 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robust Policy Bootstrapping Algorithm for Multi-objective Reinforcement Learning in Non-stationary Environments
Aug 18, 2023



Multi-objective Markov decision processes are a special kind of multi-objective optimization problem that involves sequential decision making while satisfying the Markov property of stochastic processes. Multi-objective reinforcement learning methods address this problem by fusing the reinforcement learning paradigm with multi-objective optimization techniques. One major drawback of these methods is the lack of adaptability to non-stationary dynamics in the environment. This is because they adopt optimization procedures that assume stationarity to evolve a coverage set of policies that can solve the problem. This paper introduces a developmental optimization approach that can evolve the policy coverage set while exploring the preference space over the defined objectives in an online manner. We propose a novel multi-objective reinforcement learning algorithm that can robustly evolve a convex coverage set of policies in an online manner in non-stationary environments. We compare the proposed algorithm with two state-of-the-art multi-objective reinforcement learning algorithms in stationary and non-stationary environments. Results showed that the proposed algorithm significantly outperforms the existing algorithms in non-stationary environments while achieving comparable results in stationary environments.
Intrinsically Motivated Hierarchical Policy Learning in Multi-objective Markov Decision Processes
Aug 18, 2023



Multi-objective Markov decision processes are sequential decision-making problems that involve multiple conflicting reward functions that cannot be optimized simultaneously without a compromise. This type of problems cannot be solved by a single optimal policy as in the conventional case. Alternatively, multi-objective reinforcement learning methods evolve a coverage set of optimal policies that can satisfy all possible preferences in solving the problem. However, many of these methods cannot generalize their coverage sets to work in non-stationary environments. In these environments, the parameters of the state transition and reward distribution vary over time. This limitation results in significant performance degradation for the evolved policy sets. In order to overcome this limitation, there is a need to learn a generic skill set that can bootstrap the evolution of the policy coverage set for each shift in the environment dynamics therefore, it can facilitate a continuous learning process. In this work, intrinsically motivated reinforcement learning has been successfully deployed to evolve generic skill sets for learning hierarchical policies to solve multi-objective Markov decision processes. We propose a novel dual-phase intrinsically motivated reinforcement learning method to address this limitation. In the first phase, a generic set of skills is learned. While in the second phase, this set is used to bootstrap policy coverage sets for each shift in the environment dynamics. We show experimentally that the proposed method significantly outperforms state-of-the-art multi-objective reinforcement methods in a dynamic robotics environment.
