 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDesc3D: Towards Layout-Aware 3D Indoor Scene Generation from Short Descriptions
Apr 02, 20263D indoor scene generation conditioned on short textual descriptions provides a promising avenue for interactive 3D environment construction without the need for labor-intensive layout specification. Despite recent progress in text-conditioned 3D scene generation, existing works suffer from poor physical plausibility and insufficient detail richness in such semantic condensation cases, largely due to their reliance on explicit semantic cues about compositional objects and their spatial relationships. This limitation highlights the need for enhanced 3D reasoning capabilities, particularly in terms of prior integration and spatial anchoring.Motivated by this, we propose SDesc3D, a short-text conditioned 3D indoor scene generation framework, that leverages multi-view structural priors and regional functionality implications to enable 3D layout reasoning under sparse textual guidance.Specifically, we introduce a Multi-view scene prior augmentation that enriches underspecified textual inputs with aggregated multi-view structural knowledge, shifting from inaccessible semantic relation cues to multi-view relational prior aggregation. Building on this, we design a Functionality-aware layout grounding, employing regional functionality grounding for implicit spatial anchors and conducting hierarchical layout reasoning to enhance scene organization and semantic plausibility.Furthermore, an Iterative reflection-rectification scheme is employed for progressive structural plausibility refinement via self-rectification.Extensive experiments show that our method outperforms existing approaches on short-text conditioned 3D indoor scene generation.Code will be publicly available.
Decouple and Rectify: Semantics-Preserving Structural Enhancement for Open-Vocabulary Remote Sensing Segmentation
Apr 02, 2026Open-vocabulary semantic segmentation in the remote sensing (RS) field requires both language-aligned recognition and fine-grained spatial delineation. Although CLIP offers robust semantic generalization, its global-aligned visual representations inherently struggle to capture structural details. Recent methods attempt to compensate for this by introducing RS-pretrained DINO features. However, these methods treat CLIP representations as a monolithic semantic space and cannot localize where structural enhancement is required, failing to effectively delineate boundaries while risking the disruption of CLIP's semantic integrity. To address this limitation, we propose DR-Seg, a novel decouple-and-rectify framework in this paper. Our method is motivated by the key observation that CLIP feature channels exhibit distinct functional heterogeneity rather than forming a uniform semantic space. Building on this insight, DR-Seg decouples CLIP features into semantics-dominated and structure-dominated subspaces, enabling targeted structural enhancement by DINO without distorting language-aligned semantics. Subsequently, a prior-driven graph rectification module injects high-fidelity structural priors under DINO guidance to form a refined branch, while an uncertainty-guided adaptive fusion module dynamically integrates this refined branch with the original CLIP branch for final prediction. Comprehensive experiments across eight benchmarks demonstrate that DR-Seg establishes a new state-of-the-art.
Resonance4D: Frequency-Domain Motion Supervision for Preset-Free Physical Parameter Learning in 4D Dynamic Physical Scene Simulation
Apr 02, 2026Physics-driven 4D dynamic simulation from static 3D scenes remains constrained by an overlooked contradiction: reliable motion supervision often relies on online video diffusion or optical-flow pipelines whose computational cost exceeds that of the simulator itself. Existing methods further simplify inverse physical modeling by optimizing only partial material parameters, limiting realism in scenes with complex materials and dynamics. We present Resonance4D, a physics-driven 4D dynamic simulation framework that couples 3D Gaussian Splatting with the Material Point Method through lightweight yet physically expressive supervision. Our key insight is that dynamic consistency can be enforced without dense temporal generation by jointly constraining motion in complementary domains. To this end, we introduce Dual-domain Motion Supervision (DMS), which combines spatial structural consistency for local deformation with frequency-domain spectral consistency for oscillatory and global dynamic patterns, substantially reducing training cost and memory overhead while preserving physically meaningful motion cues. To enable stable full-parameter physical recovery, we further combine zero-shot text-prompted segmentation with simulation-guided initialization to automatically decompose Gaussians into object-part-level regions and support joint optimization of full material parameters. Experiments on both synthetic and real scenes show that Resonance4D achieves strong physical fidelity and motion consistency while reducing peak GPU memory from over 35\,GB to around 20\,GB, enabling high-fidelity physics-driven 4D simulation on a single consumer-grade GPU.
