 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgevilla-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
Jul 31, 2025Visual-Language-Action (VLA) models have emerged as a popular paradigm for learning robot manipulation policies that can follow language instructions and generalize to novel scenarios. Recent work has begun to explore the incorporation of latent actions, an abstract representation of visual change between two frames, into VLA pre-training. In this paper, we introduce villa-X, a novel Visual-Language-Latent-Action (ViLLA) framework that advances latent action modeling for learning generalizable robot manipulation policies. Our approach improves both how latent actions are learned and how they are incorporated into VLA pre-training. Together, these contributions enable villa-X to achieve superior performance across simulated environments including SIMPLER and LIBERO, as well as on two real-world robot setups including gripper and dexterous hand manipulation. We believe the ViLLA paradigm holds significant promise, and that our villa-X provides a strong foundation for future research.
PIG-Nav: Key Insights for Pretrained Image Goal Navigation Models
Jul 23, 2025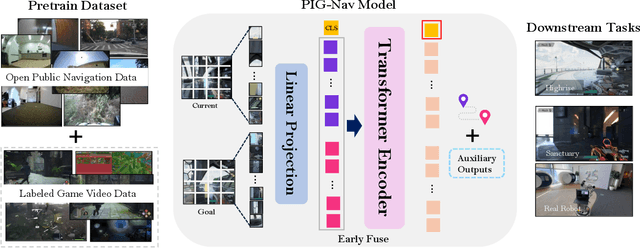
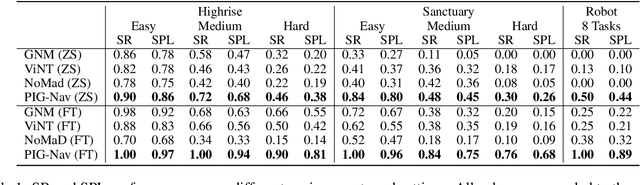
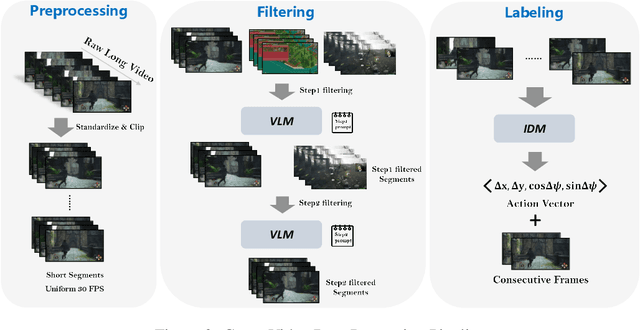
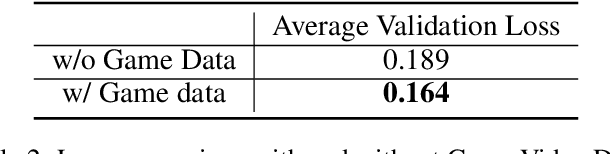
Recent studies have explored pretrained (foundation) models for vision-based robotic navigation, aiming to achieve generalizable navigation and positive transfer across diverse environments while enhancing zero-shot performance in unseen settings. In this work, we introduce PIG-Nav (Pretrained Image-Goal Navigation), a new approach that further investigates pretraining strategies for vision-based navigation models and contributes in two key areas. Model-wise, we identify two critical design choices that consistently improve the performance of pretrained navigation models: (1) integrating an early-fusion network structure to combine visual observations and goal images via appropriately pretrained Vision Transformer (ViT) image encoder, and (2) introducing suitable auxiliary tasks to enhance global navigation representation learning, thus further improving navigation performance. Dataset-wise, we propose a novel data preprocessing pipeline for efficiently labeling large-scale game video datasets for navigation model training. We demonstrate that augmenting existing open navigation datasets with diverse gameplay videos improves model performance. Our model achieves an average improvement of 22.6% in zero-shot settings and a 37.5% improvement in fine-tuning settings over existing visual navigation foundation models in two complex simulated environments and one real-world environment. These results advance the state-of-the-art in pretrained image-goal navigation models. Notably, our model maintains competitive performance while requiring significantly less fine-tuning data, highlighting its potential for real-world deployment with minimal labeled supervision.