PowerFDNet: Deep Learning-Based Stealthy False Data Injection Attack Detection for AC-model Transmission Systems
Jul 15, 2022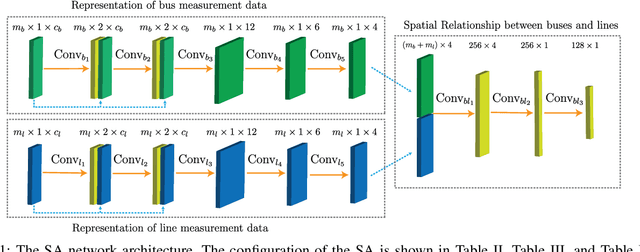
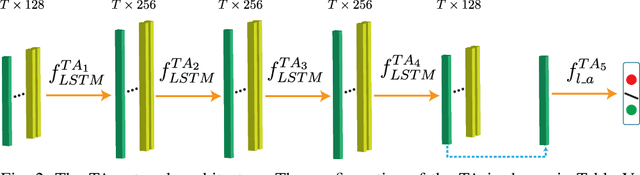
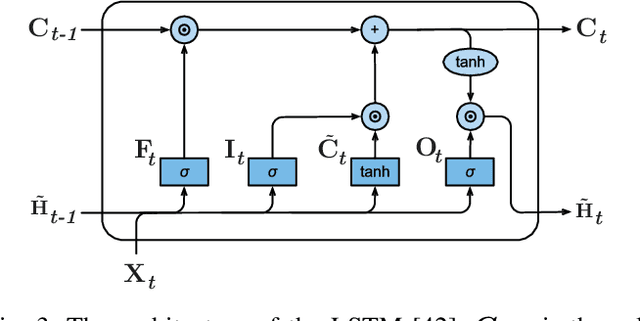
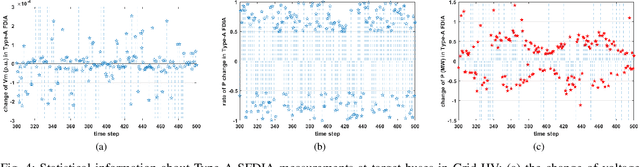
Recent studies have demonstrated that smart grids are vulnerable to stealthy false data injection attacks (SFDIAs), as SFDIAs can bypass residual-based bad data detection mechanisms. The SFDIA detection has become one of the focuses of smart grid research. Methods based on deep learning technology have shown promising accuracy in the detection of SFDIAs. However, most existing methods rely on the temporal structure of a sequence of measurements but do not take account of the spatial structure between buses and transmission lines. To address this issue, we propose a spatiotemporal deep network, PowerFDNet, for the SFDIA detection in AC-model power grids. The PowerFDNet consists of two sub-architectures: spatial architecture (SA) and temporal architecture (TA). The SA is aimed at extracting representations of bus/line measurements and modeling the spatial structure based on their representations. The TA is aimed at modeling the temporal structure of a sequence of measurements. Therefore, the proposed PowerFDNet can effectively model the spatiotemporal structure of measurements. Case studies on the detection of SFDIAs on the benchmark smart grids show that the PowerFDNet achieved significant improvement compared with the state-of-the-art SFDIA detection methods. In addition, an IoT-oriented lightweight prototype of size 52 MB is implemented and tested for mobile devices, which demonstrates the potential applications on mobile devices. The trained model will be available at \textit{https://github.com/FrankYinXF/PowerFDNet}.
Pair-Relationship Modeling for Latent Fingerprint Recognition
Jul 02, 2022
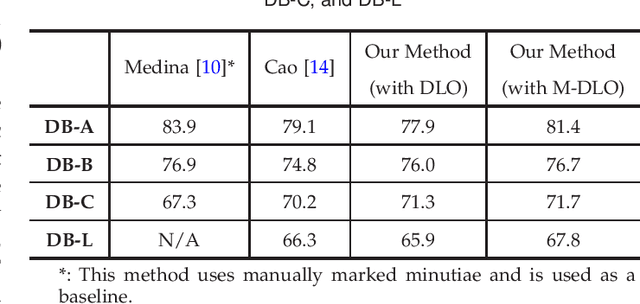
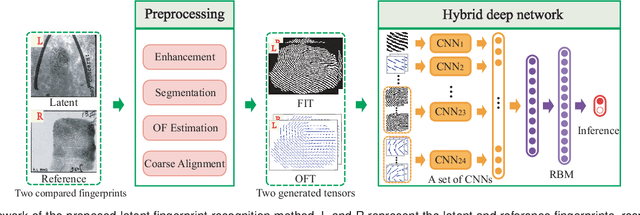
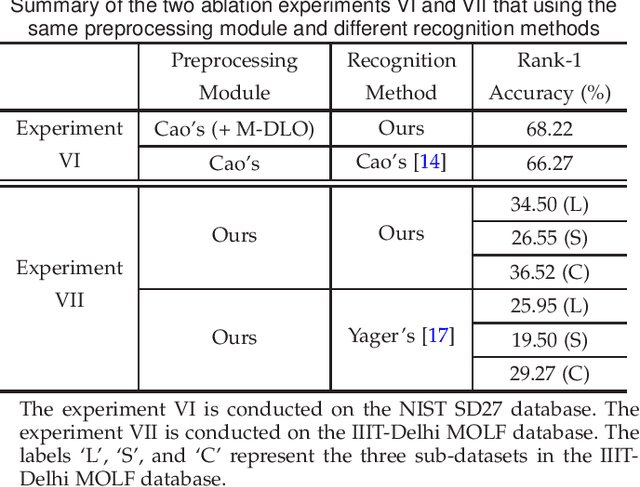
Latent fingerprints are important for identifying criminal suspects. However, recognizing a latent fingerprint in a collection of reference fingerprints remains a challenge. Most, if not all, of existing methods would extract representation features of each fingerprint independently and then compare the similarity of these representation features for recognition in a different process. Without the supervision of similarity for the feature extraction process, the extracted representation features are hard to optimally reflect the similarity of the two compared fingerprints which is the base for matching decision making. In this paper, we propose a new scheme that can model the pair-relationship of two fingerprints directly as the similarity feature for recognition. The pair-relationship is modeled by a hybrid deep network which can handle the difficulties of random sizes and corrupted areas of latent fingerprints. Experimental results on two databases show that the proposed method outperforms the state of the art.