Explore Intrinsic Geometry for Query-based Tiny and Oriented Object Detector with Momentum-based Bipartite Matching
Feb 14, 2026Recent query-based detectors have achieved remarkable progress, yet their performance remains constrained when handling objects with arbitrary orientations, especially for tiny objects capturing limited texture information. This limitation primarily stems from the underutilization of intrinsic geometry during pixel-based feature decoding and the occurrence of inter-stage matching inconsistency caused by stage-wise bipartite matching. To tackle these challenges, we present IGOFormer, a novel query-based oriented object detector that explicitly integrates intrinsic geometry into feature decoding and enhances inter-stage matching stability. Specifically, we design an Intrinsic Geometry-aware Decoder, which enhances the object-related features conditioned on an object query by injecting complementary geometric embeddings extrapolated from their correlations to capture the geometric layout of the object, thereby offering a critical geometric insight into its orientation. Meanwhile, a Momentum-based Bipartite Matching scheme is developed to adaptively aggregate historical matching costs by formulating an exponential moving average with query-specific smoothing factors, effectively preventing conflicting supervisory signals arising from inter-stage matching inconsistency. Extensive experiments and ablation studies demonstrate the superiority of our IGOFormer for aerial oriented object detection, achieving an AP$_{50}$ score of 78.00\% on DOTA-V1.0 using Swin-T backbone under the single-scale setting. The code will be made publicly available.
Towards the Three-Phase Dynamics of Generalization Power of a DNN
May 11, 2025This paper proposes a new perspective for analyzing the generalization power of deep neural networks (DNNs), i.e., directly disentangling and analyzing the dynamics of generalizable and non-generalizable interaction encoded by a DNN through the training process. Specifically, this work builds upon the recent theoretical achievement in explainble AI, which proves that the detailed inference logic of DNNs can be can be strictly rewritten as a small number of AND-OR interaction patterns. Based on this, we propose an efficient method to quantify the generalization power of each interaction, and we discover a distinct three-phase dynamics of the generalization power of interactions during training. In particular, the early phase of training typically removes noisy and non-generalizable interactions and learns simple and generalizable ones. The second and the third phases tend to capture increasingly complex interactions that are harder to generalize. Experimental results verify that the learning of non-generalizable interactions is the the direct cause for the gap between the training and testing losses.
Randomness of Low-Layer Parameters Determines Confusing Samples in Terms of Interaction Representations of a DNN
Feb 12, 2025In this paper, we find that the complexity of interactions encoded by a deep neural network (DNN) can explain its generalization power. We also discover that the confusing samples of a DNN, which are represented by non-generalizable interactions, are determined by its low-layer parameters. In comparison, other factors, such as high-layer parameters and network architecture, have much less impact on the composition of confusing samples. Two DNNs with different low-layer parameters usually have fully different sets of confusing samples, even though they have similar performance. This finding extends the understanding of the lottery ticket hypothesis, and well explains distinctive representation power of different DNNs.
Towards the Dynamics of a DNN Learning Symbolic Interactions
Jul 27, 2024This study proves the two-phase dynamics of a deep neural network (DNN) learning interactions. Despite the long disappointing view of the faithfulness of post-hoc explanation of a DNN, in recent years, a series of theorems have been proven to show that given an input sample, a small number of interactions between input variables can be considered as primitive inference patterns, which can faithfully represent every detailed inference logic of the DNN on this sample. Particularly, it has been observed that various DNNs all learn interactions of different complexities with two-phase dynamics, and this well explains how a DNN's generalization power changes from under-fitting to over-fitting. Therefore, in this study, we prove the dynamics of a DNN gradually encoding interactions of different complexities, which provides a theoretically grounded mechanism for the over-fitting of a DNN. Experiments show that our theory well predicts the real learning dynamics of various DNNs on different tasks.
Two-Phase Dynamics of Interactions Explains the Starting Point of a DNN Learning Over-Fitted Features
May 16, 2024This paper investigates the dynamics of a deep neural network (DNN) learning interactions. Previous studies have discovered and mathematically proven that given each input sample, a well-trained DNN usually only encodes a small number of interactions (non-linear relationships) between input variables in the sample. A series of theorems have been derived to prove that we can consider the DNN's inference equivalent to using these interactions as primitive patterns for inference. In this paper, we discover the DNN learns interactions in two phases. The first phase mainly penalizes interactions of medium and high orders, and the second phase mainly learns interactions of gradually increasing orders. We can consider the two-phase phenomenon as the starting point of a DNN learning over-fitted features. Such a phenomenon has been widely shared by DNNs with various architectures trained for different tasks. Therefore, the discovery of the two-phase dynamics provides a detailed mechanism for how a DNN gradually learns different inference patterns (interactions). In particular, we have also verified the claim that high-order interactions have weaker generalization power than low-order interactions. Thus, the discovered two-phase dynamics also explains how the generalization power of a DNN changes during the training process.