Preference-conditioned Pixel-based AI Agent For Game Testing
Aug 18, 2023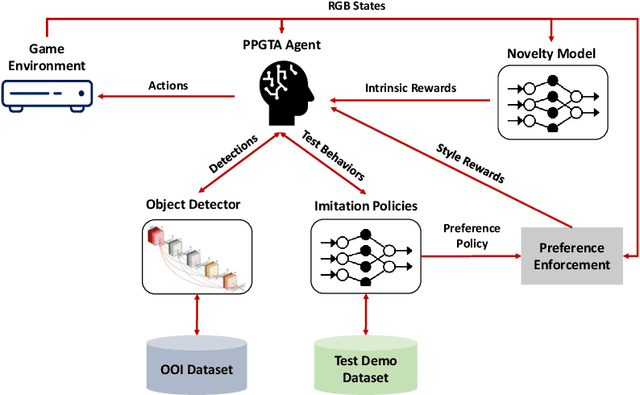
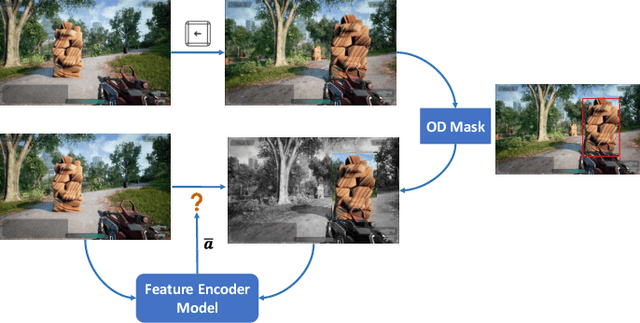
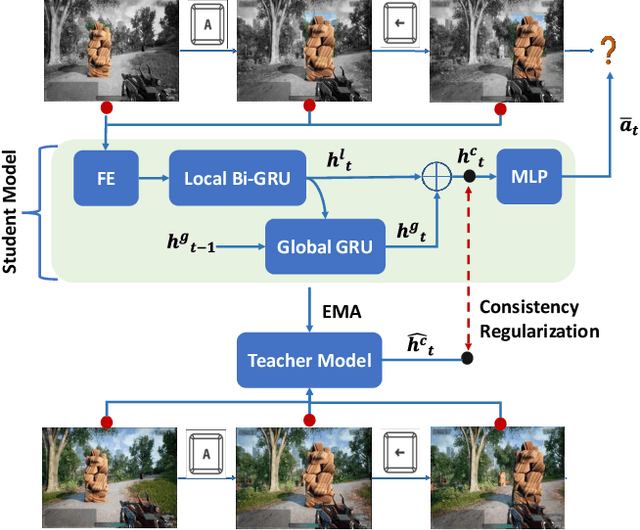
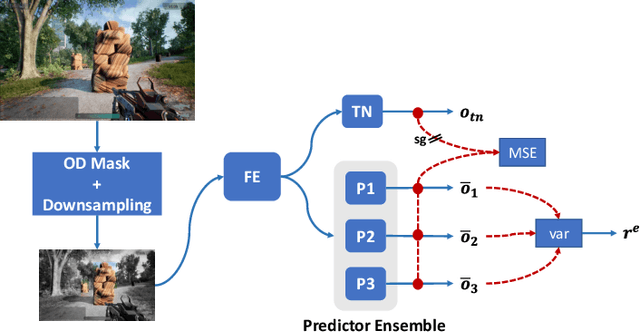
The game industry is challenged to cope with increasing growth in demand and game complexity while maintaining acceptable quality standards for released games. Classic approaches solely depending on human efforts for quality assurance and game testing do not scale effectively in terms of time and cost. Game-testing AI agents that learn by interaction with the environment have the potential to mitigate these challenges with good scalability properties on time and costs. However, most recent work in this direction depends on game state information for the agent's state representation, which limits generalization across different game scenarios. Moreover, game test engineers usually prefer exploring a game in a specific style, such as exploring the golden path. However, current game testing AI agents do not provide an explicit way to satisfy such a preference. This paper addresses these limitations by proposing an agent design that mainly depends on pixel-based state observations while exploring the environment conditioned on a user's preference specified by demonstration trajectories. In addition, we propose an imitation learning method that couples self-supervised and supervised learning objectives to enhance the quality of imitation behaviors. Our agent significantly outperforms state-of-the-art pixel-based game testing agents over exploration coverage and test execution quality when evaluated on a complex open-world environment resembling many aspects of real AAA games.