FingerGAN: A Constrained Fingerprint Generation Scheme for Latent Fingerprint Enhancement
Jun 26, 2022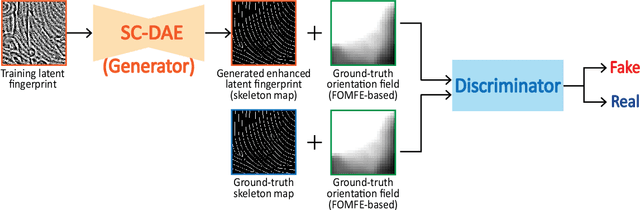
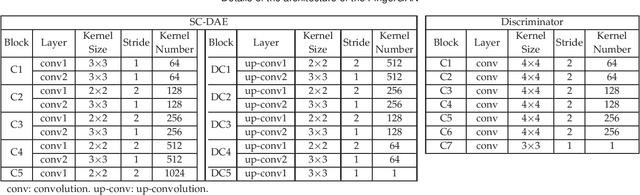
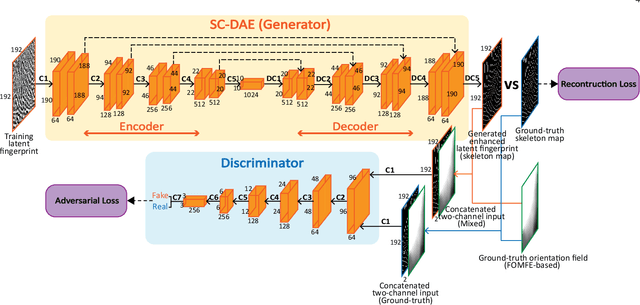
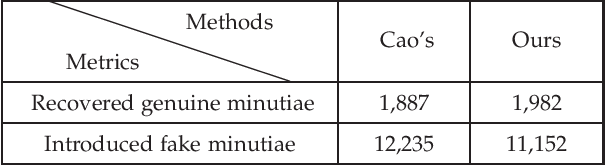
Latent fingerprint enhancement is an essential pre-processing step for latent fingerprint identification. Most latent fingerprint enhancement methods try to restore corrupted gray ridges/valleys. In this paper, we propose a new method that formulates the latent fingerprint enhancement as a constrained fingerprint generation problem within a generative adversarial network (GAN) framework. We name the proposed network as FingerGAN. It can enforce its generated fingerprint (i.e, enhanced latent fingerprint) indistinguishable from the corresponding ground-truth instance in terms of the fingerprint skeleton map weighted by minutia locations and the orientation field regularized by the FOMFE model. Because minutia is the primary feature for fingerprint recognition and minutia can be retrieved directly from the fingerprint skeleton map, we offer a holistic framework which can perform latent fingerprint enhancement in the context of directly optimizing minutia information. This will help improve latent fingerprint identification performance significantly. Experimental results on two public latent fingerprint databases demonstrate that our method outperforms the state of the arts significantly. The codes will be available for non-commercial purposes from \url{https://github.com/HubYZ/LatentEnhancement}.
