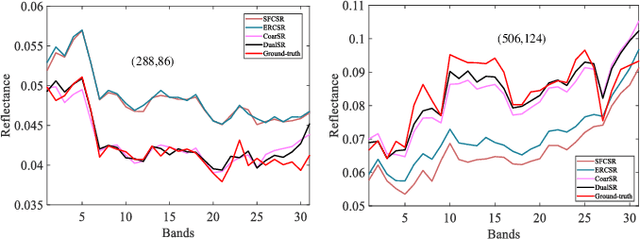
Hyperspectral image produces high spectral resolution at the sacrifice of spatial resolution. Without reducing the spectral resolution, improving the resolution in the spatial domain is a very challenging problem. Motivated by the discovery that hyperspectral image exhibits high similarity between adjacent bands in a large spectral range, in this paper, we explore a new structure for hyperspectral image super-resolution (DualSR), leading to a dual-stage design, i.e., coarse stage and fine stage. In coarse stage, five bands with high similarity in a certain spectral range are divided into three groups, and the current band is guided to study the potential knowledge. Under the action of alternative spectral fusion mechanism, the coarse SR image is super-resolved in band-by-band. In order to build model from a global perspective, an enhanced back-projection method via spectral angle constraint is developed in fine stage to learn the content of spatial-spectral consistency, dramatically improving the performance gain. Extensive experiments demonstrate the effectiveness of the proposed coarse stage and fine stage. Besides, our network produces state-of-the-art results against existing works in terms of spatial reconstruction and spectral fidelity.
Multi-Attention Generative Adversarial Network for Remote Sensing Image Super-Resolution
Jul 14, 2021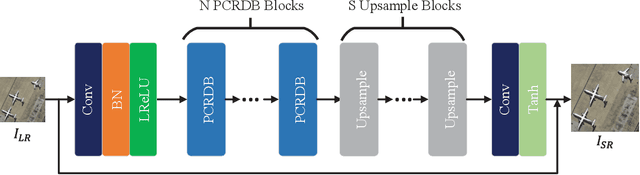
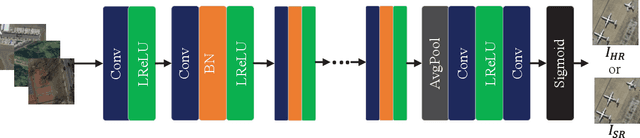
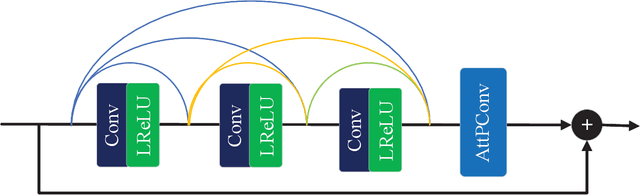
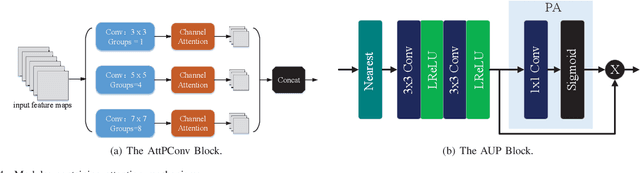
Image super-resolution (SR) methods can generate remote sensing images with high spatial resolution without increasing the cost, thereby providing a feasible way to acquire high-resolution remote sensing images, which are difficult to obtain due to the high cost of acquisition equipment and complex weather. Clearly, image super-resolution is a severe ill-posed problem. Fortunately, with the development of deep learning, the powerful fitting ability of deep neural networks has solved this problem to some extent. In this paper, we propose a network based on the generative adversarial network (GAN) to generate high resolution remote sensing images, named the multi-attention generative adversarial network (MA-GAN). We first designed a GAN-based framework for the image SR task. The core to accomplishing the SR task is the image generator with post-upsampling that we designed. The main body of the generator contains two blocks; one is the pyramidal convolution in the residual-dense block (PCRDB), and the other is the attention-based upsample (AUP) block. The attentioned pyramidal convolution (AttPConv) in the PCRDB block is a module that combines multi-scale convolution and channel attention to automatically learn and adjust the scaling of the residuals for better results. The AUP block is a module that combines pixel attention (PA) to perform arbitrary multiples of upsampling. These two blocks work together to help generate better quality images. For the loss function, we design a loss function based on pixel loss and introduce both adversarial loss and feature loss to guide the generator learning. We have compared our method with several state-of-the-art methods on a remote sensing scene image dataset, and the experimental results consistently demonstrate the effectiveness of the proposed MA-GAN.
