 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIG-Nav: Key Insights for Pretrained Image Goal Navigation Models
Jul 23, 2025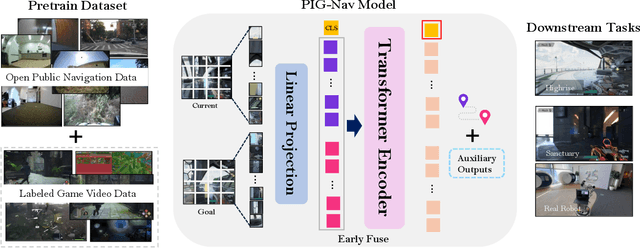
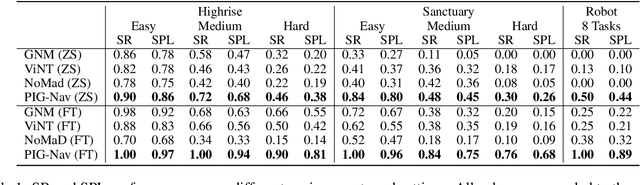
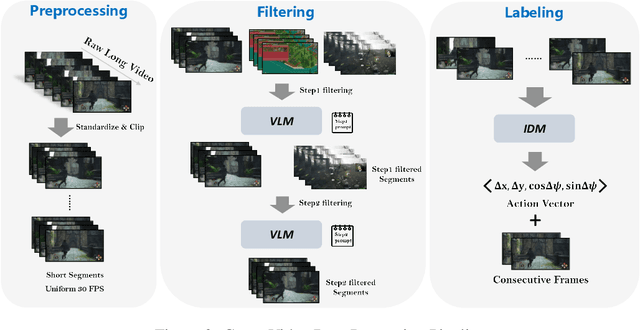
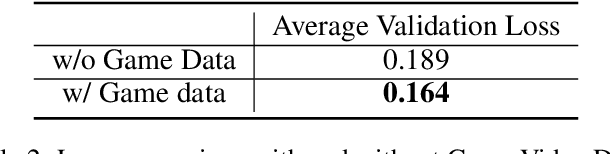
Recent studies have explored pretrained (foundation) models for vision-based robotic navigation, aiming to achieve generalizable navigation and positive transfer across diverse environments while enhancing zero-shot performance in unseen settings. In this work, we introduce PIG-Nav (Pretrained Image-Goal Navigation), a new approach that further investigates pretraining strategies for vision-based navigation models and contributes in two key areas. Model-wise, we identify two critical design choices that consistently improve the performance of pretrained navigation models: (1) integrating an early-fusion network structure to combine visual observations and goal images via appropriately pretrained Vision Transformer (ViT) image encoder, and (2) introducing suitable auxiliary tasks to enhance global navigation representation learning, thus further improving navigation performance. Dataset-wise, we propose a novel data preprocessing pipeline for efficiently labeling large-scale game video datasets for navigation model training. We demonstrate that augmenting existing open navigation datasets with diverse gameplay videos improves model performance. Our model achieves an average improvement of 22.6% in zero-shot settings and a 37.5% improvement in fine-tuning settings over existing visual navigation foundation models in two complex simulated environments and one real-world environment. These results advance the state-of-the-art in pretrained image-goal navigation models. Notably, our model maintains competitive performance while requiring significantly less fine-tuning data, highlighting its potential for real-world deployment with minimal labeled supervision.
A Robust Policy Bootstrapping Algorithm for Multi-objective Reinforcement Learning in Non-stationary Environments
Aug 18, 2023



Multi-objective Markov decision processes are a special kind of multi-objective optimization problem that involves sequential decision making while satisfying the Markov property of stochastic processes. Multi-objective reinforcement learning methods address this problem by fusing the reinforcement learning paradigm with multi-objective optimization techniques. One major drawback of these methods is the lack of adaptability to non-stationary dynamics in the environment. This is because they adopt optimization procedures that assume stationarity to evolve a coverage set of policies that can solve the problem. This paper introduces a developmental optimization approach that can evolve the policy coverage set while exploring the preference space over the defined objectives in an online manner. We propose a novel multi-objective reinforcement learning algorithm that can robustly evolve a convex coverage set of policies in an online manner in non-stationary environments. We compare the proposed algorithm with two state-of-the-art multi-objective reinforcement learning algorithms in stationary and non-stationary environments. Results showed that the proposed algorithm significantly outperforms the existing algorithms in non-stationary environments while achieving comparable results in stationary environments.