Towards Multi-Scale Speaking Style Modelling with Hierarchical Context Information for Mandarin Speech Synthesis
Apr 06, 2022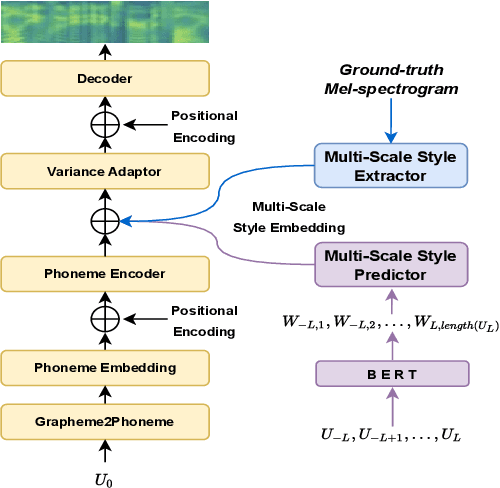
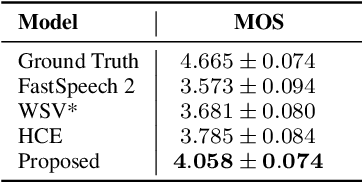
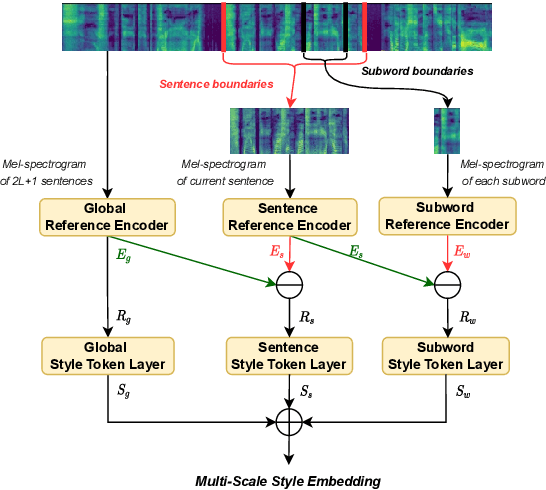
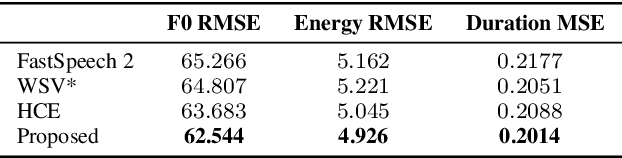
Previous works on expressive speech synthesis focus on modelling the mono-scale style embedding from the current sentence or context, but the multi-scale nature of speaking style in human speech is neglected. In this paper, we propose a multi-scale speaking style modelling method to capture and predict multi-scale speaking style for improving the naturalness and expressiveness of synthetic speech. A multi-scale extractor is proposed to extract speaking style embeddings at three different levels from the ground-truth speech, and explicitly guide the training of a multi-scale style predictor based on hierarchical context information. Both objective and subjective evaluations on a Mandarin audiobooks dataset demonstrate that our proposed method can significantly improve the naturalness and expressiveness of the synthesized speech.