Asking Before Action: Gather Information in Embodied Decision Making with Language Models
May 25, 2023With strong capabilities of reasoning and a generic understanding of the world, Large Language Models (LLMs) have shown great potential in building versatile embodied decision making agents capable of performing diverse tasks. However, when deployed to unfamiliar environments, we show that LLM agents face challenges in efficiently gathering necessary information, leading to suboptimal performance. On the other hand, in unfamiliar scenarios, human individuals often seek additional information from their peers before taking action, leveraging external knowledge to avoid unnecessary trial and error. Building upon this intuition, we propose \textit{Asking Before Action} (ABA), a method that empowers the agent to proactively query external sources for pertinent information using natural language during their interactions in the environment. In this way, the agent is able to enhance its efficiency and performance by mitigating wasteful steps and circumventing the difficulties associated with exploration in unfamiliar environments. We empirically evaluate our method on an embodied decision making benchmark, ALFWorld, and demonstrate that despite modest modifications in prompts, our method exceeds baseline LLM agents by more than $40$%. Further experiments on two variants of ALFWorld illustrate that by imitation learning, ABA effectively retains and reuses queried and known information in subsequent tasks, mitigating the need for repetitive inquiries. Both qualitative and quantitative results exhibit remarkable performance on tasks that previous methods struggle to solve.
An Adaptive Deep RL Method for Non-Stationary Environments with Piecewise Stable Context
Dec 24, 2022One of the key challenges in deploying RL to real-world applications is to adapt to variations of unknown environment contexts, such as changing terrains in robotic tasks and fluctuated bandwidth in congestion control. Existing works on adaptation to unknown environment contexts either assume the contexts are the same for the whole episode or assume the context variables are Markovian. However, in many real-world applications, the environment context usually stays stable for a stochastic period and then changes in an abrupt and unpredictable manner within an episode, resulting in a segment structure, which existing works fail to address. To leverage the segment structure of piecewise stable context in real-world applications, in this paper, we propose a \textit{\textbf{Se}gmented \textbf{C}ontext \textbf{B}elief \textbf{A}ugmented \textbf{D}eep~(SeCBAD)} RL method. Our method can jointly infer the belief distribution over latent context with the posterior over segment length and perform more accurate belief context inference with observed data within the current context segment. The inferred belief context can be leveraged to augment the state, leading to a policy that can adapt to abrupt variations in context. We demonstrate empirically that SeCBAD can infer context segment length accurately and outperform existing methods on a toy grid world environment and Mujuco tasks with piecewise-stable context.
Distributional Reinforcement Learning for Multi-Dimensional Reward Functions
Oct 26, 2021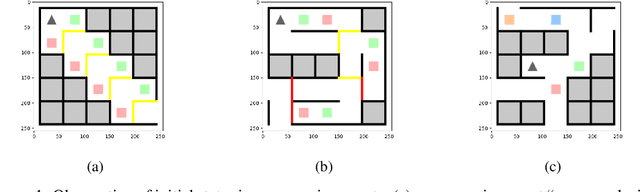
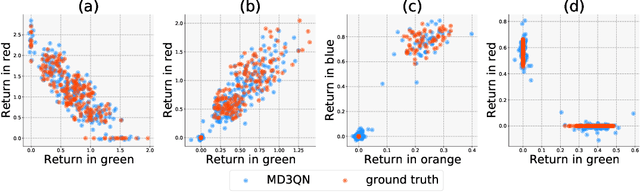
A growing trend for value-based reinforcement learning (RL) algorithms is to capture more information than scalar value functions in the value network. One of the most well-known methods in this branch is distributional RL, which models return distribution instead of scalar value. In another line of work, hybrid reward architectures (HRA) in RL have studied to model source-specific value functions for each source of reward, which is also shown to be beneficial in performance. To fully inherit the benefits of distributional RL and hybrid reward architectures, we introduce Multi-Dimensional Distributional DQN (MD3QN), which extends distributional RL to model the joint return distribution from multiple reward sources. As a by-product of joint distribution modeling, MD3QN can capture not only the randomness in returns for each source of reward, but also the rich reward correlation between the randomness of different sources. We prove the convergence for the joint distributional Bellman operator and build our empirical algorithm by minimizing the Maximum Mean Discrepancy between joint return distribution and its Bellman target. In experiments, our method accurately models the joint return distribution in environments with richly correlated reward functions, and outperforms previous RL methods utilizing multi-dimensional reward functions in the control setting.