Intrinsically Motivated Hierarchical Policy Learning in Multi-objective Markov Decision Processes
Aug 18, 2023



Multi-objective Markov decision processes are sequential decision-making problems that involve multiple conflicting reward functions that cannot be optimized simultaneously without a compromise. This type of problems cannot be solved by a single optimal policy as in the conventional case. Alternatively, multi-objective reinforcement learning methods evolve a coverage set of optimal policies that can satisfy all possible preferences in solving the problem. However, many of these methods cannot generalize their coverage sets to work in non-stationary environments. In these environments, the parameters of the state transition and reward distribution vary over time. This limitation results in significant performance degradation for the evolved policy sets. In order to overcome this limitation, there is a need to learn a generic skill set that can bootstrap the evolution of the policy coverage set for each shift in the environment dynamics therefore, it can facilitate a continuous learning process. In this work, intrinsically motivated reinforcement learning has been successfully deployed to evolve generic skill sets for learning hierarchical policies to solve multi-objective Markov decision processes. We propose a novel dual-phase intrinsically motivated reinforcement learning method to address this limitation. In the first phase, a generic set of skills is learned. While in the second phase, this set is used to bootstrap policy coverage sets for each shift in the environment dynamics. We show experimentally that the proposed method significantly outperforms state-of-the-art multi-objective reinforcement methods in a dynamic robotics environment.
Preference-conditioned Pixel-based AI Agent For Game Testing
Aug 18, 2023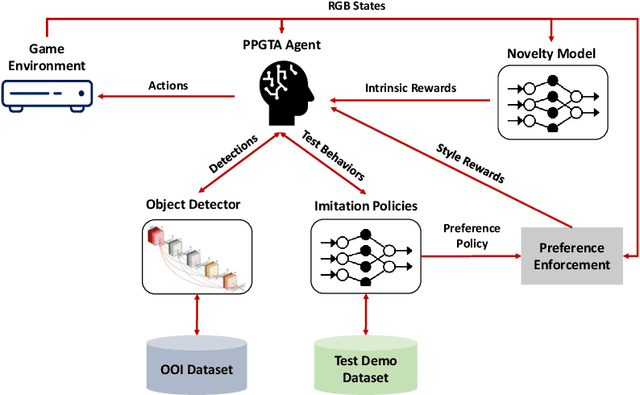
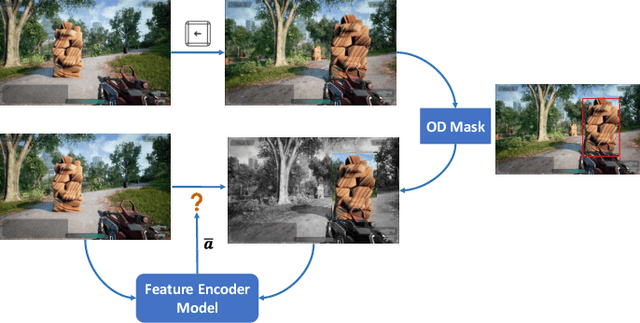
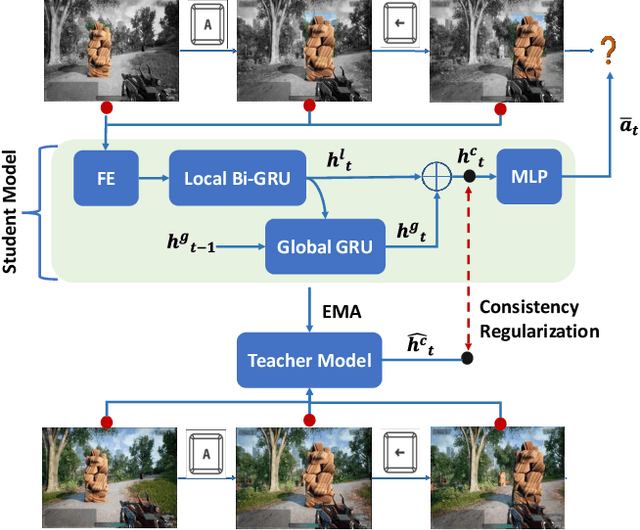
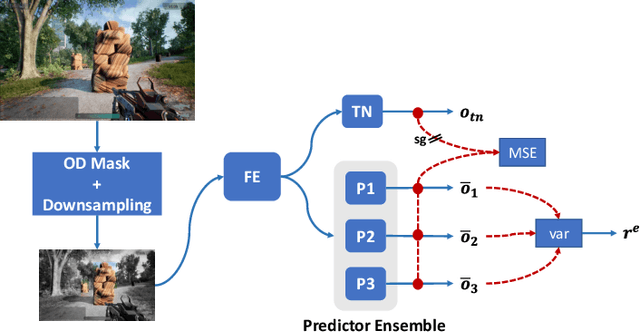
The game industry is challenged to cope with increasing growth in demand and game complexity while maintaining acceptable quality standards for released games. Classic approaches solely depending on human efforts for quality assurance and game testing do not scale effectively in terms of time and cost. Game-testing AI agents that learn by interaction with