Pseudo Supervised Solar Panel Mapping based on Deep Convolutional Networks with Label Correction Strategy in Aerial Images
Mar 16, 2021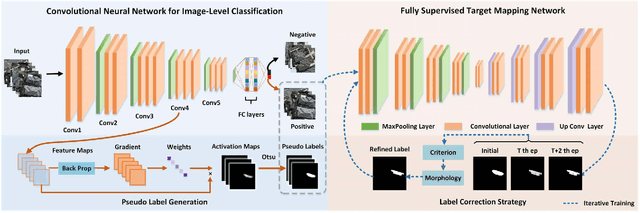


Solar panel mapping has gained a rising interest in renewable energy field with the aid of remote sensing imagery. Significant previous work is based on fully supervised learning with classical classifiers or convolutional neural networks (CNNs), which often require manual annotations of pixel-wise ground-truth to provide accurate supervision. Weakly supervised methods can accept image-wise annotations which can help reduce the cost for pixel-level labelling. Inevitable performance gap, however, exists between weakly and fully supervised methods in mapping accuracy. To address this problem, we propose a pseudo supervised deep convolutional network with label correction strategy (PS-CNNLC) for solar panels mapping. It combines the benefits of both weak and strong supervision to provide accurate solar panel extraction. First, a convolutional neural network is trained with positive and negative samples with image-level labels. It is then used to automatically identify more positive samples from randomly selected unlabeled images. The feature maps of the positive samples are further processed by gradient-weighted class activation mapping to generate initial mapping results, which are taken as initial pseudo labels as they are generally coarse and incomplete. A progressive label correction strategy is designed to refine the initial pseudo labels and train an end-to-end target mapping network iteratively, thereby improving the model reliability. Comprehensive evaluations and ablation study conducted validate the superiority of the proposed PS-CNNLC.
Online Structured Sparsity-based Moving Object Detection from Satellite Videos
Dec 10, 2019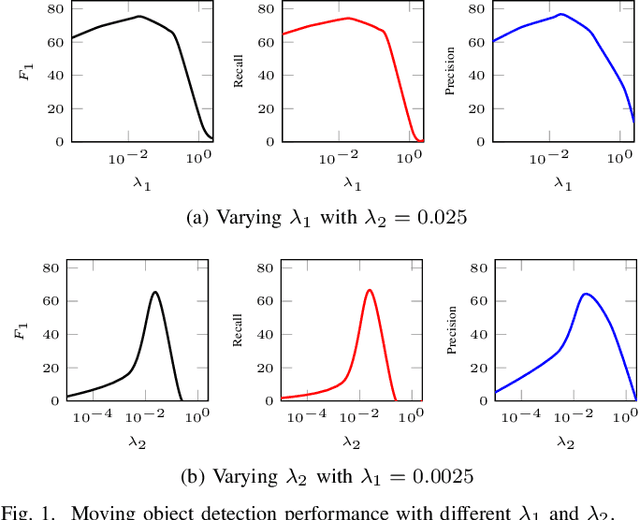
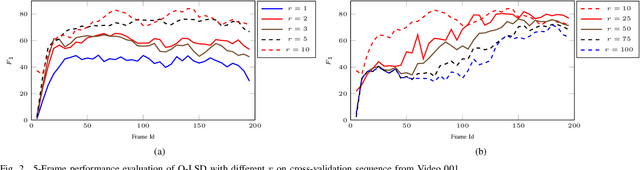
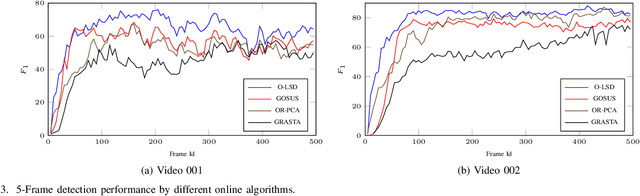
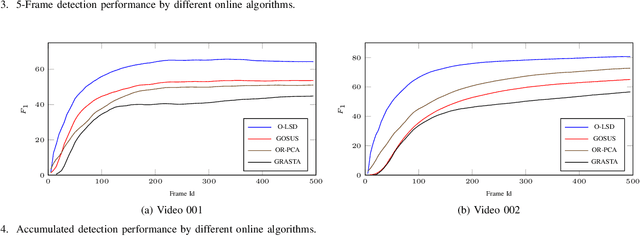
Inspired by the recent developments in computer vision, low-rank and structured sparse matrix decomposition can be potentially be used for extract moving objects in satellite videos. This set of approaches seeks for rank minimization on the background that typically requires batch-based optimization over a sequence of frames, which causes delays in processing and limits their applications. To remedy this delay, we propose an Online Low-rank and Structured Sparse Decomposition (O-LSD). O-LSD reformulates the batch-based low-rank matrix decomposition with the structured sparse penalty to its equivalent frame-wise separable counterpart, which then defines a stochastic optimization problem for online subspace basis estimation. In order to promote online processing, O-LSD conducts the foreground and background separation and the subspace basis update alternatingly for every frame in a video. We also show the convergence of O-LSD theoretically. Experimental results on two satellite videos demonstrate the performance of O-LSD in term of accuracy and time consumption is comparable with the batch-based approaches with significantly reduced delay in processing.