SA-MixNet: Structure-aware Mixup and Invariance Learning for Scribble-supervised Road Extraction in Remote Sensing Images
Mar 03, 2024Mainstreamed weakly supervised road extractors rely on highly confident pseudo-labels propagated from scribbles, and their performance often degrades gradually as the image scenes tend various. We argue that such degradation is due to the poor model's invariance to scenes with different complexities, whereas existing solutions to this problem are commonly based on crafted priors that cannot be derived from scribbles. To eliminate the reliance on such priors, we propose a novel Structure-aware Mixup and Invariance Learning framework (SA-MixNet) for weakly supervised road extraction that improves the model invariance in a data-driven manner. Specifically, we design a structure-aware Mixup scheme to paste road regions from one image onto another for creating an image scene with increased complexity while preserving the road's structural integrity. Then an invariance regularization is imposed on the predictions of constructed and origin images to minimize their conflicts, which thus forces the model to behave consistently on various scenes. Moreover, a discriminator-based regularization is designed for enhancing the connectivity meanwhile preserving the structure of roads. Combining these designs, our framework demonstrates superior performance on the DeepGlobe, Wuhan, and Massachusetts datasets outperforming the state-of-the-art techniques by 1.47%, 2.12%, 4.09% respectively in IoU metrics, and showing its potential of plug-and-play. The code will be made publicly available.
Knowledge Distillation for Oriented Object Detection on Aerial Images
Jun 20, 2022
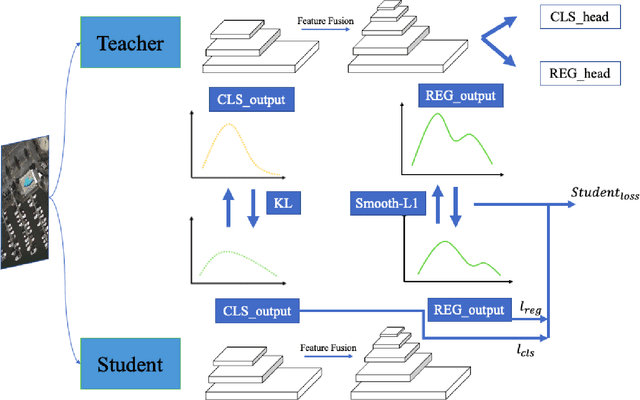
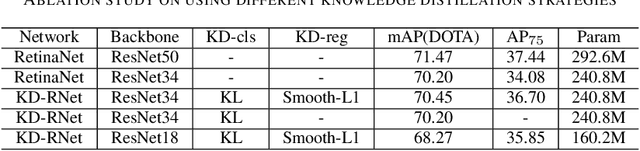
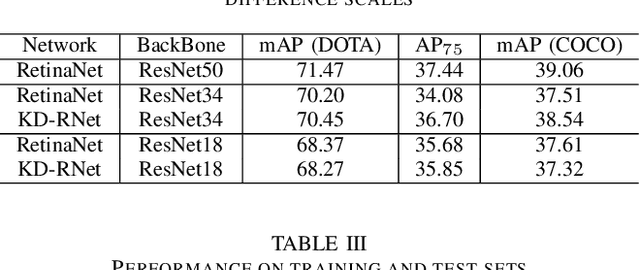
Deep convolutional neural network with increased number of parameters has achieved improved precision in task of object detection on natural images, where objects of interests are annotated with horizontal boundary boxes. On aerial images captured from the bird-view perspective, these improvements on model architecture and deeper convolutional layers can also boost the performance on oriented object detection task. However, it is hard to directly apply those state-of-the-art object detectors on the devices with limited computation resources, which necessitates lightweight models through model compression. In order to address this issue, we present a model compression method for rotated object detection on aerial images by knowledge distillation, namely KD-RNet. With a well-trained teacher oriented object detector with a large number of parameters, the obtained object category and location information are both transferred to a compact student network in KD-RNet by collaborative training strategy. Transferring the category information is achieved by knowledge distillation on predicted probability distribution, and a soft regression loss is adopted for handling displacement in location information transfer. The experimental result on a large-scale aerial object detection dataset (DOTA) demonstrates that the proposed KD-RNet model can achieve improved mean-average precision (mAP) with reduced number of parameters, at the same time, KD-RNet boost the performance on providing high quality detections with higher overlap with groundtruth annotations.