the environment have the potential to mitigate these challenges with good scalability properties on time and costs. However, most recent work in this direction depends on game state information for the agent's state representation, which limits generalization across different game scenarios. Moreover, game test engineers usually prefer exploring a game in a specific style, such as exploring the golden path. However, current game testing AI agents do not provide an explicit way to satisfy such a preference. This paper addresses these limitations by proposing an agent design that mainly depends on pixel-based state observations while exploring the environment conditioned on a user's preference specified by demonstration trajectories. In addition, we propose an imitation learning method that couples self-supervised and supervised learning objectives to enhance the quality of imitation behaviors. Our agent significantly outperforms state-of-the-art pixel-based game testing agents over exploration coverage and test execution quality when evaluated on a complex open-world environment resembling many aspects of real AAA games.
DBE-KT22: A Knowledge Tracing Dataset Based on Online Student Evaluation
Aug 19, 2022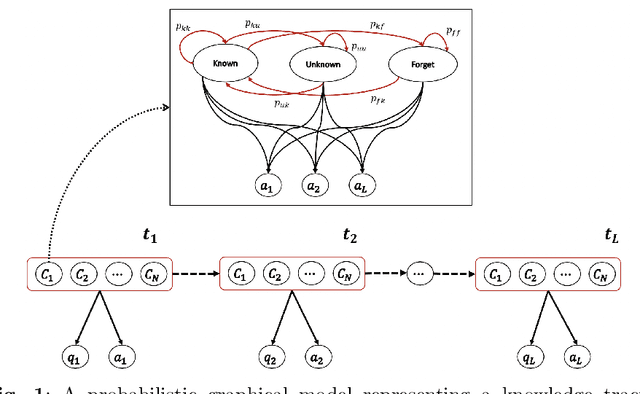
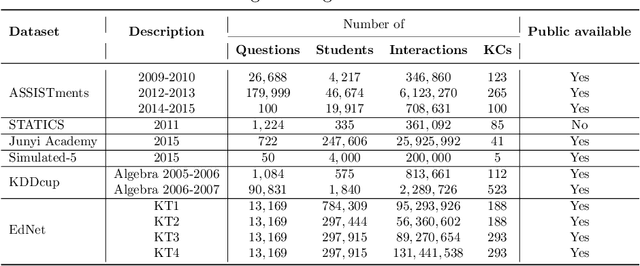

Online education has gained an increasing importance over the last decade for providing affordable high-quality education to students worldwide. This has been further magnified during the global pandemic as more students switched to study online. The majority of online education tasks, e.g., course recommendation, exercise recommendation, or automated evaluation, depends on tracking students' knowledge progress. This is known as the \emph{Knowledge Tracing} problem in the literature. Addressing this problem requires collecting student evaluation data that can reflect their knowledge evolution over time. In this paper, we propose a new knowledge tracing dataset named Database Exercises for Knowledge Tracing (DBE-KT22) that is collected from an online student exercise system in a course taught at the Australian National University in Australia. We discuss the characteristics of the DBE-KT22 dataset and contrast it with the existing datasets in the knowledge tracing literature. Our dataset is available for public access through the Australian Data Archive platform.