Error Bounded Foreground and Background Modeling for Moving Object Detection in Satellite Videos
Aug 26, 2019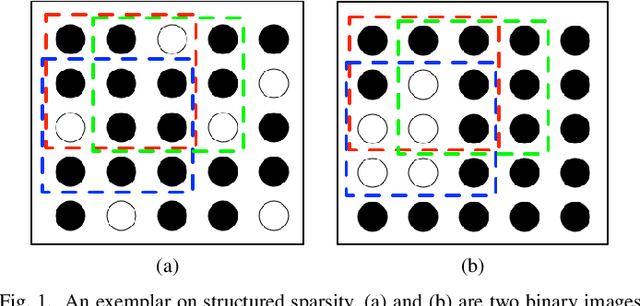
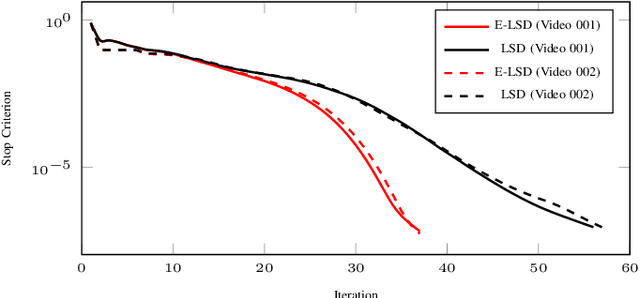


Detecting moving objects from ground-based videos is commonly achieved by using background subtraction techniques. Low-rank matrix decomposition inspires a set of state-of-the-art approaches for this task. It is integrated with structured sparsity regularization to achieve background subtraction in the developed method of Low-rank and Structured Sparse Decomposition (LSD). However, when this method is applied to satellite videos where spatial resolution is poor and targets' contrast to the background is low, its performance is limited as the data no longer fits adequately either the foreground structure or the background model. In this paper, we handle these unexplained data explicitly and address the moving target detection from space as one of the pioneer studies. We propose a technique by extending the decomposition formulation with bounded errors, named Extended Low-rank and Structured Sparse Decomposition (E-LSD). This formulation integrates low-rank background, structured sparse foreground and their residuals in a matrix decomposition problem. We provide an effective solution by introducing an alternative treatment and adopting the direct extension of Alternating Direction Method of Multipliers (ADMM). The proposed E-LSD was validated on two satellite videos, and experimental results demonstrate the improvement in background modeling with boosted moving object detection precision over state-of-the-art methods.
From Deep to Shallow: Transformations of Deep Rectifier Networks
Mar 30, 2017In this paper, we introduce transformations of deep rectifier networks, enabling the conversion of deep rectifier networks into shallow rectifier networks. We subsequently prove that any rectifier net of any depth can be represented by a maximum of a number of functions that can be realized by a shallow network with a single hidden layer. The transformations of both deep rectifier nets and deep residual nets are conducted to demonstrate the advantages of the residual nets over the conventional neural nets and the advantages of the deep neural nets over the shallow neural nets. In summary, for two rectifier nets with different depths but with same total number of hidden units, the corresponding single hidden layer representation of the deeper net is much more complex than the corresponding single hidden representation of the shallower net. Similarly, for a residual net and a conventional rectifier net with the same structure except for the skip connections in the residual net, the corresponding single hidden layer representation of the residual net is much more complex than the corresponding single hidden layer representation of the conventional net.