An Attention-Fused Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery
May 28, 2021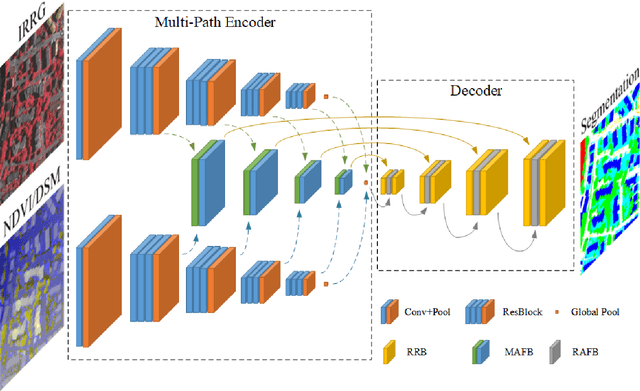
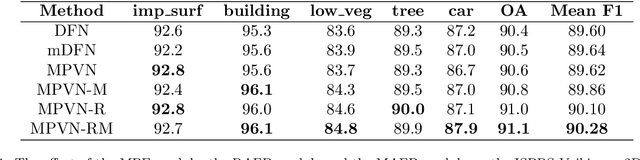
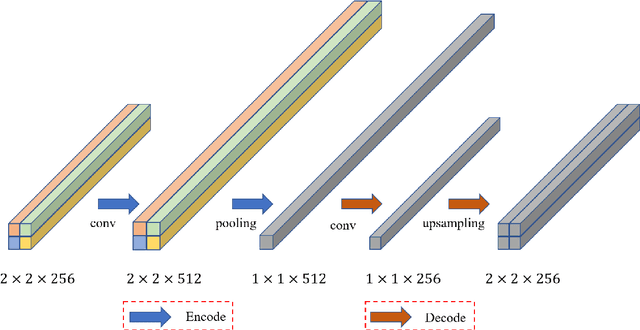
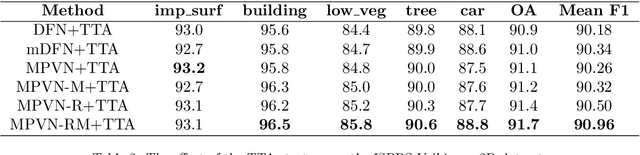
Semantic segmentation is an essential part of deep learning. In recent years, with the development of remote sensing big data, semantic segmentation has been increasingly used in remote sensing. Deep convolutional neural networks (DCNNs) face the challenge of feature fusion: very-high-resolution remote sensing image multisource data fusion can increase the network's learnable information, which is conducive to correctly classifying target objects by DCNNs; simultaneously, the fusion of high-level abstract features and low-level spatial features can improve the classification accuracy at the border between target objects. In this paper, we propose a multipath encoder structure to extract features of multipath inputs, a multipath attention-fused block module to fuse multipath features, and a refinement attention-fused block module to fuse high-level abstract features and low-level spatial features. Furthermore, we propose a novel convolutional neural network architecture, named attention-fused network (AFNet). Based on our AFNet, we achieve state-of-the-art performance with an overall accuracy of 91.7% and a mean F1 score of 90.96% on the ISPRS Vaihingen 2D dataset and an overall accuracy of 92.1% and a mean F1 score of 93.44% on the ISPRS Potsdam 2D dataset.
* 35 pages. Published by ISPRS Journal of Photogrammetry and Remote Sensing